自动(智能)驾驶系列| 插播 深挖自动驾驶数据集
写在前面:
最近因为新项目的事情,到外地出差,没有太多时间更新深感抱歉~后续有时间会继续更新的!之前使用数据可能掌握数据的格式和特性放到网络中即可(是darknet格式的么等等),本文不是对如何使用数据集的说明,而是对于数据集为什么有效,他们的硬件方案是什么呢,为什么用这样的方案呢?如果你对自动驾驶感兴趣,经过一步步的深入学习最后来到了自己需要设计一个方案来搭载你的设备完成某些任务时,如何快速入手?抑或是没有设备但是想投入研究工作(甚至可以投身于数据集打榜),公开数据集是一个很好的切入点。本文是从几个经典的自动驾驶数据集出发,去体会设计者的思路和方案,注意:本文不侧重于数据集的使用和网络结构的内容。自动驾驶的数据集发布了不少了,例如Kitti、奥迪、Apollo、Udacity等等。本文则主要会涉及到KITTI、nuScenes、Waymo、WoodScape以及车路协同数据集DAIR-V2X。
-----------------------------------------------------------------------------------------------------------------------
目录
1.KITTI数据集(2012)
2.nuScenes数据集(2019)
3.Waymo数据集(2019)
4.WoodScape数据集(2020)
5.DAIR-V2X数据集(2021)
首先在这里强调在使用和下载数据集时,非常推荐大家先去下载并阅读数据集的论文、官网或者Github说明,这对我们深入理解和应用数据集十分关键。
1.KITTI数据集(2012)
官网:The KITTI Vision Benchmark Suite
论文原文:Vision meets Robotics: The KITTI Dataset
KITTI是非常老牌的自动驾驶数据集了(最早2012~2013制作的),我们来阅读一下其论文看看有什么发现:
首先,对于其传感器布局我们可以看出其传感器的布局方案:
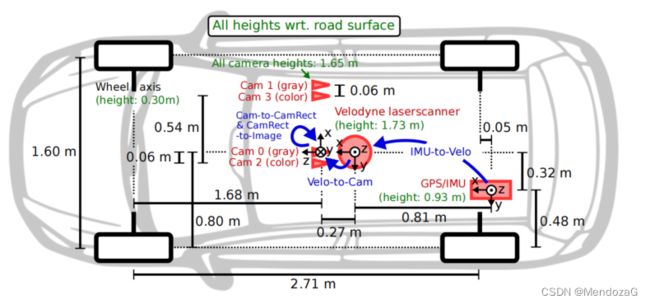
Sensor Setup:

