网络程序设计课程项目学习总结-SA16225018-曾龙飞
项目概要
· 本项目主要可分为两大方面:
1 .血常规检查报告的OCR识别
相关链接:神经网络实现手写字符识别系统点击打开链接
· 2.根据OCR识别的血常规数据预测性别和年龄(本例中使用的是Spark平台下的朴素贝叶斯算法)
项目托管地址: 点击前往(项目整合版在Spark/Merge目录下)
学习收获
孟宁老师的《网络程序设计》这门课程循序渐进,以手写识别OCR作为学习神经网络的突破口,从Python语言到Flask框架,从透视算法到图像识别,从神经网络到机器学习,课程项目由全班70余名同学相互协作、共同开发,群策群力开源共享。这不仅是对我们团队精神和协作能力的一种锻炼,也是对孟老师准确把控项目团队、高效管理开发过程的一种体现。项目整体进展十分顺利,没有出现代码冗余、错删错改等重大失误。这不仅要归功于同学们对整个项目添砖加瓦贡献出的自己的一份力量,也得益于孟老师对于整个项目过程的严格把控。自己从一个机器学习的小白,逐步跟进,努力为项目做出贡献。孟老师也作为团队内的一名全栈工程师帮助我们完善、改进项目,不仅给予我们技术上的指导,还让我们注意到团队协作开发当中文档的重要性。规范的文档、标准的模块接口、良好的代码书写习惯是团队合作项目中必不可少的部分。每周的分享阶段,更是发扬了软件工程师开源的精神,大家分享各个领域的知识,使我们团队的每个人都进步飞速。
通过半学期的课程学习,我学到了许多东西,从之前没有写过一句Python到如今基本熟知Python语法;从之前的图像识别小白到如今初步了解图像透视算法;之前都是仰望机器学习大神,如今对神经网络和机器学习的基本原理都有了一定的了解,自己也可以深入的尝试。做任何事情最困难的就是迈出第一步,而《网络程序设计》这门课已经帮我迈出了许许多多的第一步,为今后的学习提供了更多的选择和方向。
血常规检查报告的OCR识别
主要功能:
· 前端页面接收用户上传的血常规报告单图片并提交至服务器
· 服务器首先图片进行预处理,使用透视变换算法对图片做一定的矫正。之后对图片进行识别,将识别结果转换成JSON格式与矫正后的图片一并存储至MongoDB数据库。然后将矫正后的图片反馈至前端页面供用户确认矫正过程是否正确
· 当前端页面监听到“生成报告”的点击事件时,使用Ajax技术向服务器请求识别结果并打印血常规报告单
预处理
在获取到上传的血常规化验单图片后,项目中对其进行了预处理,作用主要是为了减小噪声,为后边的识别算法服务,在这里主要用到了以下两个方法:
a)高斯平滑
img_gb= cv2.GaussianBlur(img_gray, (gb_param, gb_param), 0)
b)腐蚀、膨胀
closed =cv2.morphologyEx(img_gb, cv2.MORPH_CLOSE, kernel)
opened =cv2.morphologyEx(closed, cv2.MORPH_OPEN, kernel)
线段检测
为了对图片各个数值所在的区域进行定位,这里需要检测出图片中比较明显的标识,3条黑线,然后利用这三条线对整张图片进行标定。主要用到了以下3个步骤:
a)Canny边缘检测
edges= cv2.Canny(opened, canny_param_lower , canny_param_upper)
b)轮廓提取
contours,hierarchy = cv2.findContours(edges, cv2.RETR_TREE,cv2.CHAIN_APPROX_SIMPLE)
c)求最小外接矩形
def getbox(i):
rect = cv2.minAreaRect(contours[i])
box = cv2.cv.BoxPoints(rect)
box = np.int0(box)
return box
OCR
这里主要利用OCR对血常规报告中的字符进行识别,得到具体的数值,用于后续的预测。其中步骤主要是根据上边求得的三条线段对图片进行透射变换,根据标定好的像素位置,利用pytesseract进行字符识别。
a)透射变换
#设定透视变换的矩阵
points =np.array([[line_upper[0][0],line_upper[0][1]], [line_upper[1][0],line_upper[1][1]],
[line_lower[0][0], line_lower[0][1]],[line_lower[1][0], line_lower[1][1]]],np.float32)
standard =np.array([[0,0], [1000, 0], [0, 760], [1000, 760]],np.float32)
#使用透视变换将表格区域转换为一个1000*760的图
PerspectiveMatrix= cv2.getPerspectiveTransform(points,standard)
self.PerspectiveImg= cv2.warpPerspective(self.img, PerspectiveMatrix, (1000, 760))
b)截图(这部分做过动态截取的改进)
cross = cv2.getStructuringElement(cv2.MORPH_CROSS,(5, 5))
diamond = cv2.getStructuringElement(cv2.MORPH_RECT,(5, 5))
diamond[0, 0] = 0
diamond[0, 1] = 0
diamond[1, 0] = 0
diamond[4, 4] = 0
diamond[4, 3] = 0
diamond[3, 4] = 0
diamond[4, 0] = 0
diamond[4, 1] = 0
diamond[3, 0] = 0
