使用MindStudio进行MindInsight调优
相对应的视频教学可以在B站进行观看:
https://www.bilibili.com/video/BV1St4y1473r
一、MindSpore和MindInsight环境搭建和配置介绍
1 MindSpore简介
昇思MindSpore是一个全场景深度学习框架,旨在实现易开发、高效执行、全场景覆盖三大目标。
其中,易开发表现为API友好、调试难度低;高效执行包括计算效率、数据预处理效率和分布式训练效率;全场景则指框架同时支持云、边缘以及端侧场景。
昇思MindSpore总体架构如下图所示:
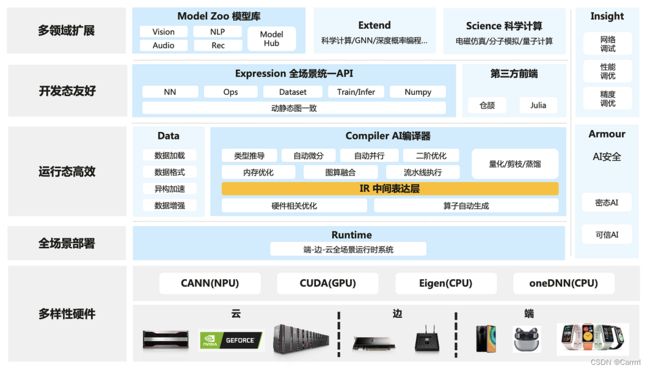
ModelZoo(模型库):ModelZoo提供可用的深度学习算法网络(ModelZoo地址)
Extend(扩展库):昇思MindSpore的领域扩展库,支持拓展新领域场景,如GNN/深度概率编程/强化学习等,期待更多开发者来一起贡献和构建。
Science(科学计算):MindScience是基于昇思MindSpore融合架构打造的科学计算行业套件,包含了业界领先的数据集、基础模型、预置高精度模型和前后处理工具,加速了科学行业应用开发(了解更多)。
Expression(全场景统一API):基于Python的前端表达与编程接口。同时未来计划陆续提供C/C++、华为自研编程语言前端-仓颉(目前还处于预研阶段)等第三方前端的对接工作,引入更多的第三方生态。
Data(数据处理层):提供高效的数据处理、常用数据集加载等功能和编程接口,支持用户灵活的定义处理注册和pipeline并行优化。
Compiler(AI编译器):图层的核心编译器,主要基于端云统一的MindIR实现三大功能,包括硬件无关的优化(类型推导、自动微分、表达式化简等)、硬件相关优化(自动并行、内存优化、图算融合、流水线执行等)、部署推理相关的优化(量化、剪枝等)。
Runtime(全场景运行时):昇思MindSpore的运行时系统,包含云侧主机侧运行时系统、端侧以及更小IoT的轻量化运行时系统。
Insight(可视化调试调优工具):昇思MindSpore的可视化调试调优工具,能够可视化地查看训练过程、优化模型性能、调试精度问题、解释推理结果(了解更多)。
Armour(安全增强库):面向企业级运用时,安全与隐私保护相关增强功能,如对抗鲁棒性、模型安全测试、差分隐私训练、隐私泄露风险评估、数据漂移检测等技术(了解更多)。
执行流程
有了对昇思MindSpore总体架构的了解后,我们可以看看各个模块之间的整体配合关系,具体如图所示:
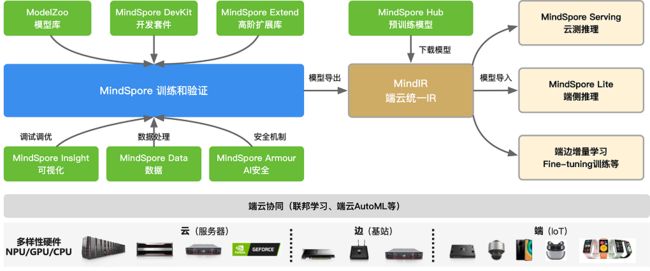
昇思MindSpore作为全场景AI框架,所支持的有端(手机与IOT设备)、边(基站与路由设备)、云(服务器)场景的不同系列硬件,包括昇腾系列产品,英伟达NVIDIA系列产品,Arm系列的高通骁龙、华为麒麟的芯片等系列产品。
左边蓝色方框的是MindSpore主体框架,主要提供神经网络在训练、验证相关的基础API功能,另外还会默认提供自动微分、自动并行等功能。
蓝色方框往下是MindSpore Data模块,可以利用该模块进行数据预处理,包括数据采样、数据迭代、数据格式转换等不同的数据操作。在训练的过程会遇到很多调试调优的问题,因此有MindSpore Insight模块对loss曲线、算子执行情况、权重参数变量等调试调优相关的数据进行可视化,方便用户在训练过程中进行调试调优。
设计理念
-
支持全场景协同
昇思MindSpore是源于全产业的最佳实践,向数据科学家和算法工程师提供了统一的模型训练、推理和导出等接口,支持端、边、云等不同场景下的灵活部署,推动深度学习和科学计算等领域繁荣发展。
-
提供Python编程范式,简化AI编程
昇思MindSpore提供了Python编程范式,用户使用Python原生控制逻辑即可构建复杂的神经网络模型,AI编程变得简单。
-
提供动态图和静态图统一的编码方式
目前主流的深度学习框架的执行模式有两种,分别为静态图模式和动态图模式。静态图模式拥有较高的训练性能,但难以调试。动态图模式相较于静态图模式虽然易于调试,但难以高效执行。 昇思MindSpore提供了动态图和静态图统一的编码方式,大大增加了静态图和动态图的可兼容性,用户无需开发多套代码,仅变更一行代码便可切换动态图/静态图模式,例如设置
