技术知识介绍:工业级知识图谱方法与实践-解密知识谱的通用可迁移构建方法,以阿里巴巴大规模知识图谱核心技术为介绍
技术知识介绍:工业级知识图谱方法与实践
纯KG技术领域分享:解密知识谱的通用可迁移构建方法,以阿里巴巴大规模知识图谱核心技术为介绍。
0.知识图谱
KG框架图
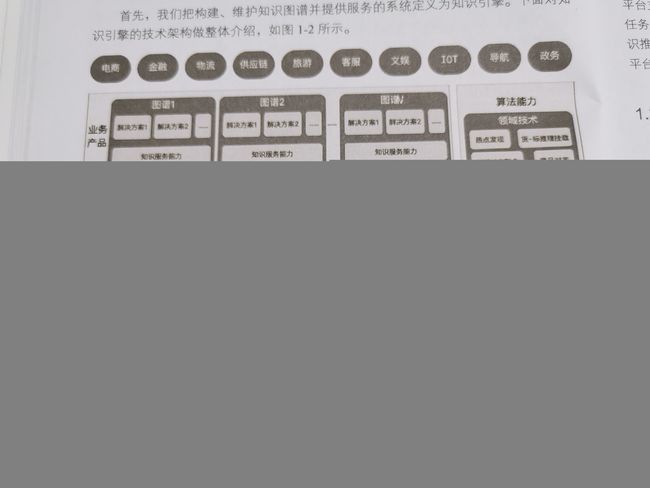
知识服务框架图

1.知识表示
- 逻辑符号
- 语义网络(三元组)
- 词向量(word embedding)
1.1 面向互联网的知识表示方法
1.RDF(资源描述框架) 2. RDFS 3. OWL(Web Ontolog Language)
1.2 基于连续向量的知识表示
整体方法是:将图谱中的实体关系映射到低维连续的向量空间
主要有:平移距离模型(距离函数)和语义匹配模型(相似度函数)
1.3 行业知识图谱
知识体系复用
推荐:开源知识图谱:DBpedia、YAGO、Freebase、OpenCyc 中文:OpenKG
网络百科:wikipedia、wikidata、谷歌(MusicBrainz、Fashion model Directory、NNDB)等
1.3.1 非结构化数据的知识建模
1.候选术语抽取[目的是过去更多、更全的术语]
2.术语过滤[剔除低质量候选术语]
领域术语与普通词汇有不同特征,可以采用统计信息和语义信息过滤噪声,常见方法:互信息(MI)、词频逆文档频率(TF-TDF),术语相关频率(RTF)等定量刻画统计特征,或者用词向量方式捕捉术语之间的语义相关度刻画语义特征。
3.概念属性抽取
- 基于规则的属性抽取
- 基于百科统计的属性抽取
- 基于依存分析的属性抽取[语法语义]
1.3.2结构化、半结构化数据的知识建模
XML、JSON文档等,程序处理为符合格式即可
2.知识融合
知识融合难点
- 异构问题:不同知识库对一个实体表达差异很大,可能存在着大量的别名
- 歧义问题:不同实体使用相同类似的表达(如:苹果)
- 数据噪声问题:知识库融合后会造成信息缺失(实体属性值:不详)
- 跨语言问题:语义漂移,难度较高的异构问题
知识融合基本步骤包括:本体对其、实体对齐、信息融合
- 本体对齐:多个知识库本体对齐,涉及本体结构中的类、属性的对齐。目的是解决类、属性的异构问题
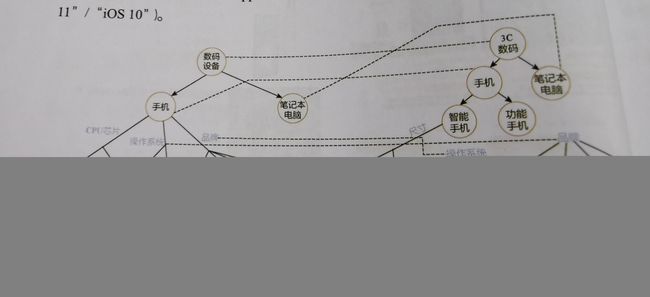
- 实体对齐:把多个知识库描述同一个实体找出来
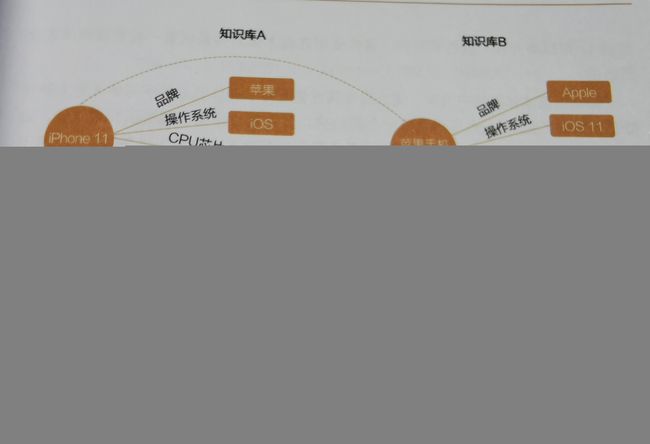
- 信息融合:将已经对齐的实体或者实体簇属性信息融合在一起,确保信息全面
主要解决:多个信息库数据冲突。

