YOLOX训练自己的VOC数据集
文章目录
- 一、下载YOLOX代码
- 二、配置文件
-
- 修改数据集参数
- 三、开始训练
-
- 报错1:no model named 'yolox'
- 报错2:No such file or directory: '/ai/pytorch/YOLOX-main/datasets/VOCdevkit/VOC2012/ImageSets/Main/trainval.txt'
- 四、 使用训练完的模型进行预测
-
- 报错:no model named 'yolox'
- 五、预测效果:
-
- yolox-s效果
- yolox-m效果
- yolox-l 效果
- yolox-x效果
- yolov5-x效果
- 六、tensorboard可视化
-
- 报错:ValueError: Duplicate plugins for name projector
最近想跑一下yolox的代码,但是上网搜了几篇博客后感觉都异常的麻烦,而且跑起来还有各种各样的问题,不如自己写篇总结,把步骤和报错都记录下来。按照我的步骤一步步来,肯定是能跑通的。
一、下载YOLOX代码
https://github.com/Megvii-BaseDetection/YOLOX
二、配置文件
修改数据集参数
首先将自己的数据集放入datasets文件中,注意这里Main下面的文件名,trainval.txt代表训练集,test.txt代表测试集,官方代码中就是这样的,不想改官方代码,这里就跟官方保持一致就行了。

然后修改yolox_voc.py文件(可以使用default中的yolox、yolox_s等,这里默认使用yolox_voc.py做例子)
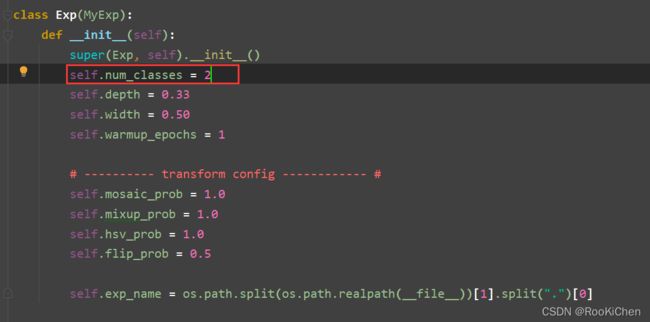
将num_classes修改为自己数据集的类别总数
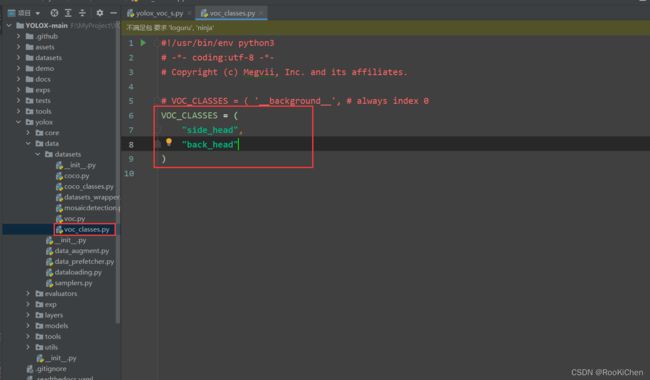
之后再修改voc_classes.py文件,修改为自己的类别
三、开始训练
首先自己先创建一个weights文件,存放模型的预训练权重:
yolox_s.pth
在终端输入:
-d 表示使用哪一块GPU,-b 表示bitch_size,-c 表示预训练权重
python tools/train.py -f exps/example/yolox_voc/yolox_voc_s.py -d 1 -b 1 -c weights/yolox_s.pth
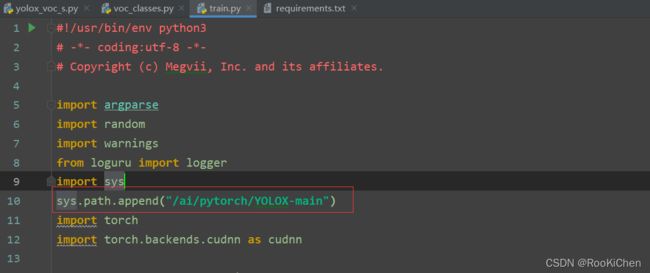
报错1:no model named ‘yolox’

只需将系统路径添加进去即可(这里添加的是你自己的工作路径,我是在服务器上跑的,根目录就是/ai/pytorch)
报错2:No such file or directory: ‘/ai/pytorch/YOLOX-main/datasets/VOCdevkit/VOC2012/ImageSets/Main/trainval.txt’

这里把这个2012删除即可。

四、 使用训练完的模型进行预测
训练完成后,会生成一个YOLOX-outputs文件夹,里面包含了训练后保存的权重和训练时的信息,由于我是在学校服务器上训练的,选择的是300轮里最好的权重,保存到自己创建的weights文件夹里了。