以及

我们可以看出他们的方案主要采用了:相机140万像素,采用的是索尼ICS267 CCD的底,采用的快门方式是global shutter(全局快门)。采用的是两个灰度相机和两个彩色相机。镜头则采用了4个Edmund 的4mm 水平AFOV 大约90度,竖直方向(ROI) AFOV约为35度(这两个数值都是可以根据镜头焦距和相机属性来计算的),从图上可以看出他们将相机分为两组去使用(文中也解释了为什么要两个一起使用,那是因为因为工业相机的Bayer模型需要插值得到最后的彩色数据会损失一定的感光(例如RGGB格式的Bayer插值得到RGB每个感光需要滤光所以总的光线浪费掉了)),彩色+灰度相机为一组组成双目摄像头组。激光雷达则采用当时非常昂贵的激光雷达老大哥Velodyne64线机械式激光雷达,安装在汽车顶部,帧率为10Hz。组合惯导采用的是OXTS RT3003(英国公司的产品)并且使用了RTK服务(L1,L2级别)。工控机(PC)采用的是一台六核的Intel XEON X5650处理器以及4T的储存。操作系统是Ubuntu,数据流通过实时的database来储存和管理。
当然啦,这是很早的配置,但是对于想在线下搭建平台的朋友可以参考其结构设计等方面,是具有一定启发意义的。
从文中还可以发现,本数据集主要采集地点是欧洲,所以如果你照搬Kitti数据集中的数据训练自己的模型在中国实测会发现效果并不好。(例如Kitti中有几个项目例如有轨电车、拖车等等我们这边其实也是比较少见的)。下载过Kitti数据集的同学应该会发现,其图像格式是png格式的。对于惯导而言,每帧储存了30个包括俯仰角海拔等等不同的值,采用了两个不同的坐标系即车体坐标系以及全球的地球坐标系。
在标定方面,对于同步:他们采用了以激光雷达的时间戳作为参考的时间,并把每次旋转设为核心帧(10Hz,旋转一圈为1frame),触发相机的形式为安装了一个簧片旋转到前向位置时触发相机。IMU/GPS数据匹配直接采用最近邻时间戳匹配,运行在100Hz,最坏的误差为5ms。相机标定分为内参和外参标定,文档中他们给出了每日的标定数据(也就是每天开机前他们都做了标定以保证准确性)并完成了pinhole相机的畸变矫正。激光雷达和IMU标定采用的是基于欧式距离优化的方法,通过经典的开车“画八字”使用ICP算法手眼标定来得到两者的RT外参关系。
最后我们来看看数据分布:
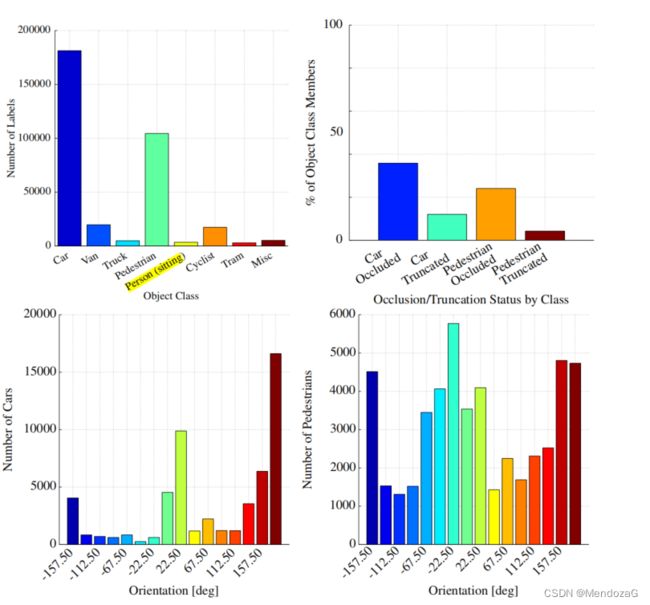
可以看出对于人和truck等样本的labels太少了,这会带来一些问题。值得注意的是Kitti数据集中有一个项目为 Don't Care,代表的是激光雷达无法观测到但是会出现在图像中的目标。
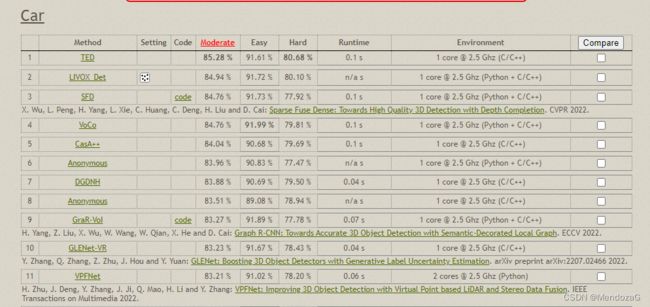
打榜:可以看到目前Kitti的打榜依然活跃,通过打榜获取相关研究的论文也是我们学习前沿技术的一个重要途径!(下图为3D目标检测的榜单)
2.nuScenes数据集(2019)
官网:https://nuscenes.org/
论文:(来自IEEE)nuScenes: A Multimodal Dataset for Autonomous Driving | IEEE Conference Publication | IEEE Xplore

