机器学习项目实战——03逻辑回归算法之用户流失预测
数据集采用的是真实数据集。对于数据集的说明如下:

可以看出:这个属于分类问题,并且对于预测值只有0和1,属于二分类问题,一般采用逻辑回归。
但是逻辑回归可能效果不好,后续在讲如何提高分类准确率。
观察数据集:
第一列、第二列、第三列与最后的预测值无关。因此可在处理时删除这三列。
x_train = np.delete(x_train,[0,1,2],axis=1)
x_test = np.delete(x_test,[0,1,2],axis=1)另外,对于国家和用户性别两列是字符串形式,要转换成数字形式才能计算
from sklearn.preprocessing import LabelEncoder
labelencoder1 = LabelEncoder()
x_train[:,1] = labelencoder1.fit_transform(x_train[:,1])
x_test[:,1] = labelencoder1.transform(x_test[:,1])
labelencoder2 = LabelEncoder()
x_train[:,2] = labelencoder2.fit_transform(x_train[:,2])
x_test[:,2] = labelencoder2.transform(x_test[:,2])最后,将所有的字符串类型转换成float类型进行计算,相当于去掉双引号
x_train = x_train.astype(np.float32)
x_test = x_test.astype(np.float32)
y_train = y_train.astype(np.float32)
y_test = y_test.astype(np.float32)完整代码如下:
import numpy as np
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
# 数据集里面含有字符串,如果不定义dtype=np.str,则读取出来的数据为null
train_data = np.genfromtxt('Churn-Modelling.csv',delimiter=',',dtype=np.str)
test_data = np.genfromtxt('Churn-Modelling-Test-Data.csv',delimiter=',',dtype=np.str)
# 切分数据
x_train = train_data[1:,:-1] #行取第一行到最后,列取第0列到倒数第二列
y_train = train_data[1:,-1].astype(int)
x_test = test_data[1:,:-1]
y_test = test_data[1:,-1].astype(int)
# 预处理删除无关的三列axis=1删除列、axis=0则删除行
x_train = np.delete(x_train,[0,1,2],axis=1)
x_test = np.delete(x_test,[0,1,2],axis=1)
print(x_train[:5])
print(y_train[:5])
# 另外,对于国家和用户性别两列是字符串形式,要转换成数字形式才能计算
labelencoder1 = LabelEncoder()
x_train[:,1] = labelencoder1.fit_transform(x_train[:,1])
x_test[:,1] = labelencoder1.transform(x_test[:,1])
labelencoder2 = LabelEncoder()
x_train[:,2] = labelencoder2.fit_transform(x_train[:,2])
x_test[:,2] = labelencoder2.transform(x_test[:,2])
print(x_train[:5])
# 将所有的字符串类型转换成float类型进行计算,相当于去掉双引号
x_train = x_train.astype(np.float32)
x_test = x_test.astype(np.float32)
y_train = y_train.astype(np.float32)
y_test = y_test.astype(np.float32)
# 数据标准化处理,均值化
sc = StandardScaler()
x_train = sc.fit_transform(x_train)
x_test = sc.transform(x_test)
print(x_train[:5])
# 模型训练
LR = LogisticRegression()
LR.fit(x_train,y_train)
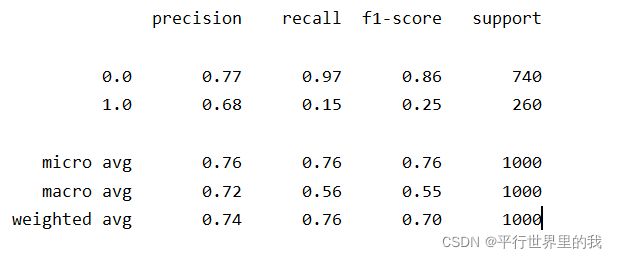
predictions = LR.predict(x_test)
print(classification_report(y_test, predictions))最终结果,用LR得到的结果不是很好,大概准确率只有74