2.1 本体对齐
主要包括:类对齐、属性项对齐、属性值对齐
常见方法:基于语言学特征方法、基于结构特征方法
2.1.1 基于语言学特征方法
-
基于字典或词典方法:wordnet、hownet、哈工大大词林(通用词覆盖)
-
基于字面匹配方法:向量空间模型通过计算词的词频-逆文档频率(TF-IDF)考虑每个词的重要性(缺点:词比较短下,效果不佳)
-
基于字符串语义相似度方法:通过计算两个预训练词向量的向量相似度判断是否对齐,可以看做一个有监督分类问题。(优点:通过大量语料将词的字面特征、词常见的上下文等特征表示在同一个空间中)
-
基于上下文的方法:定义较多模板,扩充模板方法:Bootstrapping算法对“基于模板挖掘词对”和“基于词对发现模板”进行迭代,进行扩大词对(缺点:错误扩散,一个词对错误会导致大量错误词对)
举例:x简称y x是y的一种 这类模板。阿里巴巴集团和阿里巴巴互为同义词;连衣裙是“雪纺连衣裙”上位词。
2.1.2 基于结构特征的方法
Anchor-PROMPT算法:两对术语相似且在本体结构中有链接他们的路径,那么通用的路径中的术语也相似。

2.1.3 以阿里本体对齐方法为例
- 采用本体集成而非本体映射
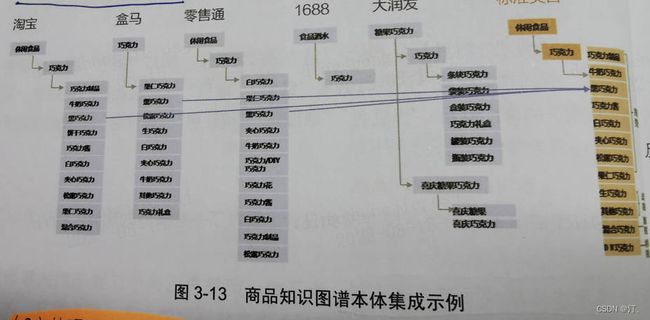
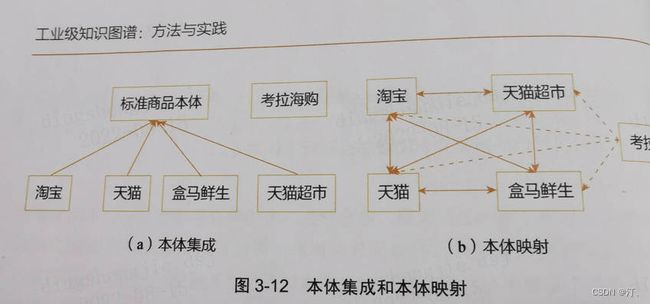
-
处理不同粒度的类对齐:关联规则
-
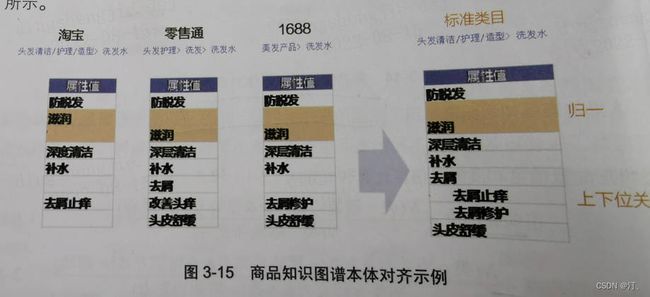
属性项分类:不同类别属性采取不同属性值对齐方式
-
基于层次结构的属性值体系:为了解决属性值划分粒度不同导致的属性值映射不成功问题