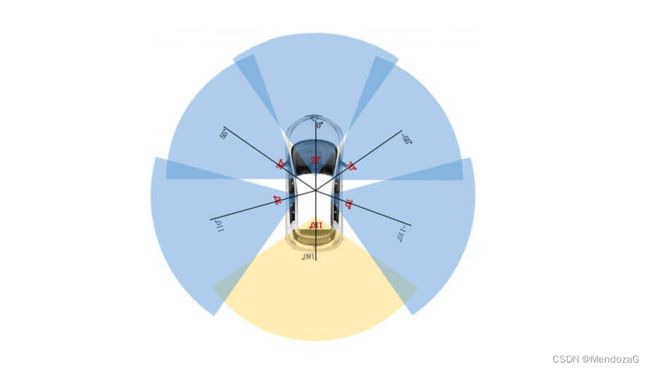
nuScenes数据集发表于2019年,是一个较为新的数据集。传感器相较于Kitti加入了雷达(radar),配置包括6个相机,5个雷达,1个激光雷达(覆盖360的视场)。其提供了1000个场景,每个场景20s,提供23类8属性的数据,可以看上图。文中提到激光雷达测距范围50~150m,雷达可以达到200~300米并通过多普勒效应提供目标速度信息。并且,他发布时是收个所有sensor都组成360度FoV的传感器组(5个radar、6相机排布覆盖360度视场),详细的传感器配置方案在论文中没有标出,我们可以进入到官网:

传感器具体配置见下图:

激光雷达采用的是威力登的32E,工作帧率20Hz,相机则采用了德国老牌Basler工业相机(acA1600-60gc,目前售价四千多一颗可以上官网找到这颗相机Basler ace acA1600-60gc (CS-Mount) - 面阵相机)12Hz(相机自身最高支持60帧,文中还用了13和20Hz),按照他图中画的5个70度FOV的,1个110度的(配置未知)。70度fov的镜头Evetar的F1.8 f5.5mm 1/1.8(对应sensor的尺寸),200万像素,是CMOS器件(目前主流)采用自动曝光但限制在20ms以内(避免运动模糊),数据储存则是压缩为JPEG输出(大大减少储存写入的数据流)。安装形式则是55度的offset安装70度FOV的相机(同样可以根据sensor和镜头计算),后视(rear)则采用110度(区间也刚好是110度和周围两个相机有重叠区域);5个雷达,经典的大陆408(Continental ARS 408-21)77GHz,工作帧率13Hz,从手册(具体的可以看下面的图片)可以看出可以达到正负60度的视场,安装5块是一个经典安装方法。组合惯导采用的是Spatial(Spatial | Miniature GNSS/INS | Advanced Navigation)目前售价2900刀,具体参数可以看官网。

文中给出了和其他数据集的对比,可以看出它的优势,并且我们也可以注意到其他在中国收集的数据集(红色框),值得一提的是对于不同场景,他提供了夜晚及雨天的场景这是非常有意义的。

