申请评分卡的构建
主要流程:
(1)探索性数据分析;
(2)通过IV、PSI等指标以及逐步回归对入模变量进行筛选,并结合业务经验对剔除变量进行剔除原因分析;
(3)基于Logistic算法进行建模,利用Xgboost算法建模进行模型效果比较,正向和逆向调用模型检验样本分布;
(4)观察指标评估模型效果;
(5)合并数据,重新训练模型,生成评分卡。
一、业务背景
基于申请客户的各项信息,对其违约概率进行预测。
二、数据介绍
数据维度概况
除了uid唯一标识,共12个维度,95806行。
数据12个维度介绍:
bad_ind:好坏标签,1代表bad,0代表good
person_info:用户相关的信息,身份特质
finance_info:财务相关的信息,履约能力
credit_info:信用相关的信息,信用历史
act_info:行为信息,行为偏好
score结尾:其他信用机构的评分
身份特质: 稳定性,所在公司,职业类型,消费稳定度,近一年内使用手机号码数,手机号码稳定天数,地址稳定天数。
履约能力:是否有车,是否有房,近一个月流动资产日均值,近三个月流动资产日均值,近六个月流动资产日均值,近一年流动资产日均值,近一个月理财产品总收益,近三个月理财产品总收益,近六个月理财产品总收益,近一年理财产品总收益,历史理财产品总收益,近一个月支付总金额,近三个月支付总金额,近六个月支付总金额,近一个月消费总金额,近三个月消费总金额,近六个月消费总金额。
信用历史:近一个月主动查询金融机构次数,近三个月主动查询金融机构数,近六个月主动查询金融机构数,近一个月信贷类还款总金额,近三个月信贷类还款总金额,近六个月信贷类还款总金额,近一年信贷类还款总金额,近一年信贷类还款月份数,近一年M1状态,近一年M3状态,近一年M6状态,近两年M1状态,近两年M3状态,近两年M6状态,近五年M1状态,近五年M3状态,近五年M6状态。
行为偏好:消费区域个数,近一年支付活跃场景数,近一年母婴消费总金额,近一年母婴消费总笔数,近一年游戏消费总金额,近一年游戏消费总笔数,近三个月家居建材消费总金额,进三个月家具建材消费总笔数,近一年汽车消费总金额,近一年汽车消费总笔数,近一年航旅度假消费总金额,近一年航旅度假消费总笔数。
三、建模过程
(1)导入库,加载数据
import pandas as pd
from sklearn.metrics import roc_auc_score,roc_curve,auc
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
import numpy as np
import math
import xgboost as xgb
import toad
# 加载数据
data_all = pd.read_csv("scorecard.txt")
(2)观察数据

数据集已经提前划分好了并打上标签,dev代表开发样本,val代表验证样本,off代表时间外样本,这里的开发样本和验证样本是使用分层抽样进行划分的,主要是为了保证两个数据集中的bad样本占比相同,而时间外样本则是选取最近一个月的数据集。
这里数据集划分为三类的原因主要在于信贷场景的特殊性,预测模型的本质是基于历史数据预测未来,因而在检验模型的效能时,应该用最接近模型应用时间点,最接近实际的样本,以检验模型的跨时间稳定性。
好坏客户分布情况

(3)指定初步入模变量,划分数据集
# 指定不参与训练列名
ex_lis = ['uid', 'samp_type', 'bad_ind']
# 参与训练列名
ft_lis = list(data_all.columns)
for i in ex_lis:
ft_lis.remove(i)
# 开发样本、验证样本与时间外样本
dev = data_all[(data_all['samp_type'] == 'dev')]
val = data_all[(data_all['samp_type'] == 'val') ]
off = data_all[(data_all['samp_type'] == 'off') ]
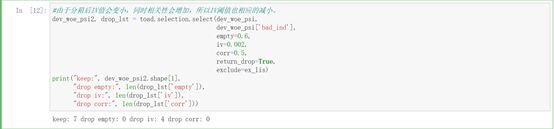
(4)变量粗筛选
dev_slct1, drop_lst= toad.selection.select(dev, dev['bad_ind'],
empty=0.7, iv=0.03,
corr=0.7,
return_drop=True,
exclude=ex_lis)
print(drop_lst)
print("keep:", dev_slct1.shape[1],
"drop empty:", len(drop_lst['empty']),
"drop iv:", len(drop_lst['iv']),
"drop corr:", len(drop_lst['corr']))

这部分主要是通过一些限定数值来进行特征筛选,但指标设置的比较宽松,属于一个粗筛查。
得到的结果为筛选后的数据集和哪些变量因为哪些原因被筛选出去了。
这里一共13个变量,没有变量因为缺失率高于0.7被删除,有一个变量’rh_score’因为iv值低于0.03被删除,没有变量因为相关性过高被删除。
(5)数据分箱(卡方分箱)


