EMNLP19论文笔记1111-1117
A Gated Self-attention Memory Network for Answer Selection(EMNLP19)
存在问题:现有方法在前几层将问题候选词对编码为向量化后的序列,由于这些序列的独立导致完全忽略了其他序列的信息。
提出一种基于两种方法的混合的方法,一种memory network 和自注意力结构。即基于memory的门自注意力网络结构来在QA中进行答案提取。
1.提出gated self-attention mechanism,使其不只是适用于单个输入和上下文向量,而是适用于所有序列。因而改变f的输入。首先将输入和上下文向量表示为独立的gate–vote,再将其聚合来计算输入 x i x_i xi的gate g i g_i gi,具体过程如下。
v j = W x j + b ; v c = W c + b ; s i j = x i T v j ; s i c = x i T v c v^j =Wx_j + b;v^c =Wc + b; s^j_i = x^T_iv^j ; s^c_i = x^T_iv^c vj=Wxj+b;vc=Wc+b;sij=xiTvj;sic=xiTvc
α i j = e x p ( s i j ) ∑ k ∈ [ 1.. n ] e x p ( s i k ) + e x p ( s i c ) ; α i c = e x p ( s i c ) ∑ k ∈ [ 1.. n ] e x p ( s i k ) + e x p ( s i c ) \alpha _i^j =\frac{exp(s^j_i )}{\sum_{k\in {[1..n]}}exp(s^k_i )+exp(s^c_i) }; \alpha _i^c =\frac{exp(s^c_i )}{\sum_{k\in {[1..n]}}exp(s^k_i )+exp(s^c_i) } αij=∑k∈[1..n]exp(sik)+exp(sic)exp(sij);αic=∑k∈[1..n]exp(sik)+exp(sic)exp(sic)
g i = f i ( c , X ) = σ ( ∑ j ( α i j x j ) + α i c c ) g_i = f_i(c, X)=\sigma (\sum_{j}(\alpha _i^jx^j)+\alpha _i^c c) gi=fi(c,X)=σ(∑j(αijxj)+αicc)
本质在于将两个向量同时融入到attention机制中,由于这里上下文向量只有一个,因而在权重\alpha 中和sigmoid计算了一次。
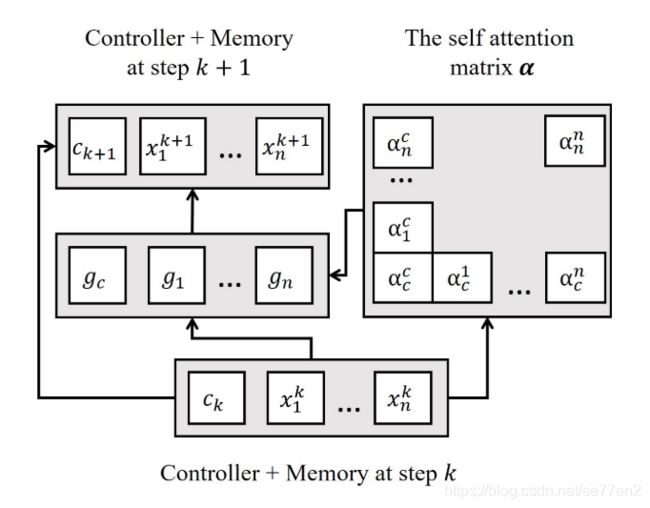
2.In most previous memory network architectures, interactions between memory cells are relatively limited. At each hop, a single control vector is used to interpret each memory cell independently.在大多数先前的存储器网络架构中,存储器单元之间的交互是相对受限的。 在每个跃点处,单个控制向量用于独立地解释每个存储单元。因而以上提出的结构即可得到应用。第k hop的 每个细胞的更新即可如上述方法计算。
而c的更新则为:

不想再敲一遍了
