【漫漫转码路】Day 36 C++ day07
链表
常态化写法student s1, s2, s3;是有作用域的,出了作用域,就不能作用了,因此在应用中常常把他写成内存块的形式
//例如
struct student
{
char name[256];
int age;
float score;
student *pNext;
};
int main()
{
student* s1, * s2, * s3;
s1 = new student();
s2 = new student();
s3 = new student();
strcpy(s1->name, "Tom");
s1->age = 16;
s1->score = 90;
strcpy(s2->name, "Bob");
s2->age = 17;
s2->score = 80;
strcpy(s3->name, "Jack");
s3->age = 14;
s3->score = 70;
s1->pNext = s2;
s2->pNext = s3;
s3->pNext = nullptr;
}
此时,s1, s2, s3不再受作用域的影响
尾插添加一个学生
//例如
void addstudent(student* pin, student in)
{
if (pin == nullptr)
{
return;
}
if (pin->pNext == nullptr)
{
student* p = new student(); //新建一个new出来,不用考虑作用域的问题了
strcpy(p->name, in.name); //然后将要插入的in的东西都放到new里面去
p->age = in.age;
p->score = in.score;
p->pNext = nullptr; //p的最后设置为空
pin->pNext = p;
}
else
{
addstudent(pin->pNext, in);
}

内存的四个特点
内存泄漏: 在创建多个new之后,没有delete,导致内存越来越小,大导致程序运行缓慢或崩溃
小数据内存碎片化: 频繁的new及delete,比如一次new1000个内存,delete500个内存,然后又new200个,delete100个,会导致内存的块越来越碎片化,会导致操作系统越来越卡
内存分配失败: 内存不足,返回空指针;
内存释放后不可再使用: new的内存,在释放之后,无法再次对其进行操作
释放链表
因为链表某一个结构体释放完之后就无法访问,因此需要先用一个临时变量,将下一个指针存下来,然后将本结构体释放,递归到下一个结构体
//例如
void freestudent(student* p)
{
if (p == nullptr)
return;
if (p->pNext == nullptr)
{
delete p;
}
else
{
student* m = p->pNext;
delete p;
freestudent(m);
}
}
浅拷贝
//例如
student *p5 = p1; //这里p5等于p1是浅拷贝,只拷贝p1,没有拷贝整个链表
深拷贝
拷贝一张链表
//例如
student* deepcopy(student* in)
{
if (in == nullptr)
return nullptr;
student* m = new student();
strcpy(m->name, in->name);
m->age = in->age;
m->score = in->score;
m->pNext = deepcopy(in->pNext);
return m;
}
文件操作
导入
# include写
//例如
int main()
{
char a[256] = "i am a student!"; // 定义一个字符串变量
FILE* fp = fopen("D:\\1.txt", "w"); //
fwrite(a, 256, 1, fp);
fclose(fp);
}
FILE表示声明一个文件指针;
fopen表示打开(新建或覆盖)一个文件;
“w”表示写入模式打开;
fwrite(a, 256, 1, fp)中,a表示要写入的内容的首地址,256表示占多少内存,1表示写入1遍,fp表示写入到哪个文件;
fclose(fp)表示关闭文件;
这样,一个文件就新建了,并且写入了一行字母
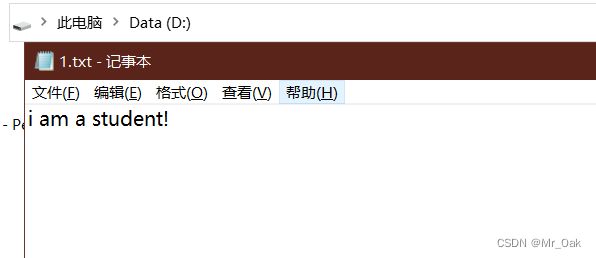
//例如
int main()
{
char a[256] = "i am a student!";
FILE* fp = fopen("D:\\1.txt", "w");
fwrite(a, 4, 1, fp); //a不止4个字节,但是只写入四个字节
fclose(fp);
}

读
//例如
int main()
{
char a[256] = "i am a student!";
FILE* fp = fopen("D:\\1.txt", "w");
fwrite(a, 256, 1, fp);
fclose(fp);
char b[256]; //新建一个字符串来获取读到的内容
FILE* fp2 = fopen("D:\\1.txt", "r"); //w换成r
fread(b, 256, 1, fp2); // 读取的操作也是一样的
fclose(fp);
cout << b;
}
//显示
i am a student!
二进制读写字节流
更为常用,可以显示不可见的字符
w和r会将不可见的内容都过滤掉
wb和rb不会
//例如
int main()
{
student s1;
strcpy(s1.name, "apple");
s1.age = 16;
s1.score = 60;
FILE* fp = fopen("D:\\1.txt", "wb");
fwrite(&s1, sizeof(student), 1, fp);
fclose(fp);
student s2;
FILE* fp2 = fopen("D:\\1.txt", "r");
fread(&s2, sizeof(student), 1, fp2);
fclose(fp);
}
结构体之类的类型,只能用二进制来写
连续写入不会覆盖前面的数据
就是fopen一次,然后后面是多个fwrite,不会覆盖
fseek,对文件进行定位,比如从第n个自己开始写
ftell,获得当前文件位置
一般文件会在开始位置写清楚内容的数量
宏定义
#+define+名称+内容
会被自动编译
//例如
#define PI 3.1415926
// 自动编译成float PI = 3.1415926;
int main()
{
cout << PI;
}
//显示
3.14159
宏支持参数
//例如
#define PI 3.1415926
#define Max(a,b) (a>b ?a:b) //支持参数,
// 自动编译成float PI = 3.1415926;
int main()
{
cout << Max(3,5);
}
//显示
5
(a>b ?a:b):如果a>b,返回a,否则返回b
宏和函数的区别
宏是替换的
函数是调用的
宏支持强制类型转换
对于一些小的函数,可以直接用宏来写,可以省去很多函数重载