机器学习在HEVC 视频编码中的实践
作者介绍:张宏顺,08年硕士毕业后在桑达电子集团工作,负责车牌自动识别系统及车辆自动检测系统设计;11年加入华为,主要负责图像处理及视频压缩相关算法工作;15年6月加入腾讯,现主要从事视频和图片压缩相关工作。擅长图像处理、模式识别及视频压缩(H.263、H.264、H.265)等。
背景与目标
当前视频编码中应用最广泛的是AVC(H.264),而HEVC(H.265)作为下一代的视频编码算法,在压缩性能上可以再节省40%的码率,优势很明显,但H.265对转码机器性能要求较高,实时编码场景时,其高压缩性能不能被充分利用。
在x265中有ultrafast、veryfast、fast、medium、slow、slower、veryslow等配置,其中,veryslow对应复杂度最高,压缩性能也最好,不同CPU配置下,对1080p视频测试,编码速度如下表:

由上可见,对于1080p视频的实时转码(大于30帧),高配CPU也只能做medium配置,但veryslow相对于medium还有17%的压缩空间可用。因此,我们期待在保证压缩比少量下降情况下,显著提高视频编码的处理能力。
问题分析
一个标准的HEVC编码框架如下:
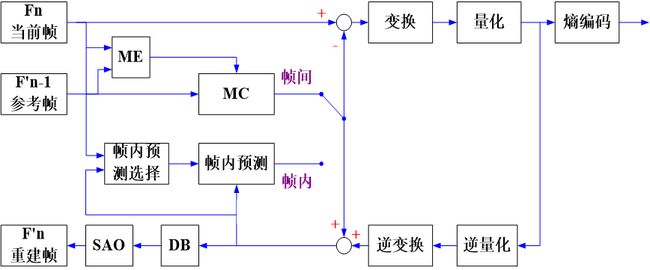
一帧图像送入到编码器,先经过帧内或帧间预测之后,得到预测值,预测值与输入数据相减,得到残差,然后进行DCT变化和量化,得到残差系数,然后送入熵编码模块输出码流,同时,残差系数经反量化反变换之后,得到重构图像的残差值,然后和帧内或者帧间的预测值相加,从而得到了重构图像,重构图像再经环内滤波之后,进入参考帧队列,作为下一帧的参考图像,从而一帧帧向后编码。
其中,帧内或帧间预测从最大编码单元(LCU,Largest Code Unit)开始,每层按照4叉树,一层层向下划分,做递归计算。对于每一个CTU,由CU64x64 到CU32x32, CU32x32到CU16x16,及CU16x16到CU8x8,总共三个层次的递归过程,然后再逐层比较,选出最优模式的CU划分情况。
下图是所有CU划分情况计算之后,选出的最优结果:
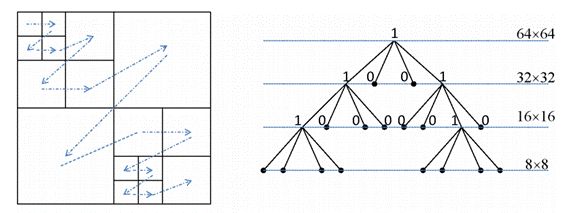
从上图示例来看,有些块做了第一层划分之后,就找到了最优的模式,不必再向下计算。
下图是2个常见场景的CU大小划分情况:

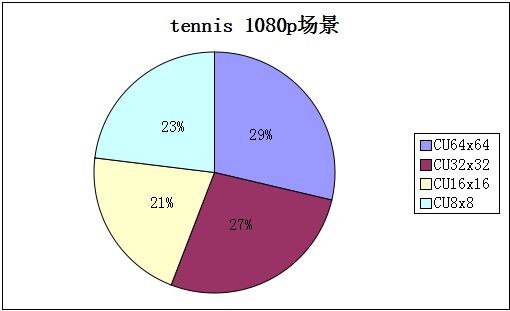
由图可见,30%的情况不需要做CU64x64,及后面CU32x32、CU16x16的计算;25%的情况不需要做CU32x32,及后面的CU16x16的计算;23%的情况不用再做CU16x16的计算,因此可以看出,CU划分这块有很大的优化空间。
但是,如果不计算,没有比较又怎知道当前CU计算是不是有用呢?因此,问题就转化为怎么找出一个能根据周围已计算块的信息,来预测当前块CU划分的方法。
解决方案
我们采用了支持向量机(SVM)和rskip算法相结合来预测当前块的CU划分情况。流程如下:

如上图所示,当前CTU开始做CU深度划分计算时,先对当前CU块做merge 和 skip的计算,然后判断当前最优模式的残差是否为0,如果为0,说明当前块是skip 块,直接结束CU深度计算,如果非0,则需要CU深度划分计算。接着,判断当前块的深度depth是否为0,如果非0,则执行rskip算法,再根据rskip的结果进一步判断当前块是否做depth+1层的CU计算;如果当前块depth为0,则根据当前块和相邻块来提取特征向量,然后根据当前块的slice类型,分别调用对应B帧或者P帧的预测模型;最后预测,并根据预测结果来决定是否做depth+1层的CU计算。
1. rskip算法
结合周围块的划分情况,来推测当前块的CU划分情况
首先,要计算相邻块对应深度的平均代价,然后计算当前块对应深度的已编码CU的平均代价,最后判断当前块是否要做depth+1的深度划分。
第一步:计算相邻块对应深度的平均代价,深度为1时记作Avg_depth1_cost。
取当前CTU 的相邻位置的CTU,如下图所示,左边、上边、左上角,及右上角4个CTU的CU划分信息,每个CTU的所有深度对应的代价。

计算周围相邻块的平均代价,相邻块按照左边:上边:左上:右上=2:2:1:1的权重计算。
第二步:计算当前CTU内,已经确定的,相同深度CU代价的平均值,深度为1时记作Avg_depth1_cost。
如果已确定的CU个数为0,则代价cost=0,否则cost为所有块代价的平均值。
其他深度的计算类似,不再累述。
第三步:预测当前CU是否做进一步分割。
定义阈值Threshold_depth1 = ( Avg_depth1_cost *4 + Avg_curr_CU_depth1*3)/(3+4);
当前CU做完merge和skip计算之后,其最优模式对应的代价,记作curr_cost_depth1,如果curr_cost_depth1 < Threshold_depth1,则认为当前CU不需要再做进一步深度划分,否则需要作进一步划分。
Depth=2 和depth = 3的判断过程与depth等于1相同,均取相同深度的代价进行判断。
2. 支持向量机(SVM)预测模型
支持向量机(Support Vector Machine,SVM)是一种监督式学习的方法,可广泛地应用于统计分类以及回归分析。
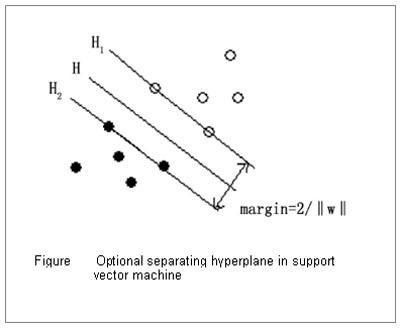
SVM基本原理是将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边,建有两个互相平行的超平面。建立方向合适的分隔超平面使两个与之平行的超平面间的距离最大化。其假定为,平行超平面间的距离越大,分类器的总误差越小。
SVM的关键在于核函数。低维空间向量集通常难于划分,解决的方法是将它们映射到高维空间。但这个办法带来的困难就是计算复杂度的增加,而核函数正好巧妙地解决了这个问题。
SVM预测的准确度与用于训练和预测的特征向量关系很大,由于整个编码过程中I帧占得比值较小,因此只对帧间CU深度划分进行预测,特征向量由8个特征值组成,即当前CU块merge的代价,merge的失真,当前块的方差及量化系数,左边块的代价和深度信息,及上边块的代价和深度信息组成。
模型训练之前,要将训练样本映射到[-1 1]区间,然后采用RBF内核,对B帧、P帧分开训练,最后分别得到B帧、P帧的预测模型。这里我们采用开源软件LIBSVM (可从http://www.csie.ntu.edu.tw/~cjlin/ 获取)来实现。
模型训练好后,就可以在编码时使用。首先,创建编码器的同时,将预测模型加载到编码器中;然后,在计算当前CU块时,提取上述8个特征值,组成预测样本,归一化后,送给预测模型,经简单计算,会输出-1或1两种情况。如果为1表示当前CU需要做depth+1层的CU计算,否则,当前CU块不再做进一步划分,直接进入PU划分模式。
效果
我们在x265上采用svm (p cu64+b cu64)+rskip(p cu32+p cu16+ b cu32+b cu16),对每层CU做快速选择。多序列测试结果表明,相比于x265 veryslow模式,采用此方案,编码速度提升了94%,压缩性能下降了.1%,因此视频编码的处理能力得到显著提升。
将机器学习引入到编码器优化上,是个较大胆的尝试,而且从效果来看,编码速度提升显著,且压缩性能下降不多,说明该方法是可取的,这也为后面编码器优化拓宽一个好的思路。