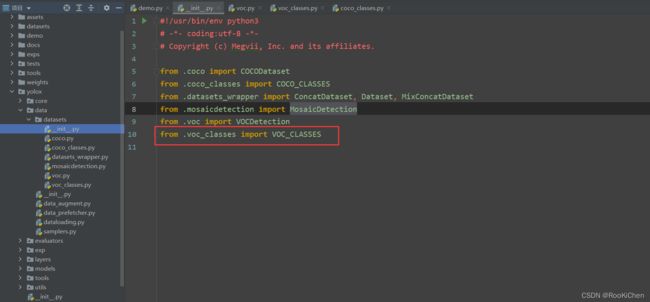
修改yolox/data/datasets/下的init.py文件,添加:from .voc_classes import VOC_CLASSES,之后在toos/demo.py文件中将COCO_CLASSES全部修改为VOC_CLASSES。

在终端中输入:-c 代表训练好的权重,-path 代表你要预测的图片存放的文件夹,
若想进行视频预测,只需将下面的 image 更换为 video;
若想预测整个文件夹,将class01.jpg去掉,只留 --path assets/ 。
python tools/demo.py image -f exps/example/yolox_voc/yolox_voc_s.py -c weights/best_ckpt.pth --path assets/class01.jpg --conf 0.25 --nms 0.45 --tsize 640 --save_result --device [cpu/gpu]
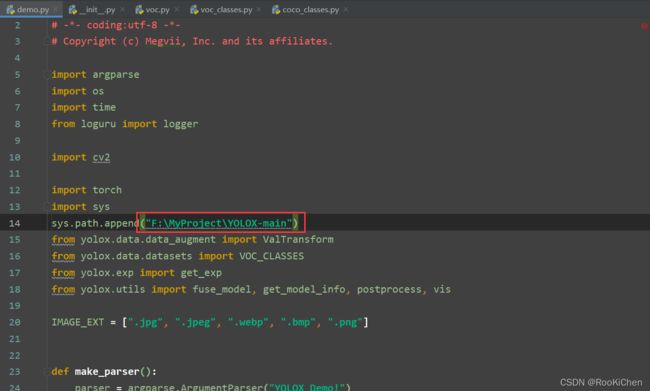
报错:no model named ‘yolox’
还是老问题,需要添加系统路径,我添加的是自己电脑的工作路径:
预测完成后会在YOLOX_outputs下创建存放预测图片的文件夹:
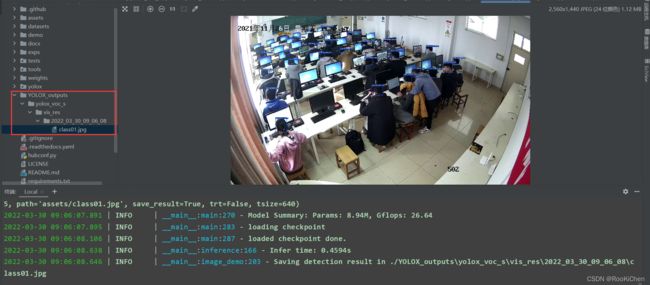
五、预测效果:
yolox-s效果
感觉效果还行吧,毕竟跑的是最小的s,不过网上好多人说实际用起来不如yolov5,等后面跑一下yolox-x和yolox-Darknet53,看看效果怎么样吧。

yolox-m效果

yolox-l 效果
看这效果,貌似不如yolov5,前面的小头直接就检测不出来了,后续跑一下yolox-x,看看效果再做评价吧。

yolox-x效果
跟yolox-l一样,前面的小头没检测出来,但是其他的头概率很高,可能是因为使用了mosaic的原因吧,但总体效果感觉确实没yolov5好,后面再换个小目标数据集试一下。

yolov5-x效果
都是在预训练权重下训练300论的效果,很明显,吹的这么牛的yolox-x实际 用起来还没yolov5-x效果好,yolox-x的FLOPs(G)是281.9, yolov5-xFLOPs(G)217.1,两者差的不多,217.1的FLOPs(G)肯定是可以满足实际需求的,但是两者识别的效果差的太多了,该说不说,人生苦短,我选yolov5-x!(顺便说一下,yolox-x训练完的权重文件大概330mb,yolov5-x的权重文件是166mb)

六、tensorboard可视化
在终端输入:
tensorboard --logdir=YOLOX_outputs/ --bind_all

报错:ValueError: Duplicate plugins for name projector
只需将这个tensorboard-2.8.0.dist.info文件删除就可以了(注意是你当前conda环境下的site-packages,我的环境是pytorch)