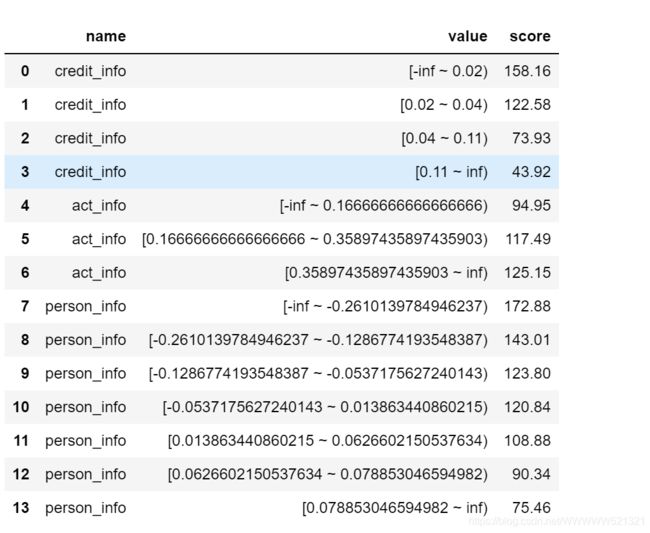
根据act_info进行分箱,8个切分点,分9箱。
dev:

柱形图上的数字为每箱的频率,折线上的数字为每箱的bad占比。:
频率:0.24、0.06、0.06、0.10、0.16、0.12、0.05、0.14、0.07
Bad占比:0.02、0.02、0.02、0.02、0.01、0.01、0.01、0.01、0.01
这里说明一下,折线图上的数字是取的两位小数,所以折线图上的数字和折线图看起来会有些矛盾。
val
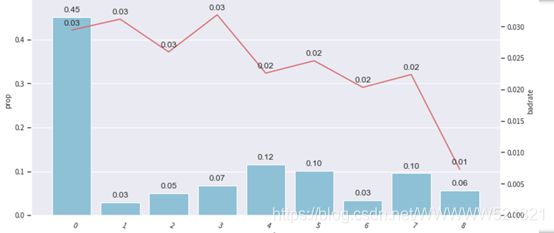
频率:0.45、0.03、0.05、0.07、0.12、0.10、0.03、0.10、0.06
Bad占比:0.03、0.03、0.03、0.03、0.02、0.02、0.02、0.02、0.01
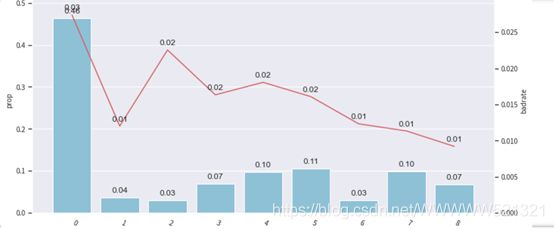
频率:0.46、0.04、0.03、0.07、0.10、0.11、0.03、0.10、0.07
Bad占比:0.03、0.01、0.02、0.02、0.02、0.02、0.01、0.01、0.01
(5)分箱调整
由上述三图可知,分箱后的badrate并不随箱体编号增加而呈现单调趋势,所以我们要调整箱体,使其呈现单调趋势,分箱调整主要是为了构建一个有排序能力的模型。
我们这里做的是手动调整,把1到3箱,4到6箱,7到9箱进行合并。
所以只需要两个切分点,即第三个切分点0.16666666666666666,第6个切分点0.35897435897435903
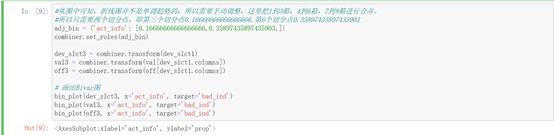
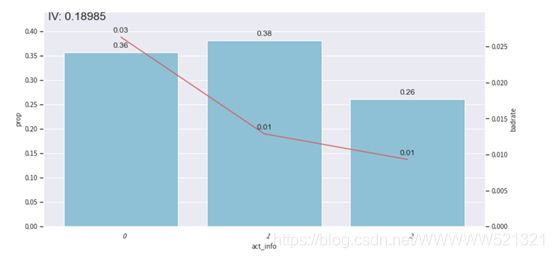
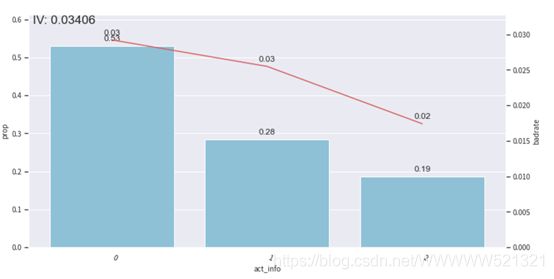
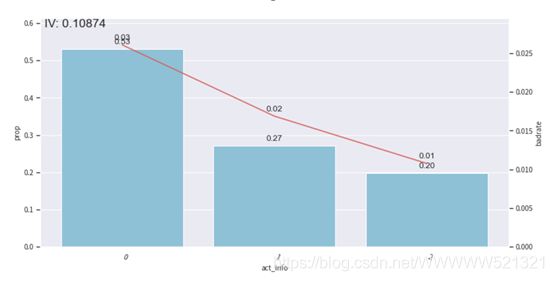
分箱后呈现了单调趋势。
(6)利用PSI筛选分布不一致的特征
该处做特征分布筛选,主要是根据dev、val、off三个样本的特征分布是否一致来筛选,当我们的特征在不同数据集上保持相同分布时,可以有效的减少模型的泛化误差,防止过拟合,这里选取的指标是PSI。
WOE编码:

计算PSI,并且把PSI大于0.13的特征删除:
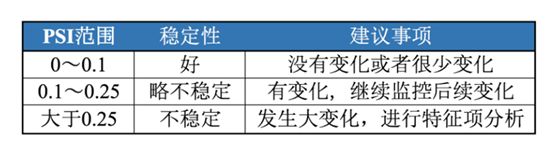

由结果可知,通过PSI进行筛选后,还剩下11个变量,剩下的变量为:
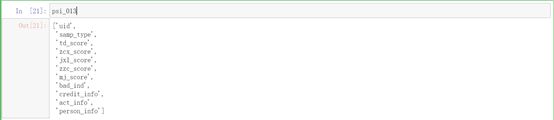
剔除掉的变量为:finance_info
(7)进一步筛查变量
由于分箱后IV值会变小,同时相关性会增加,所以IV阈值也相应的减小
一般来说,IV阈值设置如下:

通过IV筛选后,还剩下7个变量,剩下的变量为:

被剔除的变量为:td_score、jxl_score、zzc_score、mj_score
再进一步使用逐步回归做特征筛选,该处使用的是线性回归模型,并选择AIC作为筛选指标。
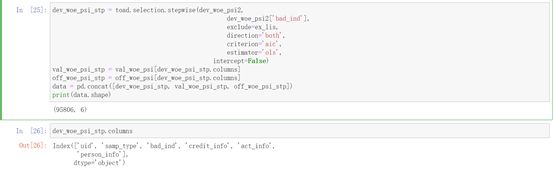
最终还剩下6个变量,其中特征变量为:
Credit_info、act_info、person_info
被剔除的变量为:zcx_score
(8)变量剔除原因分析
接下来我们对被剔除的变量进行分析,主要是从IV、PSI、AIC三个角度来分析:
IV:
从上述结果可知,rh_score、td_score、jxl_score、zzc_score、mj_score因为IV值过低而被剔除,接下来我主要从IV值本身的含义和变量特性来分析这些变量被IV值筛选剔除的原因。
IV值含义:从贝叶斯先验的角度来说,当我们手上什么信息都没有的时候,让我们去判断一个客户是否违约,我们只能随机去判断,也就是以0.5的概率去判断。但是,当我们所获得信息不断增多时,比如现在我们掌握该客户的芝麻信用分,一个400分的客户,与一个700分的客户,前者违约的概率明显更高,这种对我们区分客户,判断客户的信息越多,我们判断的把握就越大,对客户的区分度就越大,这种变量所带来的信息价值,也就是IV越大,该变量就越应该放入到模型之中。
变量特性:前面说到,一个变量蕴含的信息价值越大,这个变量就越应该放入到模型之中,但有时候,我们拿到手的变量即使含有特别大的信息价值,但如果不经过一些特殊的处理就无法使用,有时候甚至不如不用,这里的score类变量就是一个典型例子。
前面说过,这里的score类变量是其他机构的信用评分,我们知道,市面上的贷款机构其实是良莠不齐的,并不是所有机构都像蚂蚁金服一样,其给出的信用评分质量非常高,甚至可以直接拿来进行信用评估,还有些机构,比如P2P、拍拍贷,还有些极端的714高炮贷款,其风控流程、bad定义、产品逻辑,产品时间线千差万别,要想使用这些score,必须经过一些标准化的处理,比如统一bad定义,数据口径等。

