使用ML.NET+ONNX预训练模型整活B站经典《华强买瓜》
目录
前言
环境准备
操作流程
总结
前言
最近在看微软开源的机器学习框架ML.NET使用别人的预训练模型(开放神经网络交换格式.onnx)来识别图像,然后逛github发现一个好玩的repo。决定整活一期博客。
首先还是稍微科普一下机器学习相关的知识,这一块.NET虽然很早就开源了ML.NET框架,甚至在官方的ML.NET开源之前,就有一些三方社区的开源实现比如早期的AForge.NET实现。以及后来的基于python著名的神经网络框架tensorflow迁移的tensorflow.net亦或者是pytorch迁移的torchsharp来实现C#版本的深度学习,但是毕竟C#确实天生并不适合用来搞机器学习/深度学习,AI这一块也一直都是python的基本盘。但是不适合并不代表没有方案,现在AI逐渐普及的今天,我们普通的开发者依然可以使用一些别人训练好的模型来做一些应用落地。
环境准备
今天我们会用到一些训练好的模型来实现我们的目的,需要准备以下环境和工具:
1、安装有.NET5或者6的windows开发环境
2、netron 用于解析模型的参数。
下载地址:https://t.ly/8iEk8
3、ffmpeg 用于视频处理
下载地址:https://t.ly/ro0G
4、onnx预训练udnie、super-resolution
udnie模型
下载地址:https://t.ly/0cUt
super-resolution模型
下载地址:https://t.ly/rnsi(需要解压提取内部的onnx文件)
操作流程
1、首先我们将目标视频(我这里就用B站经典短视频《华强买瓜》为例)通过ffmpeg转换成普通的一帧一帧的图片
2、通过ML.NET加载【神经风格转换预训练模型】将每一帧原图迁移到新的风格(艺术风格:udnie,抽象主义)。
3、由于2只能将图片迁移到固定的240240格式,所以我们还需要通过ML.NET加载【超分辨率预训练模型】将每一帧图片进行超分辨率放大得到一张672672的图片
4、通过ffmpeg将新的图片合并成新的视频
首先先看看成品(这里我转换成gif方便演示):
原版视频《华强买瓜》 1280*720
迁移后的抽象艺术版本 224*224

超分辨放大后的版本 672*672
接着我们看看如何一步一步来实现这个流程的
首先我们新建一个空白文件夹,将下载好的ffmpeg.exe和准备要处理的mp4视频文件放进这个空白文件夹
接着我们需要从视频中分离音频文件,用于后期合成视频时把音频合成回去,否则视频会没有声音,打开控制台CD到刚才的目录,执行命令:
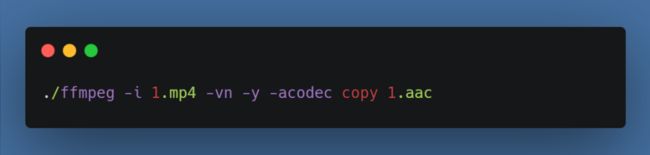
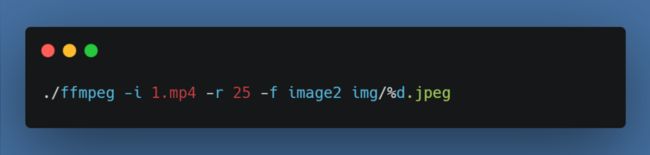
然后我们从视频中将每一帧拆解成一张一张的jpg图片,这里首先要创建一个img子文件夹,否则会报错。另外我选择的r 25意思就是每秒25帧。如果你的视频不是每秒25帧(右键-属性-详细信息-帧速率)则自行根据文件调整,最后合成的时候也需要按照这个帧率合成新的视频:
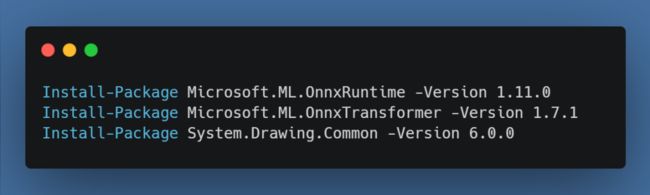
到这里为止,我们就将图片和音频拆解出来了,接下来准备编码,首先我们打开VS创建一个控制台程序,引入nuget包:
接着我们创建一个一个类文件用于加载模型以及完成相应的图片处理,在此之前我们需要使用安装好的netron来打开这两个onnx模型,查询他们的输入输出值,打开netron选择file-open,然后选择第一个模型udnie-9.onnx,点击input,可以看到右边已经展示出了这个模型的输入和输出项,接着我们创建类的时候,这里需要这一些数字。
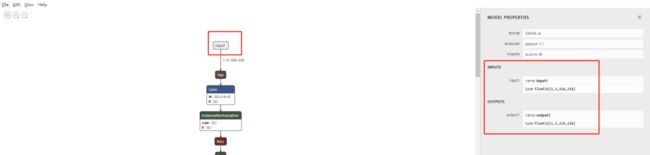
接着我们打开VS创建好的项目,把我们的两个onnx模型引入进去。接着编写如下代码:
首先定义一个session用于加下onnx模型
static InferenceSession styleTransferSession = new InferenceSession("model/udnie-9.onnx");接着我们创建一个方法调用这个模型
public static Bitmap ProcessStyleTransfer(Bitmap originBmp)
{
//根据netron得到的input,我们在这里构建对应的输入张量
var input = new DenseTensor(new[] { 1, 3, 224, 224 });
//将bitmap转换成input
Tool.BitmapToTensor(originBmp, 224, 224, ref input, true);
//接着调用模型得到迁移后的张量output
using var results = styleTransferSession.Run(new[] { NamedOnnxValue.CreateFromTensor("input1", input) });
if (results.FirstOrDefault()?.Value is not Tensor output)
throw new ApplicationException("无法处理图片");
//由于模型输出的是3*224*224的张量,所以这里只能构建出224*224的图片
return Tool.TensorToBitmap(output, 224, 224);
}
其实到这一步神经风格迁移就完成了,最后的bitmap就是迁移后的新图片,我们只需要调用bitmap.save即可保存到磁盘上
接着我们创建超分辨率模型的方法来,其实同上面的调用非常类似的代码