diamond[0, 3] = 0
diamond[0, 4] = 0
diamond[1, 4] = 0
square = cv2.getStructuringElement(cv2.MORPH_RECT,(5, 5))
x = cv2.getStructuringElement(cv2.MORPH_CROSS,(5, 5))
result1 = cv2.dilate(image,cross)
result1 = cv2.erode(result1, diamond)
result2 = cv2.dilate(image, x)
result2 = cv2.erode(result2,square)
result = cv2.absdiff(result2, result1)
retval, result = cv2.threshold(result, 40, 255, cv2.THRESH_BINARY)
for j in range(result.size):
y = j / result.shape[0]
x = j % result.shape[0]
if result[x, y] == 255:
cv2.circle(image, (y, x), 5, (255,0,0))
cv2.imshow("Result", image)
cv2.waitKey(0)
cv2.destroyAllWindows()


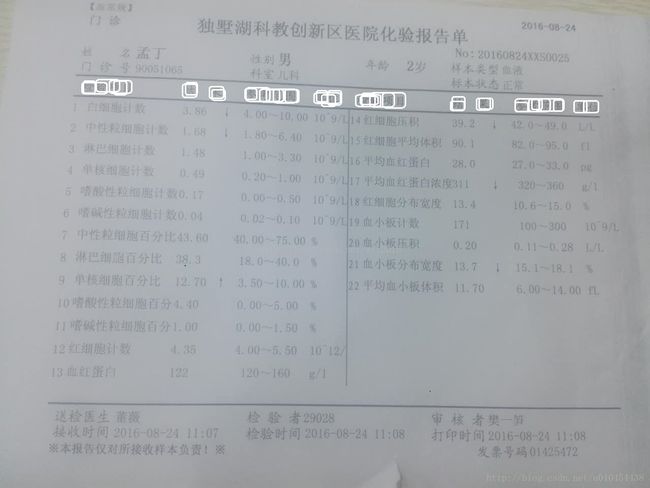
def autocut(self, num,param=default):
ifself.PerspectiveImgisNone:
self.PerspectivImg =self.filter(param)
#仍然是空,说明不是报告
ifself.PerspectiveImgisNone:
return -1
#输出年龄
img_age = self.PerspectiveImg[15 :70,585 : 690]
cv2.imwrite(self.output_path +'age.jpg', img_age)
#输出性别
img_gender = self.PerspectiveImg[15 :58,365 : 420]
cv2.imwrite(self.output_path +'gender.jpg', img_gender)
#输出时间
img_time = self.PerspectiveImg[722 :760,430 : 630]
cv2.imwrite(self.output_path +'time.jpg', img_time)
#转换后的图分辨率是已知的,所以直接从这个点开始读数据就可以了
startpoint = [199,132]
vertical_lenth =37
lateral_lenth =80
def getobjname(i, x, y):
region_roi = self.PerspectiveImg[y: y+vertical_lenth, x : x+170]
filename = self.output_path +'p' + str(i) +'.jpg'
cv2.imwrite(filename, region_roi)
def getobjdata(i, x, y):
region_roi = self.PerspectiveImg[y: y+vertical_lenth, x : x+lateral_lenth]
filename = self.output_path +'data' + str(i) +'.jpg'
cv2.imwrite(filename, region_roi)
#输出图片
if num<=13and num>0:
for iinrange(num):
getobjname(int(i),25,startpoint[1])
getobjdata(int(i), startpoint[0],startpoint[1])
startpoint[1] =startpoint[1] + 40
elif num>13:
for iinrange(13):
getobjname(int(i),25,startpoint[1])
getobjdata(int(i), startpoint[0],startpoint[1])
startpoint[1] =startpoint[1] + 40
startpoint = [700,135]
for iinrange(num-13):
getobjname(int(i+13),535, startpoint[1])
getobjdata(int(i+13),startpoint[0], startpoint[1])
startpoint[1] =startpoint[1] + 40
#正常结束返回0
return0
· filter函数 -过滤掉不合格的或非报告图片
返回img经过透视过后的PIL格式的Image对象,如果缓存中有PerspectivImg则直接使用,没有先进行透视过滤失败则返回None。@param filter参数
· autocut函数 -将图片中性别、年龄、日期和各项目名称数据分别剪切出来
o 用于剪切ImageFilter中的img成员,剪切之后临时图片保存在out_path,如果剪切失败,返回-1,成功返回0。 @num 剪切项目数@param剪切参数
o 剪切出来的图片在BloodTestReportOCR/temp_pics/文件夹下
o 函数输出为data0.jpg,data1.jpg……等一系列图片,分别是白细胞计数,中性粒细胞记数等的数值的图片。
· classifier.py
用于判定裁剪矫正后的报告和裁剪出检测项目的编号
· imgproc.py
