MobilenetV2学习笔记 --- MobileNetV2: Inverted Residuals and Linear Bottlenecks
论文:https://arxiv.org/abs/1801.04381
代码:https://github.com/tonylins/pytorch-mobilenet-v2
此外给出MobilenetV1论文链接:https://arxiv.org/abs/1704.04861
没有看过MobilenetV1的建议先去看看。
MobilenetV1
利用深度可分离卷积代替标准卷积,大大减少了模型计算量。
基本思想:将标准卷积拆分为两个分卷积:第一层称为深度卷积(depthwise convolution),对每个输入通道应用单通道的轻量级滤波器;第二层称为逐点卷积(pointwise convolution),负责计算输入通道的线性组合构建新的特征。
深度可分离卷积对比标准卷积的参数量计算请看:https://blog.csdn.net/c2250645962/article/details/102625943
两者计算量比较结果如下:

K - 卷积核尺寸
C_out - 输出通道数
MobilenetV2是基于MobilenetV1改进而来的。MobileNetV2中使用的卷积核大小k=3,与标准卷积相比计算量减少了8~9倍。
MobileNetV2
创新点
- Linear Bottlenecks
在 bottleneck 的最后一个 1x1 conv 层,把ReLU函数替换为Linear 线性函数,以防止ReLU破坏特征。如下图
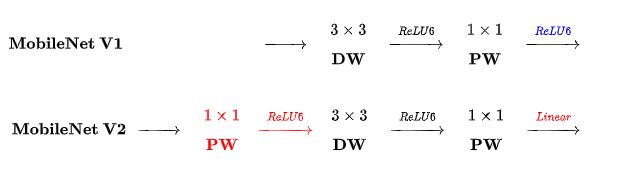
图中的ReLU6指的是ReLU6就是普通的ReLU但是限制最大输出值为6(对输出值做clip)。
该创新点主要是与MobilenetV1进行比较得来的。
MobilenetV2在DW层之前添加多一个PW层,这样做的原因是 DW 卷积由于本身的计算特性决定它自己没有改变通道数的能力,上一层给它多少通道,它就只能输出多少通道。那么如果输入通道数很少的话,DW就只能对很少的通道数进行操作,这样回限制后面抽取的特征性能。为了解决这个问题,MobilenetV2在DW前添加PW层,目的是为了提升通道数,获得更多特征。
此外,作者根据实验认为,激活函数在高维空间能够有效的增加非线性,而在低维空间时则会破坏特征,不如线性的效果好。由于深度可分离卷积的第二个pointwise convolution操作主要是降维,所以降维之后就不宜用ReLU了。
- Inverted residuals
传统的residual 加shortcut,目的是:提高梯度跨层传播的能力。而反向设计大大提高了内存效率。
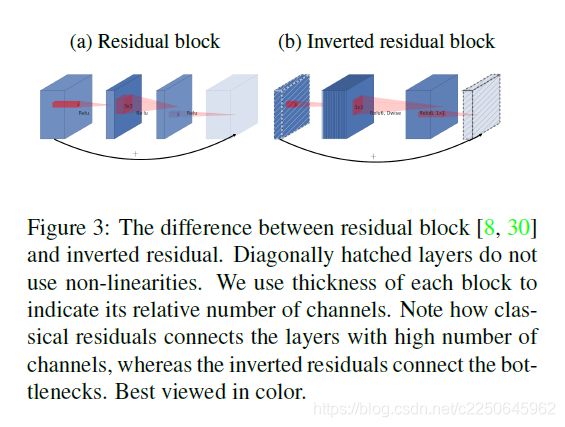
图中带有对角斜线的层没有使用非线性(与第一个创新点对应),用厚度来表示每个block的输入通道。