context.set_context(mode=context.PYNATIVE_MODE)切换成动态图模式,设置context.set_context(mode=context.GRAPH_MODE)即可切换成静态图模式,用户可拥有更轻松的开发调试及性能体验。 -
采用函数式可微分编程架构,使用户聚焦于模型算法的数学原生表达
神经网络模型通常基于梯度下降算法进行训练,但手动求导过程复杂,结果容易出错。昇思MindSpore的基于源码转换(Source Code Transformation,SCT)的自动微分(Automatic Differentiation)机制采用函数式可微分编程架构,在接口层提供Python编程接口,包括控制流的表达。用户可聚焦于模型算法的数学原生表达,无需手动进行求导。
-
统一单机和分布式训练的编码方式
随着神经网络模型和数据集的规模不断增加,分布式并行训练成为了神经网络训练的常见做法,但分布式并行训练的策略选择和编写十分复杂,这严重制约着深度学习模型的训练效率,阻碍深度学习的发展。MindSpore统一了单机和分布式训练的编码方式,开发者无需编写复杂的分布式策略,在单机代码中添加少量代码即可实现分布式训练,例如设置
context.set_auto_parallel_context(parallel_mode=ParallelMode.AUTO_PARALLEL)便可自动建立代价模型,为用户选择一种较优的并行模式,提高神经网络训练效率,大大降低了AI开发门槛,使用户能够快速实现模型思路。
层次结构
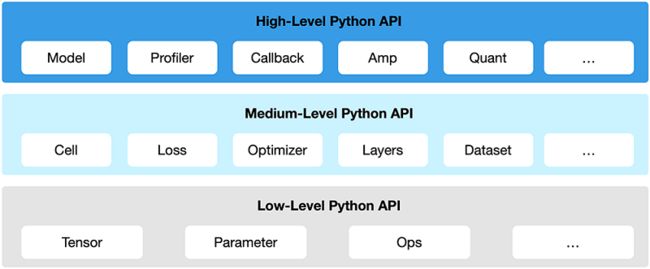
昇思MindSpore向用户提供了3个不同层次的API,支撑用户进行网络构建、整图执行、子图执行以及单算子执行,从低到高分别为Low-Level Python API、Medium-Level Python API以及High-Level Python API。
-
High-Level Python API
第一层为高阶API,其在中阶API的基础上又提供了训练推理的管理、混合精度训练、调试调优等高级接口,方便用户控制整网的执行流程和实现神经网络的训练推理及调优。例如用户使用Model接口,指定要训练的神经网络模型和相关的训练设置,对神经网络模型进行训练,通过Profiler接口调试神经网络性能。
-
Medium-Level Python API
第二层为中阶API,其封装了低阶API,提供网络层、优化器、损失函数等模块,用户可通过中阶API灵活构建神经网络和控制执行流程,快速实现模型算法逻辑。例如用户可调用Cell接口构建神经网络模型和计算逻辑,通过使用Loss模块和Optimizer接口为神经网络模型添加损失函数和优化方式,利用Dataset模块对数据进行处理以供模型的训练和推导使用。
-
Low-Level Python API
第三层为低阶API,主要包括张量定义、基础算子、自动微分等模块,用户可使用低阶API轻松实现张量定义和求导计算。例如用户可通过Tensor接口自定义张量,使用ops.composite模块下的GradOperation算子计算函数在指定处的导数。
2 MindInsight简介
MindInsight是昇思MindSpore的可视化调试调优工具。利用MindInsight,您可以可视化地查看训练过程、优化模型性能、调试精度问题、解释推理结果。您还可以通过MindInsight提供的命令行方便地搜索超参,迁移模型。在MindInsight的帮助下,您可以更轻松地获得满意的模型精度和性能。
MindInsight包括以下内容:
- 训练过程可视 (收集Summary数据、查看训练看板)
- 训练溯源及对比
- 性能调优
- 精度调试
- 超参调优
- 模型迁移
3 环境安装配置
3.1 MindSpore环境安装配置
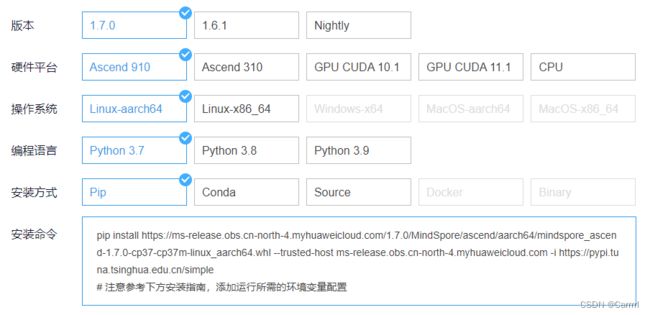
选择适合自己的环境条件后,获取命令并按照指南进行安装,或使用云平台创建和部署模型,安装细节参见链接:https://www.mindspore.cn/install
验证是否安装成功
方法一:
python -c "import mindspore;mindspore.run_check()"
如果输出:
MindSpore version: 版本号
The result of multiplication calculation is correct, MindSpore has been installed successfully!
说明MindSpore安装成功了。
方法二:
import numpy as np
from mindspore import Tensor
import mindspore.ops as ops
import mindspore.context as context
context.set_context(device_target="Ascend")
x = Tensor(np.ones([1,3,3,4]).astype(np.float32))
y = Tensor(np.ones([1,3,3,4]).astype(np.float32))
print(ops.add(x, y))
如果输出:
[[[[2. 2. 2. 2.]
[2. 2. 2. 2.]
[2. 2. 2. 2.]]
[[2. 2. 2. 2.]
[2. 2. 2. 2.]
[2. 2. 2. 2.]]
[[2. 2. 2. 2.]
[2. 2. 2. 2.]
[2. 2. 2. 2.]]]]
说明MindSpore安装成功了。
升级MindSpore版本
当需要升级MindSpore版本时,可执行如下命令:
pip install --upgrade mindspore-ascend=={version}
其中:
- 升级到rc版本时,需要手动指定
{version}为rc版本号,例如1.6.0rc1;如果升级到正式版本,=={version}字段可以缺省。
3.2 MindInsight环境安装配置
确认系统环境信息
- 硬件平台支持Ascend、GPU和CPU。
- 确认安装Python 3.7.5或3.9.0版本。如果未安装或者已安装其他版本的Python,可以选择下载并安装:
- Python 3.7.5版本 64位,下载地址:官网或华为云。
- Python 3.9.0版本 64位,下载地址:官网或华为云。
- MindInsight与MindSpore的版本需保持一致。
- 若采用源码编译安装,还需确认安装以下依赖。
- 确认安装node.js 10.19.0及以上版本。
- 确认安装wheel 0.32.0及以上版本。
- 其他依赖参见requirements.txt。
可以采用pip安装,源码编译安装和Docker安装三种方式。
pip安装
安装PyPI上的版本:
pip install mindinsight=={version}
安装自定义版本:
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/{version}/MindInsight/any/mindinsight-{version}-py3-none-any.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
其中:
- 当环境中的MindSpore不是最新版本时,需要手动指定
{version}为当前环境中MindSpore版本号。
注:非root用户需要在命令中加入“–user”参数。
源码编译安装
从代码仓下载源码
git clone https://gitee.com/mindspore/mindinsight.git -b r1.7
编译安装MindInsight
可选择以下任意一种安装方式:
1.在源码根目录下执行如下命令。
cd mindinsight
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
python setup.py install
2.构建whl包进行安装
进入源码的根目录,先执行build目录下的MindInsight编译脚本,再执行命令安装output目录下生成的whl包。
cd mindinsight
bash build/build.sh
pip install output/mindinsight-{version}-py3-none-any.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
