朴素贝叶斯算法(Naive Bayes) 原理总结
朴素贝叶斯算法是基于贝叶斯定理和特征条件独立假设的分类方法。对于给定的训练数据集,首先基于特征条件独立假设学习输入输出的联合概率分布;然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y。
1 数学知识
贝叶斯定理:

特征条件独立假设:
![]()
2 朴素贝叶斯
2.1 算法原理
输入空间:![]()
输出空间:y={C1,C2,…,CK}。
训练集:T={(x1,y1),(x2,y2),…,(xN,yN)}。
对于每个实例,其P(X,Y)独立同分布。朴素贝叶斯算法通过训练数据集学习联合概率分布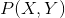 。具体地,分为学习先验概率分布和条件概率分布。然后据此计算出后验概率分布。
。具体地,分为学习先验概率分布和条件概率分布。然后据此计算出后验概率分布。
1) 先验概率分布:
P(Y=Ck),k=1,2,..,K。
先验概率的极大似然估计:

2)条件概率分布:
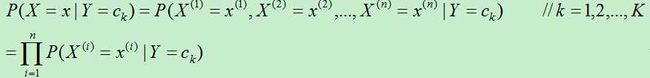
则极大似然估计:

![]()
说明:每个实例有n个特征,分别为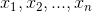 ,每个特征分别有
,每个特征分别有![]() 种取值,即特征
种取值,即特征 有
有 种取值。则计算该条件概率分布
种取值。则计算该条件概率分布![]() 的时间复杂度为:
的时间复杂度为:![]() , 若类别取值有m个,参数个数为
, 若类别取值有m个,参数个数为![]() , 时间复杂度非常的高。
, 时间复杂度非常的高。
3)对新的实例进行分类:
为了计算将新的实例进行分类,我们需要计算该实例属于每类的后验概率,最终将此实例分给后验概率最大的类。
后验概率为:


所以,朴素贝叶斯算法对条件概率分布作了条件独立性假设。即在分类确定的情况下,x的各特征相互独立。因为用到了此假设故而在贝叶斯前面加了朴素二字。于是有:

所以有:
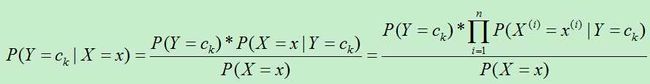
由于对同一个实例,P(X=x)的概率相通同,故而只需考虑分子部分即可。
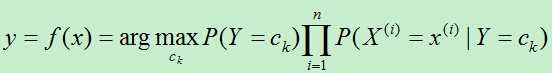
2.2 朴素贝叶斯的改进
在计算条件概率时,有可能出现极大似然函数为0的情况,这时需要在分子分母上添加上一个正数,使得其值不为0.


同样,先验概率的贝叶斯估计也需要改进:
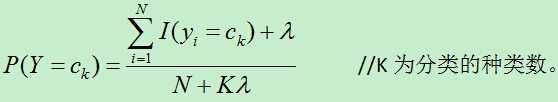
2.3 后验概率最大化
朴素贝叶斯将实例分到后验概率最大的类中,等价于0-1损失函数时期望风险最小化。
0-1损失函数为:
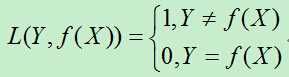
期望风险为:

为了使期望风险最小化,只需对X=x逐个极小化,
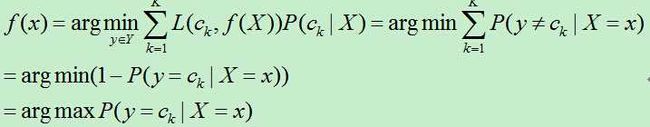
即通过期望风险最小化,得到了后验概率最大化。
3 三种常见模型
朴素贝叶斯算法有三种常见模型:多项式模型、高斯模型、伯努利模型。
1)多项式模型
多项式模型适用于离散特征情况,在文本领域应用广泛, 其基本思想是:我们将重复的词语视为其出现多次。
2)高斯模型
高斯模型适合连续特征情况 。
高斯模型的前提是----假设数据每一维特征都服从高斯分布,则p(x_{i}|y_{k})的计算公式为:

i 是第i维特征
3)伯努利模型
伯努利模型适用于离散特征情况,它将重复的词语都视为只出现一次。
![]()
我们看到,”发票“出现了两次,但是我们只将其算作一次。
4 python 实现
import numpy as np
class NaiveBayesian:
def __init__(self, alpha):
self.classP = dict()
self.classP_feature = dict()
self.alpha = alpha # 平滑值
# 加载数据集
def createData(self):
data = np.array(
[
[320, 204, 198, 265],
[253, 53, 15, 2243],
[53, 32, 5, 325],
[63, 50, 42, 98],
[1302, 523, 202, 5430],
[32, 22, 5, 143],
[105, 85, 70, 322],
[872, 730, 840, 2762],
[16, 15, 13, 52],
[92, 70, 21, 693],
]
)
labels = np.array([1, 0, 0, 1, 0, 0, 1, 1, 1, 0])
return data, labels
# 计算高斯分布函数值
def gaussian(self, mu, sigma, x):
return 1.0 / (sigma * np.sqrt(2 * np.pi)) * np.exp(-(x - mu) ** 2 / (2 * sigma ** 2))
# 计算某个特征列对应的均值和标准差
def calMuAndSigma(self, feature):
mu = np.mean(feature)
sigma = np.std(feature)
return (mu, sigma)
# 训练朴素贝叶斯算法模型
def train(self, data, labels):
numData = len(labels)
numFeaturs = len(data[0])
# 是异常用户的概率
self.classP[1] = (
(sum(labels) + self.alpha) * 1.0 / (numData + self.alpha * len(set(labels)))
)
# 不是异常用户的概率
self.classP[0] = 1 - self.classP[1]
# 用来存放每个label下每个特征标签下对应的高斯分布中的均值和方差
# { label1:{ feature1:{ mean:0.2, var:0.8 }, feature2:{} }, label2:{...} }
self.classP_feature = dict()
# 遍历每个特征标签
for c in set(labels):
self.classP_feature[c] = {}
for i in range(numFeaturs):
feature = data[np.equal(labels, c)][:, i]
self.classP_feature[c][i] = self.calMuAndSigma(feature)
# 预测新用户是否是异常用户
def predict(self, x):
label = -1 # 初始化类别
maxP = 0
# 遍历所有的label值
for key in self.classP.keys():
label_p = self.classP[key]
currentP = 1.0
feature_p = self.classP_feature[key]
j = 0
for fp in feature_p.keys():
currentP *= self.gaussian(feature_p[fp][0], feature_p[fp][1], x[j])
j += 1
# 如果计算出来的概率大于初始的最大概率,则进行最大概率赋值 和对应的类别记录
if currentP * label_p > maxP:
maxP = currentP * label_p
label = key
return label
if __name__ == "__main__":
nb = NaiveBayesian(1.0)
data, labels = nb.createData()
nb.train(data, labels)
label = nb.predict(np.array([134, 84, 235, 349]))
print("未知类型用户对应的行为数据为:[134,84,235,349],该用户的可能类型为:{}".format(label))