这里唯一需要注意的是超分辨率提取并非采用RGB直接放大,而是用了YCbCr来放大,所以这里需要有一个转换,原文在这里:https://github.com/onnx/models/tree/main/vision/super_resolution/sub_pixel_cnn_2016
static InferenceSession superResolutionSession = new InferenceSession("model/super_resolution.onnx");public static Bitmap ProcessSuperResolution(Bitmap originBmp)
{
//根据netron得到的input,我们在这里构建对应的输入张量,由于该模型并非采用RGB而是YCbCr,所以中间会做一些转换,不过整体流程和上一个类似
var input = new DenseTensor(new[] { 1, 1, 224, 224 });
//将bitmap转换成input
Tool.BitmapToTensor(originBmp, 224, 224, ref input, true);
//由于模型处理Y值,剩下的Cb和Cr需要我们单独调用System.Drawing.Common双三次插值算法放大得到对应的Cb和Cr值
var inputCbCr = new DenseTensor(new[] { 1, 672, 672 });
inputCbCr = Tool.ResizeGetCbCr(originBmp, 672, 672);
//接着调用模型得到超分重建后的张量output
using var results = superResolutionSession.Run(new[] { NamedOnnxValue.CreateFromTensor("input", input) });
if (results.FirstOrDefault()?.Value is not Tensor output)
throw new ApplicationException("无法处理图片");
//创建一个新的bitmap用于填充迁移后的像素,这里需要通过Y+CbCr转换为RGB填充
return Tool.TensorToBitmap(output, 224, 224,false, inputCbCr);
} 其实基本上到这两步,我们的整个核心代码就完成了。剩余的部分只是一些图片处理的代码。接着我们要做的就是在Program.cs调用它得到迁移后的图片
Directory.CreateDirectory("new img path");
foreach (var path in Directory.GetFiles("old img path"))
{
//由于ffmpeg拆帧后的图片就是按照帧率从1开始排序好的图片,所以我们只需要将上一层的文件夹名字修改一下即可得到要替换的新文件路径 like: D://img/1.jpeg -> D://newimg/1.jpeg
var newpath = path.Replace("old img path", "new img path");
using var originBitmap = new Bitmap(Image.FromFile(path));
using var transferBitmap = OnnxModelManager.ProcessStyleTransfer(originBitmap);
using var reSizeBitmap = OnnxModelManager.ProcessSuperResolution(transferBitmap);
reSizeBitmap.Save(newpath);
}接着F5 run,然后静待,一般要转换20分钟左右(cpu i5)基本就转换完成了。最后我们只需要再使用工具合成新的视频(或者gif)
./ffmpeg -f image2 -i newimg/%d.jpeg -i 1.aac -map 0:0 -map 1:a -r 25 -shortest output.mp4internal class Tool
{
///
/// 将bitmap转换为tensor
///
///
/// input, bool toRGB)
{
using var inputBmp = new Bitmap(resizeWidth, resizeHeight);
using Graphics g = Graphics.FromImage(inputBmp);
g.DrawImage(originBmp, 0, 0, resizeWidth, resizeHeight);
g.Save();
for (var y = 0; y < inputBmp.Height; y++)
{
for (var x = 0; x < inputBmp.Width; x++)
{
var color = inputBmp.GetPixel(x, y);
if (toRGB)
{
input[0, 0, y, x] = color.R;
input[0, 1, y, x] = color.G;
input[0, 2, y, x] = color.B;
}
else
{
//将RGB转成YCbCr,此处仅保留Y值用于超分辨率放大
var ycbcr = RGBToYCbCr(color);
input[0, 0, y, x] = ycbcr.Y;
}
}
}
}
///
/// 将tensor转换成对应的bitmap
///
///