Docker安装
MindSpore的镜像包含MindInsight功能,请参考官网安装指导。
验证是否成功安装
执行如下命令:
mindinsight start
如果出现下列提示,说明安装成功:
Web address: http://127.0.0.1:8080
service start state: success
二、MindStudio简介和安装
1 MindStudio简介
MindStudio提供在AI开发所需的一站式开发环境,支持模型开发、算子开发以及应用开发三个主流程中的开发任务。依靠模型可视化、算力测试、IDE本地仿真调试等功能,MindStudio能够帮助您在一个工具上就能高效便捷地完成AI应用开发。MindStudio采用了插件化扩展机制,开发者可以通过开发插件来扩展已有功能。
功能简介
- 针对安装与部署,MindStudio提供多种部署方式,支持多种主流操作系统,为开发者提供最大便利。
- 针对网络模型的开发,MindStudio支持TensorFlow、Pytorch、MindSpore框架的模型训练,支持多种主流框架的模型转换。集成了训练可视化、脚本转换、模型转换、精度比对等工具,提升了网络模型移植、分析和优化的效率。
- 针对算子开发,MindStudio提供包含UT测试、ST测试、TIK算子调试等的全套算子开发流程。支持TensorFlow、PyTorch、MindSpore等多种主流框架的TBE和AI CPU自定义算子开发。
- 针对应用开发,MindStudio集成了Profiling性能调优、编译器、MindX SDK的应用开发、可视化pipeline业务流编排等工具,为开发者提供了图形化的集成开发环境,通过MindStudio能够进行工程管理、编译、调试、性能分析等全流程开发,能够很大程度提高开发效率。
功能框架
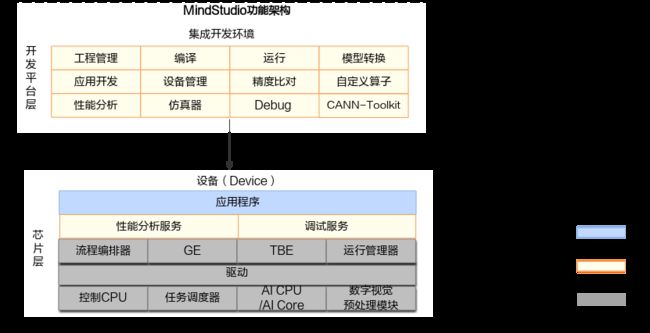
MindStudio功能框架如图所示,目前含有的工具链包括:模型转换工具、模型训练工具、自定义算子开发工具、应用开发工具、工程管理工具、编译工具、流程编排工具、精度比对工具、日志管理工具、性能分析工具、设备管理工具等多种工具。
工具功能
MindStudio工具中的主要几个功能特性如下:
- 工程管理:为开发人员提供创建工程、打开工程、关闭工程、删除工程、新增工程文件目录和属性设置等功能。
- SSH管理:为开发人员提供新增SSH连接、删除SSH连接、修改SSH连接、加密SSH密码和修改SSH密码保存方式等功能。
- 应用开发:针对业务流程开发人员,MindStudio工具提供基于AscendCL(Ascend Computing Language)和集成MindX SDK的应用开发编程方式,编程后的编译、运行、结果显示等一站式服务让流程开发更加智能化,可以让开发者快速上手。
- 自定义算子开发:提供了基于TBE和AI CPU的算子编程开发的集成开发环境,让不同平台下的算子移植更加便捷,适配昇腾AI处理器的速度更快。
- 离线模型转换:训练好的第三方网络模型可以直接通过离线模型工具导入并转换成离线模型,并可一键式自动生成模型接口,方便开发者基于模型接口进行编程,同时也提供了离线模型的可视化功能。
- 日志管理:MindStudio为昇腾AI处理器提供了覆盖全系统的日志收集与日志分析解决方案,提升运行时算法问题的定位效率。提供了统一形式的跨平台日志可视化分析能力及运行时诊断能力,提升日志分析系统的易用性。
- 性能分析:MindStudio以图形界面呈现方式,实现针对主机和设备上多节点、多模块异构体系的高效、易用、可灵活扩展的系统化性能分析,以及针对昇腾AI处理器的性能和功耗的同步分析,满足算法优化对系统性能分析的需求。
- 设备管理:MindStudio提供设备管理工具,实现对连接到主机上的设备的管理功能。
- 精度比对:可以用来比对自有模型算子的运算结果与Caffe、TensorFlow、ONNX标准算子的运算结果,以便用来确认神经网络运算误差发生的原因。