以上为主要结构,当其应用到QA中,即将Q和A连接一起然后,进行2分类得到是否匹配结果。因而也可认为是分类任务。假设c_T为最终控制态。即最终的分类结果由概率来决定。
P ( A ∣ Q ) = σ ( W C c T + b c ) P(A|Q)= \sigma(W_Cc_T +b_c) P(A∣Q)=σ(WCcT+bc)
其简单结构如下:
文中还提到了简单的迁移学习。即在stackexchangQA数据集上先进行模型训练,再微调在目标集上训练的相同模型。实际上主要是填充文章用的,感觉没什么卵用。
Sequential Learning of Convolutional Features for Effective Text Classification (EMNLP19)
在文本任务中,单词之间的顺序模式和语义结构在确定文本的类别方面起着至关重要的作用,但传统的词典方法无法捕捉到这种复杂性。很多CNN模型随着深度学习发展得以提出,同时现有的CNN仍存在一些问题,如序列的信息是否在卷积传递的时候保存完好,使用maxpooling也会导致由池化得到的模型是否是输入最重要的特征。
因而,本文从以上问题出发,提出一种新的递归卷积模型来克服以上问题。(卷积操作以及池化)
通过实验和分析,来诠释卷积和池化带来的信息损失。
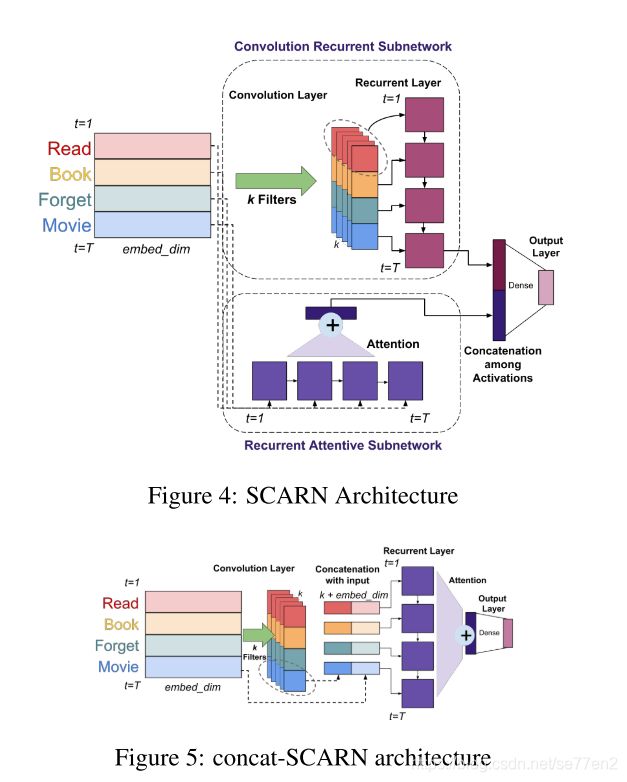
该模型包含两个子网络:一个卷积递归网络一个递归注意力网络。
卷积递归网络:
输入I通过卷积层得到高阶表示根据卷积核数变为k维,然后将高阶表达送入LSTM,输出最后一层的表达
递归注意力网络:
直接将其输入LSTM,将LSTM进行attention聚合然后与上面输出进行拼接,最后通过dense层来输出结果。
另一种结构则是直接卷积,再将卷积结果与embd拼接,再通过LSTM+Attention+Dense来预测结果。
感觉对于CNN的批评只是作为模型的粉饰,模型本身十分简单。
Reconstructing Capsule Networks for Zero-shot Intent Classification(EMNLP19)
一种用于零样本学习的意图分类网络模型。
逻辑:首先说明意图分类在对话系统中的重要性,然后从对话系统无法短时间处理大量信息,从而引出零样本学习。接着从近期SOTA的模型入手,阐述其存在的相关问题。(1)语义胶囊提取中无法处理词的多义性。(2)几乎无法识别零样本分类器中未见过意图的语句。从这两个不足出发,来引出自己的分类器。介绍自己模型的两个优点。(1)提出尺寸的注意力机制来对多义性进行处理。(2)利用标签语句中的隐藏信息重建转换矩阵。
图简介:训练阶段,将标记语句送入提取特征的语音胶囊然后通过矩阵转换加动态路由,与已经有的label进行训练。测试阶段,为了预测未知的意图,通过标记语句与已知标记的embd来学习相似度,然后相似度与训练得到的W_{kr}结合来建立预测未知信息的转换矩阵 W t r W_{tr} Wtr。
当测试语句到达,首先会通过特征提取胶囊。此时有两个设定。(1)零样本分类:即只有未见过的语句,此时只.有W_{tr}被使用。(2)广义零样本分类:数据可能来自已知样本和未知样本,此时两个转换矩阵都会同时用到。
1.尺度注意力胶囊网络