将识别的图像进行处理二值化等操作,提高识别率包括对中文和数字的处理
根据OCR识别的血常规数据预测性别和年龄
主要功能:
· 首先上传血常规报告图片,由上一部分的工作对血常规报告图片进行识别,获得血常规数据
· 当前端页面监听到“预测性别年龄”的点击事件时,使用Ajax技术向服务器请求预测结果。服务器端首先使用朴素贝叶斯算法训练贝叶斯模型(由于目前Spark平台尚未支持Python下训练模型的存储,因此只能在每次预测之前都进行一次训练),然后使用训练模型对血常规数据做预测,以JSON的格式返回给前端页面用于结果显示
相关模块说明:
· data_all.csv
训练数据集,共有2058条训练数据
· LabeledPointsdata_age.txt和LabeledPointsdata_sex.txt
执行dataformat.py之后获得的Spark可识别的labeled point数据
· BloodTestReportbyNB.py
使用朴素贝叶斯算法进行训练与预测。首先读取Spark可识别的labeledpoint数据(分为sex和age两项,分别进行训练和预测),然后使用Spark提供的API进行训练,返回一个训练模型。之后读取预测数据集,使用训练模型对预测数据集做预测。预测函数返回的是一个RDD数据类型,首先需要将其转换为collect集合,然后转换为str类型的数据,之后构建JSON结构,最后返回JSON结构的预测数据。相关的代码如下:
运行环境搭建
· 安装numpy
sudo apt-get install python-numpy # http://www.numpy.org/
· 安装opencv
sudo apt-get install python-opencv # http://opencv.org/
· 安装OCR和预处理相关依赖
sudo apt-get install tesseract-ocr
sudo pip install pytesseract
sudo apt-get install python-tk
sudo pip install pillow
· 安装Flask框架
sudo pip install Flask
· 安装MongoDB
sudo apt-get install mongodb #如果提示no module name mongodb,先执行sudo apt-get update
sudo service mongodb started
sudo pip install pymongo
· 安装JDK
下载jdk-8u45-linux-x64.tar.gz,解压到/opt/jdk1.8.0_45
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html
· 安装Scala
安装scala,下载scala-2.11.6.tgz,解压到/opt/scala-2.11.6
下地地址: http://www.scala-lang.org/
· 安装Spark
下载spark-1.3.1-bin-hadoop2.6.tgz,解压到/opt/spark-hadoop
下载地址:http://spark.apache.org/downloads.html
· 配置JDK和Spark相关的环境变量
o sudo gedit /etc/profile
o 在文件最后增加:
#Setting JDK JDK环境变量
export JAVA_HOME=/opt/jdk1.8.0_45
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin:$PATH
#Setting Scala Scala环境变量
export SCALA_HOME=/opt/scala-2.11.6
export PATH=${SCALA_HOME}/bin:$PATH
# Setting Spark Spark环境变量
export SPARK_HOME=/opt/spark-hadoop/
#PythonPath 将Spark中的pySpark模块增加的Python环境中
export PYTHONPATH=/opt/spark-hadoop/python
o 重启电脑,使/etc/profile永久生效,临时生效,打开命令窗口,执行 source /etc/profile在当前窗口生效
· 详细的Spark安装和配置过程请参考http://www.open-open.com/lib/view/open1432192407317.html
运行效果
- 运行dataformat.py将csv格式的训练数据集格式化为Spark可用的labeled point数据
python dataformat.py - 运行view.py启动Spark和Web服务器
python view.py - 打开浏览器,在地址栏输入:0.0.0.0:8080/index.html
- 上传图片
上传图片效果图“提交”按钮下方图片为经过矫正之后的图片,供用户确认矫正过程的正确性
- 生成血常规报告
生成报告效果图 - 预测性别年龄
预测效果图
项目托管
- 本项目采用多人合作开发的形式,由孟老师作为项目经理使用GitCoding进行代码托管和版本控制
- 项目托管地址: 点击前往(项目整合版在Spark/Merge目录下)
个人贡献
由于本人之前的Python和机器学习基本是零基础,所以在项目的开发过程中所做的贡献略微单薄,主要做了机器学习背景知识的分享:
1.SVM(Support Vector Machine) 支持向量机是一个有监督的学习模型,通常用来进行模式识别、分类、以及回归分析。
2.Deep Learning - a new era of NN-卷及神经网络的补充介绍
血常规检查报告的OCR识别