朴素贝叶斯算法
3.4.1什么是朴素贝叶斯算法
朴素贝叶斯方法是在 贝叶斯 算法的基础上进行了相应的简化,即假定给定目标值时属性之间相互条件独立。. 也就是说没有哪个属性变量对于决策结果来说占有着较大的比重,也没有哪个属性变量对于决策结果占有着较小的比重。. 虽然这个简化方式在一定程度上降低了贝叶斯分类算法的分类效果,但是在实际的应用场景中,极大地简化了贝叶斯方法的复杂性
3.4.2 概率基础
1 概率定义
3.4.3 联合概率 条件概率与相互独立
联合概率 包含多个条件,且所有条件同时成立的概率
p(a|b) = p(a)p(b) <==> 事件a和事件b相互独立
朴素:假设特征之间相互独立
优点:对确实数据不太敏感,算法比较简单,常用与对文本进行分类,分类准确度高,速度快
缺点:由于使用了样本属性独立性的假设,所以如果特征属性有关联时效果不佳
def nb_news():
"""
用朴素贝叶斯算法对新闻进行分类
:return:
"""
# 1)获取数据集
news = fetch_20newsgroups(subset="all")
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)
# 3)特征工程:文本特征抽取-tfidf
transfer = TfidfVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4)朴素贝叶斯算法预估器流程
estimator = MultinomialNB()
estimator.fit(x_train, y_train)
# 5)模型评估
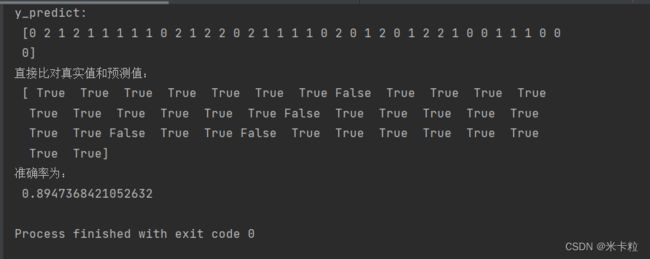
# 方法1 直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2 计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
return None
3.5 决策树
3.5.1认识决策树
如何高效的进行决策:特征的先后顺序
3.5.2 决策树分类原理详解
信息论基础
1)信息
消除随机不定性的东西
2)信息的衡量
信息量 信息熵
3.5.3决策树的API
class sklearn.tree.DecisionTreeClassifier='gini'
max_depth=None,random_state=None
决策树分类器
criterion:默认是‘gini’系数,也可以选择增益的熵‘entropy’
max_depth:树的深度
random_state:随机数种子
def decision_iris():
"""
用决策树对鸢尾花进行分类
:return:
"""
# 1)获取数据集
iris = load_iris()
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3)决策树预估器
estimator = DecisionTreeClassifier(criterion="entropy")
estimator.fit(x_train, y_train)
# 4)模型评估
# 方法1 直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2 计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
return None
def decision_iris():
"""
用决策树对鸢尾花进行分类
:return:
"""
# 1)获取数据集
iris = load_iris()
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=22)
# 3)决策树预估器
estimator = DecisionTreeClassifier(criterion="entropy")
estimator.fit(x_train, y_train)
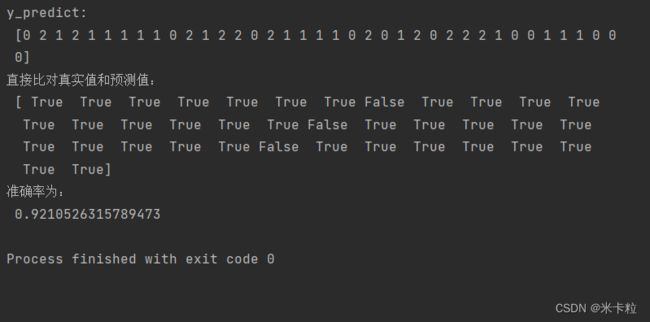
# 4)模型评估
# 方法1 直接比对真实值和预测值
y_predict = estimator.predict(x_test)
print("y_predict:\n", y_predict)
print("直接比对真实值和预测值:\n", y_test == y_predict)
# 方法2 计算准确率
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
# 可视化决策树
export_graphviz(estimator, out_file="iris_tree.dot", feature_names=iris.feature_names)
return None
决策树总结:
优点:简单的理解和解释,树木可视化
缺点:决策树学习者可以创建不能很好的推广数据过于复杂的数,这被称为过拟合
改进:减枝cart算法
随机森林