我们看下前5个客户在不同机构的评分,会发现很难统一,客户在A机构评分高,但在B机构评分又低。
综上所述,一个变量拿到手,要么信息价值不高,要么难以使用,这两者都会造成变量的IV值较低。
PSI:
被PSI指标剔除的变量为finance_info,PSI主要是判断变量在各箱体上的分布是否一致,因为预测模型的本质就是基于历史样本去预测未来样本,其前提就是样本分布接近甚至一致。
AIC:AIC=2K-2ln(L),AIC值描述的是模型复杂度K与模型对数据集描述能力ln(L)(即似然函数)之间的一个平衡,当我们的模型拟合度ln(L)提升时,模型的复杂度K也必然提升,我们对模型的要求是提升拟合度的同时,模型的复杂度又不能太高,所以目标是尽量选择AIC较小的值。
(9)定义逻辑回归函数

(10)定义xgboost函数
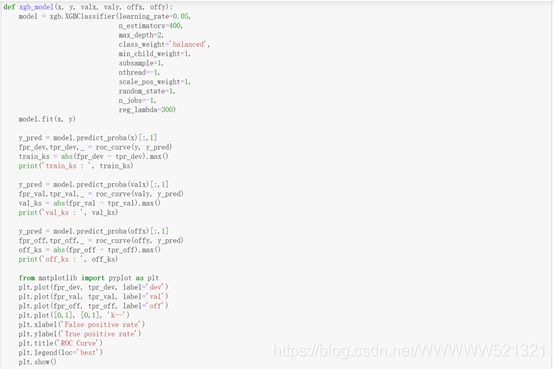
这里定义xgboost函数,主要是为了检验当前所用的一些特征是否有必要进行特征组合,再经过分箱和WOE编码后,如果xgboost模型的效果仍然高于逻辑回归函数,那么就认为现有的特征有必要进行特征组合。
(11)定义函数调用上述模型

这里xgboost和逻辑回归函数各调用两次,分为正向调用和逆向调用,其差异在于,正向调用通过开发样本拟合模型,逆向调用通过时间外样本拟合模型,如果两者KS值差别较大,则认为时间外样本和开发样本差异过大,需要重新拟合模型。
(12)模型训练结果展示与评价
逻辑回归正向:
train_ks : 0.41733648227995124
val_ks : 0.3593935758405114
off_ks : 0.3758086175640308

逻辑回归逆向:
train_ks : 0.3892612859630226
val_ks : 0.3717891855920369
off_ks : 0.4061965880072622
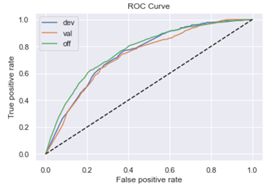
XGBoost正向:
train_ks : 0.42521927400747045
val_ks : 0.3595542266920359
off_ks : 0.37437103192850807
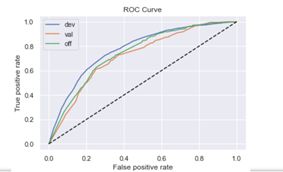
XGBoost逆向
train_ks : 0.3939473708822855
val_ks : 0.3799497614606668
off_ks : 0.3936270948436908
通过模型结果可以看出,xgboost模型的结果并没有显著好于逻辑回归,因此不需要再进行特征组合。此外,不管是逻辑回归还是xgboost,逆向调用结果也没有显著好于正向调用的结果。最后,在逻辑回归正向调用中,train KS与off KS的差距在5%内,说明模型的跨时间稳定性也较好。
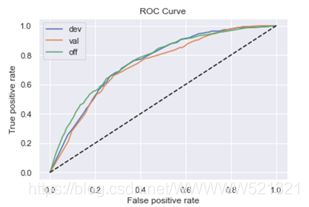
(13)最终预测效果
接下来用逻辑回归模型进行违约预测。
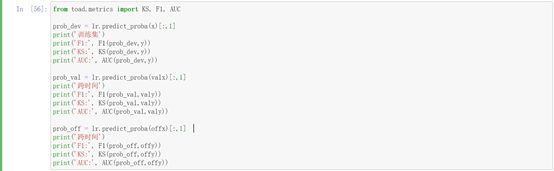
训练集
F1: 0.02962459026532253
KS: 0.41406129833591426
AUC: 0.7713247123864264
跨时间
F1: 0.027689429373246022
KS: 0.36127808343721585
AUC: 0.7225727568398459
跨时间
F1: 0.032454090150250414
KS: 0.3807135163445966
AUC: 0.7435613582904539
![]()
模型PSI: 0.3368608703962184
特征PSI:
credit_info 0.098585
act_info 0.124820
person_info 0.127833
dtype: float64
(14)评分卡构建
from toad.scorecard import ScoreCard
card = ScoreCard(combiner=combiner,
transer=t, C=0.1,
class_weight='balanced',
base_score=600,
base_odds=35,
pdo=60,
rate=2)
card.fit(x,y)
final_card = card.export(to_frame=True)
final_card