/// output, int width, int height, bool toRGB = true, Tensor inputCbCr = null)
{
//创建一个新的bitmap用于填充迁移后的像素
var newBmp = new Bitmap(width, height);
for (var y = 0; y < newBmp.Height; y++)
{
for (var x = 0; x < newBmp.Width; x++)
{
if (toRGB)
{
//由于神经风格迁移可能存在异常值,所以我们需要将迁移后的RGB值确保只在0-255这个区间内,否则会报错
var color = Color.FromArgb((byte)Math.Clamp(output[0, 0, y, x], 0, 255), (byte)Math.Clamp(output[0, 1, y, x], 0, 255), (byte)Math.Clamp(output[0, 2, y, x], 0, 255));
newBmp.SetPixel(x, y, color);
}
else
{
//分别将模型推理得出的Y值以及我们通过双三次插值得到的Cr、Cb值转换为对应的RGB色
var color = YCbCrToRGB(output[0, 0, y, x], inputCbCr[0, y, x], inputCbCr[1, y, x]);
newBmp.SetPixel(x, y, color);
}
}
}
return newBmp;
}
///
/// RGB转YCbCr
///
public static (float Y, float Cb, float Cr) RGBToYCbCr(Color color)
{
float fr = (float)color.R / 255;
float fg = (float)color.G / 255;
float fb = (float)color.B / 255;
return ((float)(0.2989 * fr + 0.5866 * fg + 0.1145 * fb), (float)(-0.1687 * fr - 0.3313 * fg + 0.5000 * fb), (float)(0.5000 * fr - 0.4184 * fg - 0.0816 * fb));
}
///
/// YCbCr转RGB
///
public static Color YCbCrToRGB(float Y, float Cb, float Cr)
{
return Color.FromArgb((byte)Math.Clamp(Math.Max(0.0f, Math.Min(1.0f, (float)(Y + 0.0000 * Cb + 1.4022 * Cr))) * 255, 0, 255),
(byte)Math.Clamp(Math.Max(0.0f, Math.Min(1.0f, (float)(Y - 0.3456 * Cb - 0.7145 * Cr))) * 255, 0, 255),
(byte)Math.Clamp(Math.Max(0.0f, Math.Min(1.0f, (float)(Y + 1.7710 * Cb + 0.0000 * Cr))) * 255, 0, 255)
);
}
///
/// 双三次插值提取CbCr值
///
public static DenseTensor ResizeGetCbCr(Bitmap original, int newWidth, int newHeight)
{
var cbcr = new DenseTensor(new[] { 2, newWidth, newHeight });
using var bitmap = new Bitmap(newWidth, newHeight);
using var g = Graphics.FromImage(bitmap);
g.InterpolationMode = InterpolationMode.HighQualityBicubic;
g.SmoothingMode = SmoothingMode.HighQuality;
g.DrawImage(original, new Rectangle(0, 0, newWidth, newHeight),
new Rectangle(0, 0, original.Width, original.Height), GraphicsUnit.Pixel);
g.Dispose();
for (var y = 0; y < bitmap.Width; y++)
{
for (var x = 0; x < bitmap.Height; x++)
{
var color = bitmap.GetPixel(x, y);
var ycbcr = RGBToYCbCr(color);
cbcr[0, y, x] = ycbcr.Cb;
cbcr[1, y, x] = ycbcr.Cr;
}
}
return cbcr;
}
} 总结
这一期整活基本到此就结束了,虽然只是调用了两个小模型搞着玩,但是其实只要能搞到业界主流的开源预训练模型,其实可以解决很多实际的商业场景,比如我们最近在使用美团开源的yolov6模型做一些图像对象检测来落地就是一个很好的例子这里就不再展开。另外微软也承诺ML.NET的RoadMap会包含对预训练模型的迁移学习能力,这样我们可以通过通用的预训练模型根据我们自己的定制化场景只需要提供小规模数据集即可完成特定场景的迁移学习来提高模型对特定场景问题的解决能力。今天就到这里吧,下次再见。
作者:a1010
原文:https://www.cnblogs.com/gmmy/p/16433499.html