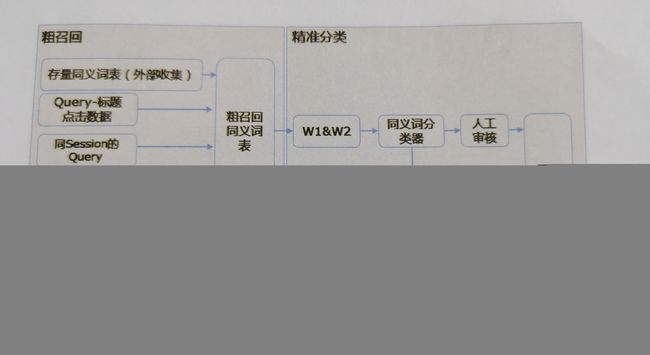
同义词发现算法:粗召回、精准分类

知识图谱本体对齐框架图
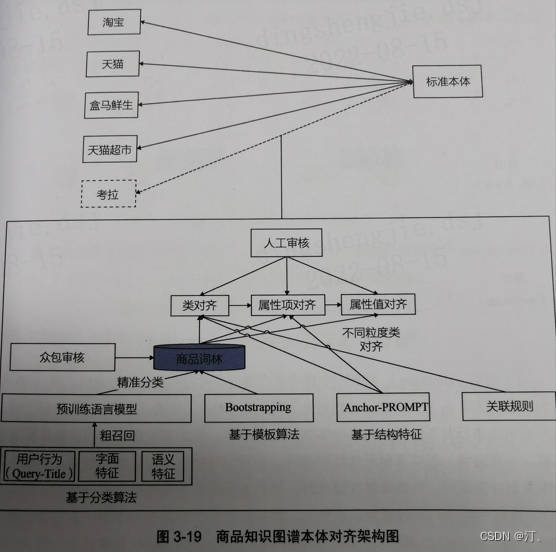
核心是:构建词林!
2.2 实体对齐
一般实体对齐实质两两对齐(pair-wise),但直接这么做会导致时间复杂度巨大难以计算,解决大规模实体对齐,流程一般采用分组和聚类
-
分组:按照一个或者多个属性对实体分组,只在组内进行对齐计算,跨组不进行聚类
-
聚类:
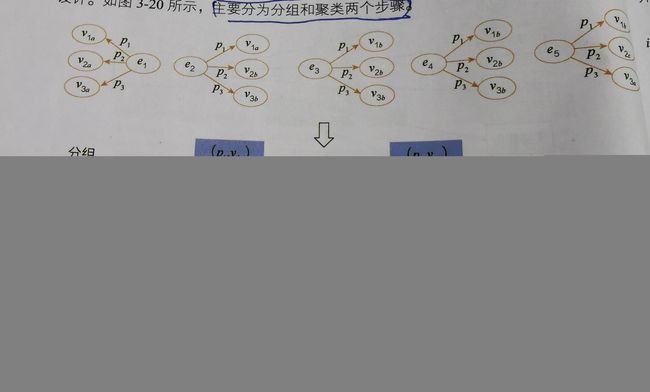
2.2.1 实体对齐技术路线
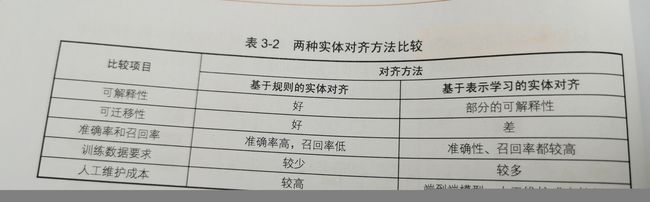
- 基于规则的实体对齐
关键属性对齐
拥有可解释性、准确率高迁移性好的优势,缺点不易迭代构建复杂
- 基于表示学习的实体对齐
邻居集合、通过词向量进行二分类或者聚类得到结果
基于基于规则的实体对齐
目前采用方法是小样本+深度学习反复迭代,通过标注样本数据学习到数据分布规则,通过在未标注数据上运行学习出来的规则。

基于表示学习的实体对齐
实体对齐可以看做二分类问题或者聚类问题
-
基于实体属性信息对齐
假设:两个实体属性越相似,实体越相似- 第一方法先计算两个实体相似度、再聚合成实体的相似度
- 第二种是先实体上各类属性对整个实体进行表示学习,在计算两个实体相似度
目前学术进展较快,预训练模型引入