首先双向LSTM连接得到 H = [ h 1 , h 2 , . . h T ] ∈ R 2 d h × T H=[h_1,h_2,..h_T]\in \mathbb{R}^{2d_h\times T} H=[h1,h2,..hT]∈R2dh×T,代表T个语句的双向LSTM结果的集合,然后通过 A r = s o f t m a x ( F 2 R E L U ( F 1 H ) ) A_r=softmax(F_2RELU(F_1H)) Ar=softmax(F2RELU(F1H)),求得尺度注意力矩阵,然后特征就由
m r = ∑ r o w ( A r ⊙ H ) m_r = \sum_{row}(A_r\odot H) mr=∑row(Ar⊙H),即两者叉乘后将其按行求和得到最终的特征矩阵M。
然后通过 p k ∣ r = W k r m r p_{k|r} = W_{kr}m_r pk∣r=Wkrmr来得到预测向量,再由有K个胶囊得到每个胶囊的输出, o k = ∑ r = 1 R c k r p k ∣ r o_k =\sum_{r=1}^Rc_{kr}p_{k|r} ok=∑r=1Rckrpk∣r,其中c表示耦合系数,通过动态路由得到 v k v_k vk。
v k v_k vk即为预测出的向量,同时提出一种新的loss function ,即结合来源于别人论文的 L 1 L_1 L1与attention矩阵的转置乘减单位矩阵,即
L t o t a l = ∑ k = 1 K { y k m a x ( 0 , m + − ∣ ∣ v k ∣ ∣ ) + λ ( 1 − y k ) m a x ( 0 , ∣ ∣ k ∣ ∣ − m − ) } + β ∣ ∣ S ⊤ S − I ∣ ∣ F 2 L_{total}= \sum_{k=1}^K{\{y_kmax(0,m^+-||v_k||)\\+\lambda (1-y_k)max(0,||k||-m^-)\}}\\+\beta||S^{\top}S-I||_F^2 Ltotal=∑k=1K{ykmax(0,m+−∣∣vk∣∣)+λ(1−yk)max(0,∣∣k∣∣−m−)}+β∣∣S⊤S−I∣∣F2
核心模块即为尺度注意力模块,通过该模块缓解了词的多义性的问题,同时应用胶囊网络来提取k个标签的胶囊来进行动态路由,最后根据尺度注意力模块的特点,改变损失函数,也是创新之一。
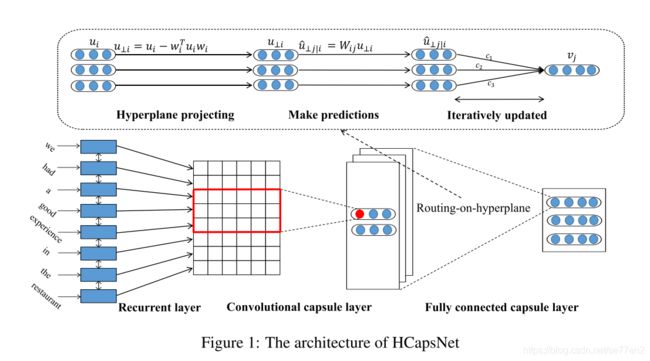
Investigating Capsule Network and Semantic Feature on Hyperplanes for Text Classification(EMNLP19)
一篇与上文相似的胶囊网络模型,不同点在于,该篇的动态路由算法中加入了‘routing-on-hyperplane’的超平面路由的机制,来改善动态路由的效果。其思想在于,在激活下一层胶囊时,通过可训练的超平面来对上一次的输出来进行筛选。对于胶囊i,定义矩阵W_i^h,用于产生w_i,具体流程如下:
w i = W i h u i , u ⊥ i = u i − w i ⊤ u i w i w_i = W_i^hu_i, u_{\perp i} = u_i -w_i^{\top}u_iw_i wi=Wihui,u⊥i=ui−wi⊤uiwi
然后 u ⊥ i u_{\perp i} u⊥i,等同于上篇文章中的 p k ∣ r p_{k|r} pk∣r,其他运算也基本相同,总的来说,其动态选择的方式并没有改变,而只是改变了其输入。其惩罚项,则是用各个超平面的正则向量来构造,等同于上文的S。附上模型图。