在同步方面,其采用的策略是:当顶部激光雷达穿过相应相机视场是触发并将相片的名称命名为曝光时刻的时间戳(没有采用二分之一曝光时间所以推测可能使用了Basler的全局快门模式)。激光雷达则是整圈完成(1个frame)的时间打上时间戳。由于在城市场景的应用遮挡明显,对于GPS来说影响较大,他们通过离线用激光雷达构建HD map来使得结果更加准确(辅助定位),定位误差小于10cm。他们还做了人工语义标注的地图以协助轨迹预测。
数据标注上,对关键帧以2Hz采样(也就是一秒钟选取2“张”),标注了23个类别,标注框采用的格式为中心点加长宽高加yaw。
评价指标方面,使用AP指标但是没有使用IOU,而是采用2D的中心欧式距离来判断,目的是为了对小物体友好(对小物体检测我们常使用很小的IOU),所以本文还提出了一组评价指标感兴趣的可以看文章,这里不再展开了(下图可以看出CD法的效果)。
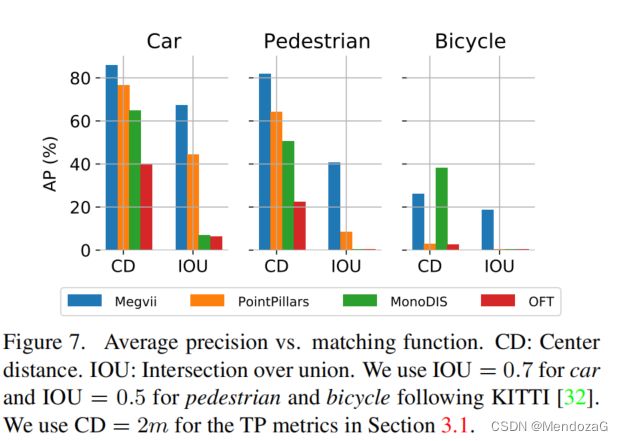
BaseLine评估,对于仅仅用激光雷达点云,用PointPillars;仅仅用image,采用OFT(Orthographic Fearture Transform),并使用SSD 的检测头,使用NMS结合6个相机360度视场的图像。
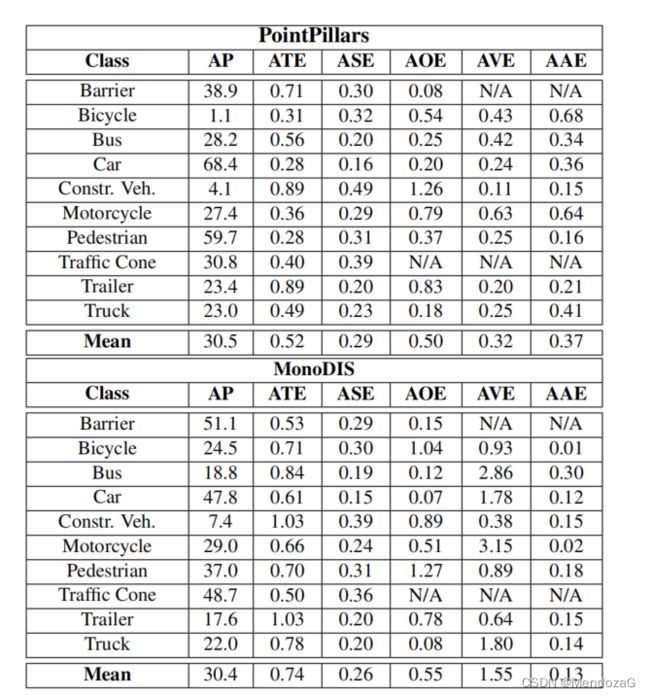
很有意思的是,他们分开独立的去评价不同传感器的指标,那么在自动驾驶中谁(可能)有更好的效果呢(单一种传感器360fov比较)?结果如下,当然啦只是用简单的1stage评估方法评估:
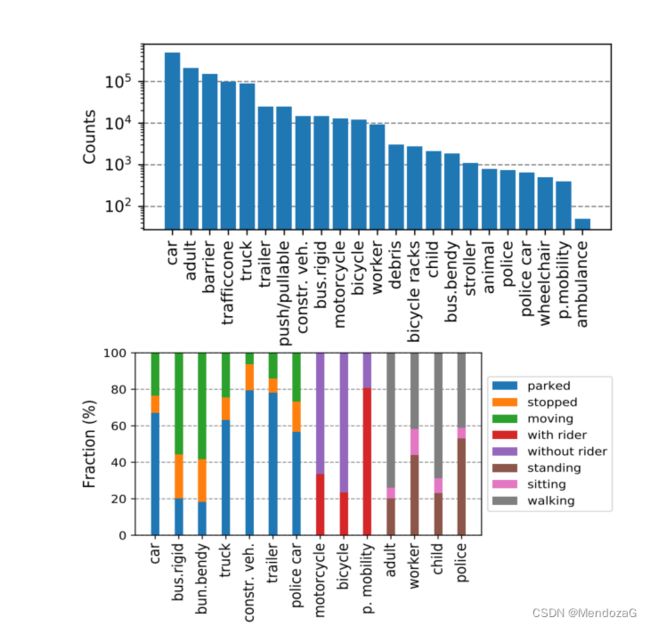
下图是标注的数据分布,似乎看起来比Kitti均衡了不少,但是注意左边的单位是10的次方级别,实际上是更大数量级的关系。下面的是统计不同种类的运动状态,可以发现car很多情况都是停着的,bus则大多都在运动中,行人状态则大多是行走中。
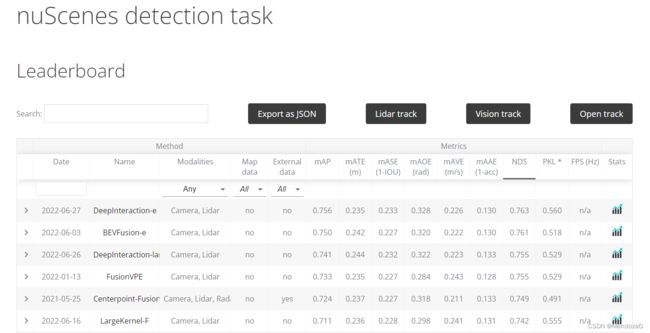
同样该数据集也是有打榜的,例如detection 任务:
其他的还有很多有意思的细节,比如各个传感器测距范围效果、标定方法等等,推荐大家深挖一下原文,这个数据集就暂且说到这。
-------------------------------------------------------------------------------------------------------------------------
--吐槽一句,本来几近完稿,接近万字,奈何稿件丢失了(恢复内容中也未找到),考虑后还是打算继续更完,这倒也提醒了我应该多注意backup。