- 基于实体拓扑信息的实体对齐
Deepwalk SDNE等网络表示学习算法以及Trans系列算法;图神经网络(GNN)。
通过图表示学习方法,把KG里的节点、属性、边表示在一个向量空间里。单个知识图谱是无监督的,已存在三元组是标注的信息,但是多个图谱的联合表示需要已经对齐的标注数据连接两个KG才能完成。
-
翻译类模型 TransE
-
序列模型:通过Deepwalk、RSN等模型进行随机游走得到一系列长序列采样,用LSTM Transformer等模型进行表示学习
-
图神经网络(最佳)
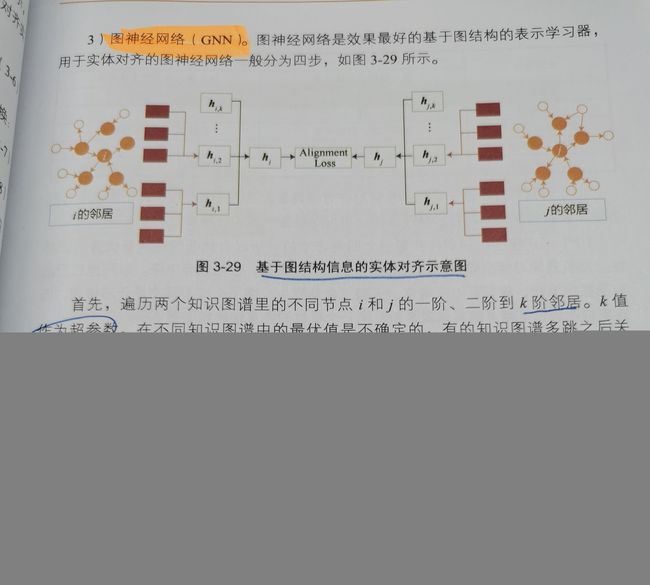
两种方法不是对立的,增加一个简单地聚合函数可以把两种特征信息结合起来
基于基于规则的实体对齐和基于表示学习的实体对齐两种方法对比
对于规则方法可以设计一种评分算法平衡不同实体的不同属性组合(见书本)
对于表示学习的采取transformer模型的自注意机制,并通过对偶神经网络对标题进行表示学习。
这里不推荐使用softmax分类损失函数,使用在人脸识别领域广泛使用的Triplet+LOSS函数,可以分别实体细微的差异。【通过人为干预训练数据将困难样本构建为负样例,更好的区分容易混淆的实体】
2.3信息融合
两大难点:噪声数据、异构问题
工业界信息融合问题难以获得训练数据,将采用无监督算法:投票算法、迭代算法、优化算法、概率图算法。
-
投票算法:简单,但缺点明显:每个信息源权重不同,置信度值需要专家判定,无法保证精准度。
-
迭代算法要求:假设不同数据源拥有不同的置信度(权重);依赖于数据源提供数据属性值的准确度。因此数据源的置信度和属性值的置信度是相互依赖变量,互相迭代直至收敛。
常见算法:TruthFinder算法和ACCU算法 -
基于优化模型:CRH算法
-
概率图:LTM算法
推荐采用小样本的半监督学习方法:SLiMFast算法
2.4 跨语言融合(待定)
2.5知识融合质量评估体系

2.5.1 离线融合效果评比
-
簇维度融合效果
-
节点维度融合效果
2.5.2在线融合
主要解决增量数据挂在问题
3.知识获取
输入数据源:结构化数据(连接数据、数据库数据)、半结构化数据(网页HTML、XML)、非结构化数据(文本、语音、图片)
输出结果:实体、实体概念、实体关系、事件关系、属性关系
核心子任务
-
命名实体识别(NER)
-
实体链接(EL)—对齐图谱
-
关系抽取(RE)
-
槽填充(SF slot Filling)