由图可以看到,传统的residual block输入通道数是比较大的,然后将数据降维(1 * 1卷积),在经过3 * 3 标准卷积抽取特征,最后将数据升维(1*1卷积),即输入特征 -> 压缩 -> 提特征 -> 扩张。
然而,Inverted residual block是输入通道数很少,然后将数据扩张(1 * 1卷积),在经过3 * 3 DW卷积抽取特征,最后使用1 *1 PW卷积将数据压缩,即输入特征 -> 扩张 ->提特征 -> 压缩
这个过程刚好和residual相反,所以叫inverted residual (倒置残差块)。
这么做也是因为.DW 层提取得到的特征受限于输入的通道数,如果使用传统的residual方法,那么可提取的特征就太少了,作者希望特征提取能够在高维进行。
网络结构
综上,那么MobilenetV2的Bottleneck residual block tablet如下,也对应了输入特征 -> 扩张 ->提特征 -> 压缩和Bottleneck最后激活函数改为Linear。

t - 扩展因子,h * w - 输入feature map尺寸, k - 输入通道数。
MobilenetV2完整的网络结构如下:
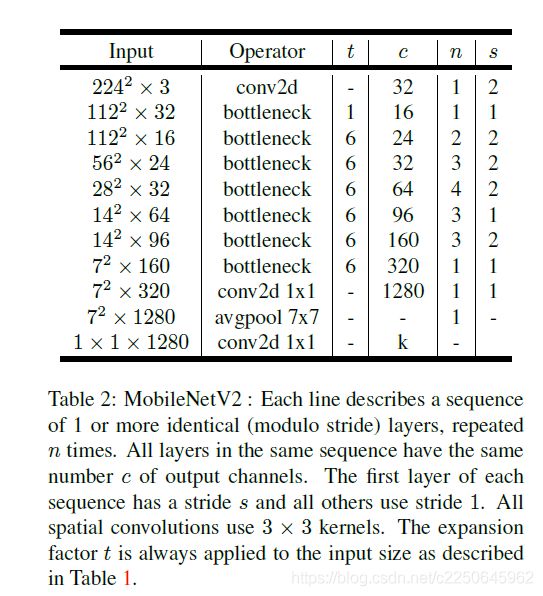
其中:t表示“扩张”倍数,c表示输出通道数,n表示重复次数,s表示步长stride。
初始的全卷积为32个卷积核,后面接了17个 residual bottleneck(文中提到共计采用19个bottleneck,但是这里只有17个)。bottleneck采用ReLU6作为激活函数。选择扩展因子(expansion factor)等于6,例如采用64的通道的输入张量产生128通道的输出,则中间的深度卷积的通道数为6×64=384。
此外,除了最后的avgpool,整个网络并没有采用pooling进行下采样,而是利用stride=2来下采样,这一点与Darknet53 一样的,至于原因?我猜是为了获取更多特征,pooling会有较大的信息损失。
特别的,对于stride=1 和stride=2,他们的bottleneck结构是不一样的,如下:
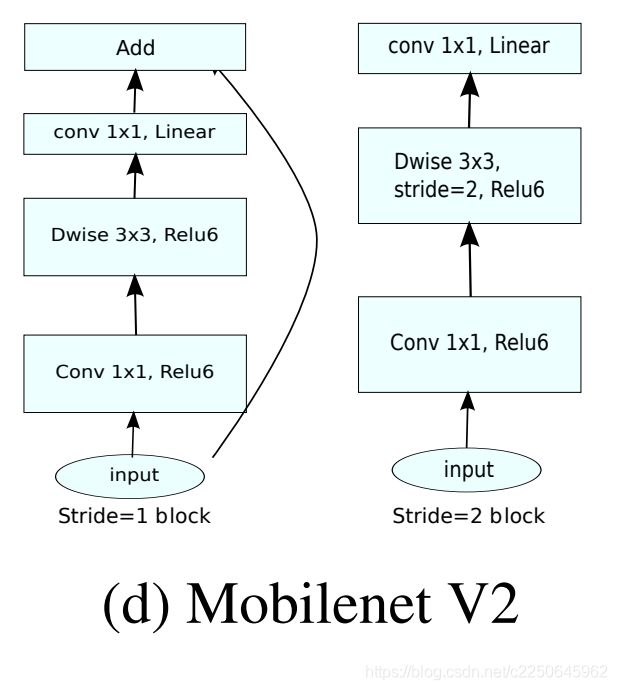
区别在于stride=2的时候没有shortcut连接,原因是stride=2的时候前后feature map尺寸不一样了,是为了维度匹配。
https://zhuanlan.zhihu.com/p/33075914
https://blog.csdn.net/u011995719/article/details/79135818
https://blog.csdn.net/u012505617/article/details/90511966
https://blog.csdn.net/u011974639/article/details/79199588