---------------------------------------------------------------------------------------------------------------------------
3.Waymo数据集(2019)
官网: waymo数据集官网 (可能需要魔法)
论文原文:Scalability in Perception for Autonomous Driving: Waymo Open Dataset
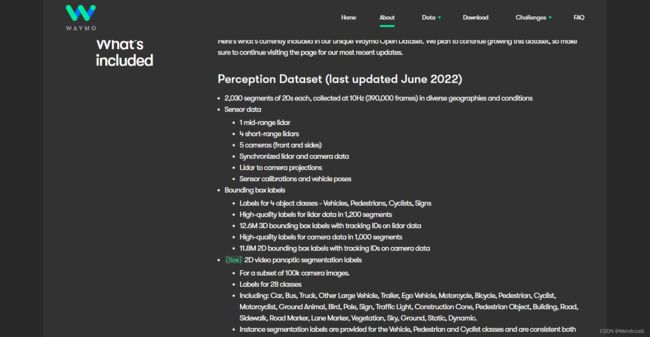
waymo数据集这块上一稿是着重笔墨写的,有很多有意思的地方。waymo众所周知,是谷歌旗下的自动驾驶行业领军者,代表着以激光雷达为核心的派别,而另外一派就是纯视觉方案的代表者特斯拉。Waymo的数据集目前仍然是不断更新的,从上图可以看到上次更新是在6月份,本文的分析并不会建立于最新的数据集而是以论文中的为准。
最初的waymo数据集,有1150场景,每个场景20秒。与之前提到的数据集不同,waymo采用的设备均为自己研发的,分为相机组合激光雷达组。
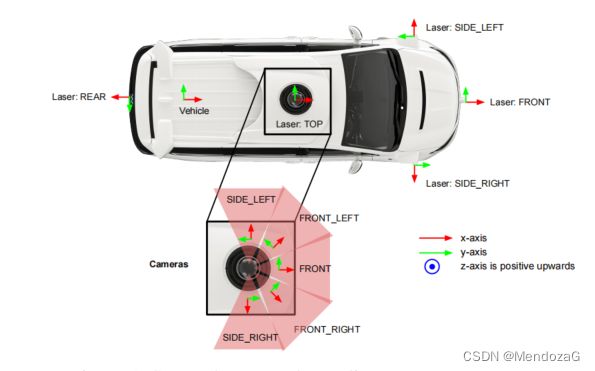
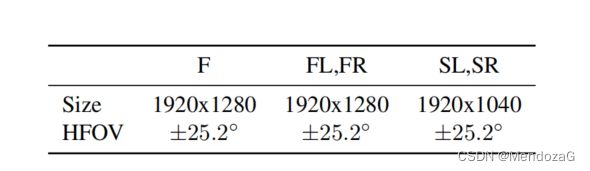
相机组由5台设备组成,五台相机均是线性相机,快门方式为Rolling Shutter(为什么呢?),像素有所差别但都在200万像素左右。水平视场角为正负25.2度(也就是50.4度,五个相机并不能构成360度视场),图上的每个红色三角x正方向(红色箭头)是以45度间隔划分的。图像的采集是对raw图像最终经过下采样和裁剪得到并保存为JPEG格式。
激光雷达则也用了五颗,除了顶部的提供360度视场,其余四颗-90度到30度(垂直视场)这样就起到补盲的作用(可能还可以对不用材质车道线等做检测)。激光雷达最远距离是被限制的,top的75米,补盲的20m,return/shot只取前两次收到的。