3.1 实体抽取
数据集(组织机构、人名):CoNLL2003、OneNotes、MSRA、Weibo
3.2实体链接
3.3 关系抽取
3.4 槽填充与关系补全
以上都推荐大模型去做
4 知识推理
知识推理一方面用于推理缺失或暗含的知识丰富知识图谱;另一方面可以检查知识库的不一致信息,进行知识清洗。
- 知识丰富
知识图谱中结构化知识往往是不完备的,需要用推理的方法预测表示实体之间新的关系,即链接预测任务
- 知识清洗
构建知识图谱过程中提取的数据存在数据质量和缺陷;常见方法:进行人工标注三元组进行准确率矫正,缺点标注成本高;其次随之时间推移,新的数据添加到KG中,假设旧版本KG已经评估过,不希望从头再次评估新的知识图谱准确性也是一个难点。
4.1基于符号的知识推理
基于本体的知识推理、基于本体描述语言的推理
4.2 基于规则的知识推理
基于规则的表示语言的推理
4.3 基于规则学习的知识谱推理
-
归纳逻辑编程[FOIL算法]、基于关联规则挖掘[AMIE算法]–可行(基于统计的方法不断往规则体增加约束实现)
-
图遍历([路径排序算法PRA]可解释性强,但在大规模知识图谱上性能瓶颈)
优点规则解释性强,缺点存在数据稀疏问题,在低连通知识图谱上难以抽取特征路径,十分耗时,在大规模KG无法使用。
改进方法: 1.特征融合,把TransE的预测分数和PRA预测分数作为新特征重新训练分类器;2.增加路径向量表示,Path-based TransE
- 表示学习的方法(大规模图谱有优势,可解释性不强。稀疏实体上效果较差)
4.3.1基于转移的表示学习:TransE、TransH、TransR、TransD
利用转移假设的评分函数,通过计算元素之间的距离对元组的合理性进行度量,评分函数越高,元组事实数据可能性越大。
上述方法都是使用不同的映射规则改造TransE的简单平移假设,改造模型都是基于L1和L2范数作为评分函数,不够灵活。
后续产出方法
- TransA:采用自适应马氏距离作为评分函数;
- KG2E:使用高斯分布表示实体和关系,通过KL散度和概率內积进行评分
- TransG:在解决关系多语义问题,对高斯分布实体进行建模
4.3.2基于矩阵分解的推理
略
4.3.3 基于表示学习的方法
EmbedRule模型、IterE模型
4.3.4 神经网络的知识推理
循环神经网络:Path——RNN模型(长文本性能减弱)
图神经网络:
- GCN图卷积网络;
- R-GCN;引入两类标准的知识图谱补全任务:1.链接预测 2.实体分类
- N-GCN:训练多个GCN组合成一个网络提升表达能力
- MixHop:对邻近关系表示,增加多跳关系
基于预训练模型的知识推理
在以往知识图谱向量表示模型中,往往只包含三元组信息,具有稀疏,缺乏大规模的其他文本语料信息。
KG-BERT:连接预测,三元组分类,关系分类多个任务;
具体来说将实体关系三元组当做文本句子;将知识图谱补全任务转化成序列分类任务,微调后的预训练模型预测三元组或某个关系概率。

5.知识图谱服务
KG在搜索、推荐、业务决策、问答系统。
搜索领域引用:

推荐领域
问答,
大规模预训练模型
BERT ERNIE
6.总结
目前自己对这块领域比较感兴趣。对下面两个核心技术进行归纳总结
1.知识融合是在知识图谱构建过程中经常遇到的,它是一个将多个知识库进行融合的过程。在整个过程中,会遇到异构、歧义、数据噪声及跨语言等问题。本体对齐章节,在实践中采用本体集成,并结合专家辅助的系统完成大规模的本体树融合。介绍了基于规则和基于表示学习方法的实体对齐,在信息融合部分,现阶段学界主要分为有监督和无监督两条技术路线。
2.知识推理: 随看知识图谱近年来的飞速发展,知识推理作为知识图谱补全和去噪的重要手段得到了广泛的关注。
补全和去噪是知识图谱中的两个基础任务:
-
当知识推理应用于知识图谱补全时,主要是指通过知识图谱中已有的信息理出缺失的三元组。例如,小明的毕业院校信息可能缺失,但通过分析发现明的同学大部分毕业于某个学校,那么可以推理出小明很可能也毕业于该学校。
-
去噪是指识别出知识图谱中的错误或矛盾的知识,这是一个非常重要的任务,因为错误的知识会影响知识图谱中的其他信息,造成错误放大,这对知识图谱来说是非常致命的、小型知识图谱上可以通过人工运营平台的方式完成去噪,但在大型知识图谱人工标注的成本非常高,因此需将自动化的知识推理方法应用其中。
在应用上知识推理已经在垂直搜索、智能问答、机器翻译、医疗、金融反欺诈和异常教等多个领域发挥了重要作用。
目前已在AIstudio公开了一些实体抽取、关系抽取、分类模型的方案,感兴趣同学可以fork。
https://aistudio.baidu.com/aistudio/usercenter
个人博客:https://blog.csdn.net/sinat_39620217?type=blog