2022泰迪杯自动提取csv表格文件中的数据,保存到符合YOLOv5格式的txt文件中,并修改标签值的代码实现
(1)目的:
根据官方给的csv表格数据,自动生成yolov5所需的txt标签文件,
并且把原先的标签:labels = ['6', '7', '8', '9', '10', '25', '41', '105', '110', '115', '148', '156', '222', '228', '235', '256', '280', '310', '387', '392', '394', '398', '401', '402','430', '480', '485', '673']
更换成新标签:labels = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18', '19', '20', '21', '22', '23','24', '25', '26', '27']
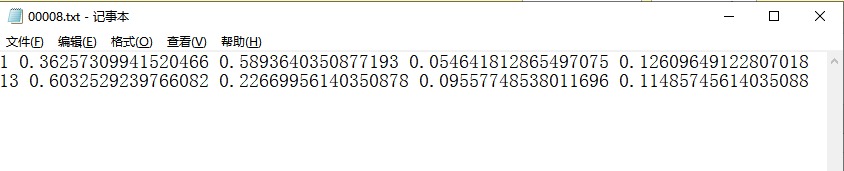
(2)知识点:yolov5的txt标签文件里面的格式为:
- 类别、矩形框的中心点坐标 (x、y)、矩形框的长w、矩形框的宽h
- 归一化处理,假设图像长宽为W、H,则需 x/W、y/H、w/W、h/H
- 1 0.36257309941520466 0.5893640350877193 0.054641812865497075 0.12609649122807018
- 13 0.6032529239766082 0.22669956140350878 0.09557748538011696 0.11485745614035088
(3)代码实现:(逻辑流畅!注释清晰!)
import os
import pandas as pd
# 读取csv失败,需要另存为xls文件
df = pd.read_excel(r'G:\English_path\pest1.xls') # 读取xls中第一个sheet
number = df.index.values
title = df.columns.values
print("行序号:{}".format(number)) # 打印所有行的序号
print("列标题:{}".format(title)) # 打印所有列的标题
all_data = df.values
# print("所有数据: \n", all_data)
save_txt_files_path = "dataset/A_txt/"
for i in range(1, len(number)):
print(all_data[i][2])
if all_data[i][2] != 0:
print(all_data[i])
# 更新标签值
labels = ['6', '7', '8', '9', '10', '25', '41', '105', '110', '115',
'148', '156', '222', '228', '235', '256', '280', '310', '387',
'392', '394', '398', '401', '402', '430', '480', '485', '673']
for j in range(28):
if str(all_data[i][2]) == labels[j]:
label = j
break
# 归一化处理
x = all_data[i][4] / 5472
y = all_data[i][5] / 3648
w = abs(all_data[i][6] - all_data[i][8]) / 5472
h = abs(all_data[i][7] - all_data[i][9]) / 3648
# 判断当前的名称是否和前一个名称相同
# 如果不同,则创建新的txt文件;否则不创建新的txt文件,在原有的文件基础上继续写入内容
if all_data[i][1] != all_data[i-1][1]:
out_txt_path = os.path.join(save_txt_files_path, all_data[i][1].split('.')[0] + '.txt')
out_txt_f = open(out_txt_path, 'w')
out_txt_f.write(str(label) + " " + str(x) + " " + str(y) + " " + str(w) + " " + str(h) + '\n')
else:
out_txt_f.write(str(label) + " " + str(x) + " " + str(y) + " " + str(w) + " " + str(h) + '\n')
(4)输入及输出截图如下:

>>>如有疑问,欢迎评论区一起探讨