上面的图是否不够直观?那我们看看这个图:
正面:

后面:

相机激光雷达组:

关于坐标系这里就不展开了,有车辆的frame、sensor frame,给出4*4矩阵的RT刚体变换。
最值得注意的是,关于传感器数据方面,激光雷达并非给出二进制数据或者点云图,而是编码为 range image,与上面对应提供了 first two returns。range image和rolling shutter的图像很相似,是从左到右一行一行填充的(对应于卷帘快门的逐行曝光),其中每个pixel对应了激光雷达的return,其高和宽取决于激光雷达安装的倾斜角和方位角。“图像”中心代表x正方向(也就是前进方向),第一行(最上方)对应最大的倾斜角,第一列(最左边)对应x负方向(backward方向)。

还记得前面提的问题么?我们都知道rolling shutter是逐行曝光的每一个像素点的曝光时间实际上都是不同的,那为什么不用全局曝光呢?在我们的认知中也许全局曝光的CMOS相机是要贵一些的,那是谷歌差钱吗?大家不妨思考一下~
--------------------------------------------------------------------------------------------------------------------------
除了卷帘快门的性能比如低噪声,以及逐行曝光逐行输出数据流不会一下很大,最重要的就是用在与激光雷达等同步上(例如projection)。还记得前面提到的激光雷达采用的range image格式和rolling shutter类似么?
给定空间一个点p(global frame),由于rolling shutter的模式,其实每个像素点的曝光时间都是不同的,假设其曝光时刻是t(未知),那么我们可以通过优化的方式来求解。我们假定车体在t时刻(时刻很短)以匀速v运动,速度为ω,通过pose可以将空间中的p投影到图像上记作q,从而该像素对应了一个图像中唯一的时间t',我们通过求解关于t的使得t与t'绝对差值最小的凸优化最终可以得到t。这样就能得到精确的激光雷达、图像的projection。另外的如果每一个点都带有时间等信息对于我们做运动补偿来说也是非常有意义的。

接下来再说一下文中有意思的点,对于其相机和激光雷达的同步,按文中说法,同步的准确性按照下式子计算:

其中center_time指的是rolling shutter对应的中间曝光时间,start_time指的是帧数据开始时间,center_offset指的是相机frame的x轴正方向(图中红色的)与backward(后方向)也就是x轴负方向的夹角。0.1s对应的激光雷达10Hz转一圈的时间(也就是1frame的时间)。看完是不是还是有点懵逼?我们把式子改写一下:
![]()

结合这个图你能发现什么?说明数据记录的起始位置就是backward,也就是激光雷达从backward位置旋转开始是一个frame的开始,后面那一项正是激光雷达旋转到相机中心位置的时间,所以这个协同的误差就是曝光时间减去旋转到的时间,换句话说同步的方式就是当激光雷达扫到某位置时对应的相机正好曝光。
关于指标等这里就不再赘述了。感兴趣的可以去看原文。
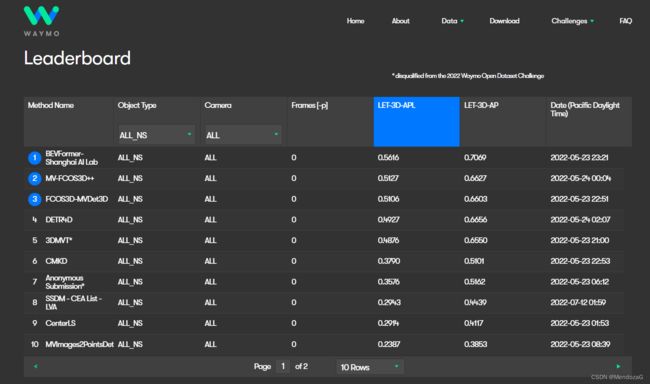
当然waymo数据集仍然是目前非常活跃的打榜数据集,包含了纯视觉等等的榜单,不久前的BEVFormer就在waymo纯视觉方案中拿到了SOTA:
4.WoodScape数据集(2020)
官网:Home
Github:GitHub - valeoai/WoodScape: The repository containing tools and information about the WoodScape dataset.
论文原文:WoodScape: A multi-task, multi-camera fisheye dataset for autonomous driving
WoodScape是法雷奥(Valeo)发布的一个数据集,为什么要说它呢,因为它是第一个鱼眼摄像头的数据集。
鱼眼摄像头在装车时,常常装在后视(rear),由于其FOV很大能达到180度甚至更大,用来补盲等,常常用在拼接360度视场,倒车影像上;同时因为视场太大了,导致其最远的探测距离减少了,很少会有纯鱼眼相机的排布方式,鱼眼相机这样就只适合于低速无人驾驶、配送小车等场景。
鱼眼相机的优势在于用很少的相机数目(例如4个),就可以实现360的环视。WoodScape提供了10000张标注的图像,语义分割40个种类。其相机分布如下:

本数据集的意义在于:鱼眼相机虽然能够用很少的相机数目实现360度环视,但是问题也是显而易见的,畸变严重。那么我们如何处理畸变的图像呢?这里就有两种处理方式,去畸变(undistortion)和模型适配(model adaption)。对于去普通的畸变,我们是没法将大于180度视场(即相机背后的视场)映射到线性视口的,这样会导致视场的丢失,如下图:

另外还有一个问题是,原图边缘的区域可能会重采样为更大的区域;那如果我们不使用直接去畸变的方法,可以用什么方法呢?你肯定能很快想到那我能不能用CNN直接处理未去畸的图像呢(去学习这种畸变模型),想法是很好的,但是鱼眼相机是不具有变换不变性。目前有学者研究了球形图像的模型,但是这个模型不能很好的适配鱼眼相机。所以本数据集开放的一个意义就是让community使用这些图像找到好的处理方法。
数据采集来源于美国、欧洲和中国,主要场景是highway、城镇以及停车场。
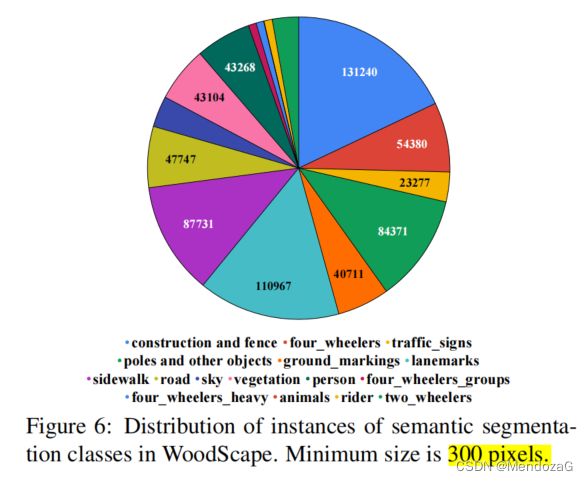
接下来看看他们数据采集的硬件配置:

用了4台100万像素的RGB鱼眼相机,水平FOV为190度(相机自身工作帧率30fps,高动态范围120dB、自动曝光、自动增益等特性);激光雷达采用的是Velodyne的64E,工作帧率20Hz;组合惯导采用的是NoV Atel(诺瓦泰,加拿大公司)的 Propak6(目前高精地图采集商等常用型号为100μ,价格在一百多万人民币);天线雷达组采用的是佳明(Garmin 18X)提供软件平板显示。

下表是一个数据集对比表:
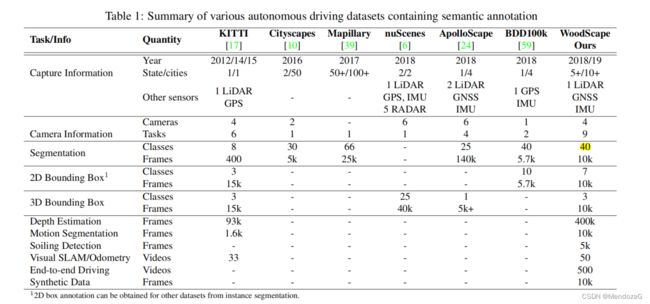
除了上面这些,WoodScape还有一个特性就是多任务,有分割任务,摄像头污损检测等等,具体内容大家可以关注原文。
5.DAIR-V2X数据集(2021)
官网:DAIR-V2X车路协同数据集
Github:GitHub - AIR-THU/DAIR-V2X
论文原文:DAIR-V2X: A Large-Scale Dataset for Vehicle-Infrastructure Cooperative 3D Object Detection
最后来说说DAIR-V2X,它是首个车路协同自动驾驶数据集。由清华大学智能产业研究院(AIR)联合北京市高级别自动驾驶示范区、北京车网科技发展有限公司、百度Apollo、北京智源人工智能研究院共同发布。对于这个数据集推荐阅读官网,有详细的信息!
官网对其介绍如下:

本数据集的意义在于其是第一个真实世界车路协同的车路协同数据集。大家广泛认同对于L5自动驾驶的实现,汽车基础设施的辅助是必须的。

本数据集分为3个,分别是协同端、车端和路端:
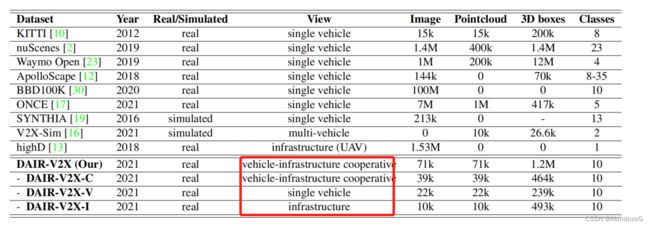
40%的帧是由路端传感器、60%是由车端传感器捕获的。包含了10km城市道路、10km high way。
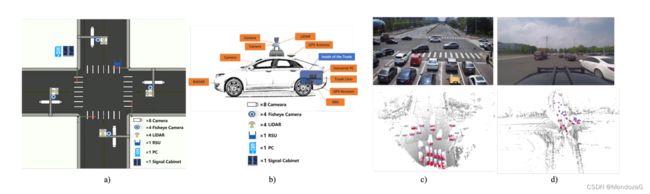
传感器分布则有车端也有路端的分布也有车路协同端分布。


-----------------------------------------------------------------------------------------
感觉有收获的伙伴可以点个关注,欢迎添加到收藏和讨论!