- 开发工具包的安装与管理:为开发者提供基于昇腾AI处理器的相关算法开发套件包Ascend-cann-toolkit,旨在帮助开发者进行快速、高效的人工智能算法开发。开发者可以将开发套件包安装到MindStudio上,使用MindStudio进行快速开发。Ascend-cann-toolkit包含了基于昇腾AI处理器开发依赖的头文件和库文件、编译工具链、调优工具等。
2 MindStudio安装
2.1 安装Python依赖
(1)官方网站下载安装安装Python3.7.5到Windows本地。
(2)设置环境变量。
(3)“Win + R”快捷键打开系统命令行,输入“Python -V”,显示Python版本号表示安装成功。
(4)安装Python3相关依赖。
pip install xlrd==1.2.0
pip install absl-py
pip install numpy
pip install requests
(5)如若返回如下信息,则表示安装成功。
Successfully installed xlrd-1.2.0
Successfully installed absl-py-0.12.0 six-1.15.0
Successfully installed numpy-1.20.1
Successfully installed requests-2.27.1
更多安装细节请参考:https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/instg/instg_000022.html
2.2 安装MinGW依赖
(1)根据电脑配置,下载适合的(下载参考地址),例如64位可以选择x86_64-posix-seh。
(2)解压MinGW安装包到自定义路径。
(3)在Windows 10操作系统的“控制面板 > 系统和安全 > 系统”中选择“高级系统设置”,如图所示。
(4)打开系统命令行,输入gcc -v命令。若显示版本号表示安装成功。
更多安装细节请参考:https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/instg/instg_000022.html
2.3 安装Java依赖
(1)要求Java版本为11,参考下载地址。
(2)下载后安装到本地,设置Java环境变量。
(3)打开系统命令,输入java --version,如显示Java版本信息,则表示安装成功。
2.4 安装Cmake
以msi格式软件包为例,安装步骤如下(下载参考地址),你也可以登录CMake官网下载合适的版本
(1)单击快捷键“win+R”,输入cmd,单击快捷键“Ctrl+Shift+Enter”,进入管理员权限命令提示符。若弹出“用户帐户控制”提示窗口,单击“是”。
(2)执行以下命令,安装软件包:
msiexec /package {path}\{name}.msi
例如:
msiexec /package D:\cmake-3.22.3-win64-x64.msi
(3)根据安装向导进行安装。
更多安装细节请参考:https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/instg/instg_000022.html
2.5 安装MindStudio
(1)MindStudio官网为我们提供两种安装方式。大家可以选择.zip文件,也可以选择.exe文件。此处我选择下载.zip文件。

(2)下载好后直接解压到任意目录。解压后目录结构如图所示。
(3)点击“bin”目录,然后双击目录下的“MindStudio64.exe”应用程序,运行MindStudio。
详细安装指导请参阅:https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/instg/instg_000021.html
三、使用MindStudio创建训练工程和运行脚本
1 导入模型代码创建训练工程
(1) 启动MindStudio
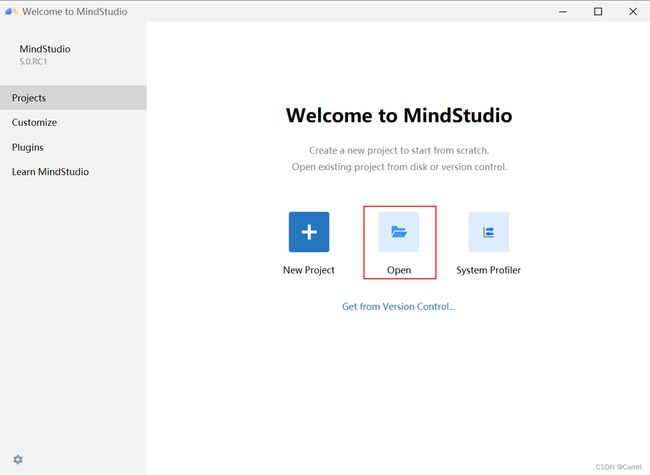
首次启动MindStudio会进入如下欢迎界面,大家按需选择新建项目或打开本地项目,在这里,我点击 Open 按钮打开本地现存项目(https://gitee.com/mindspore/models/tree/master/official/recommend/ncf)。
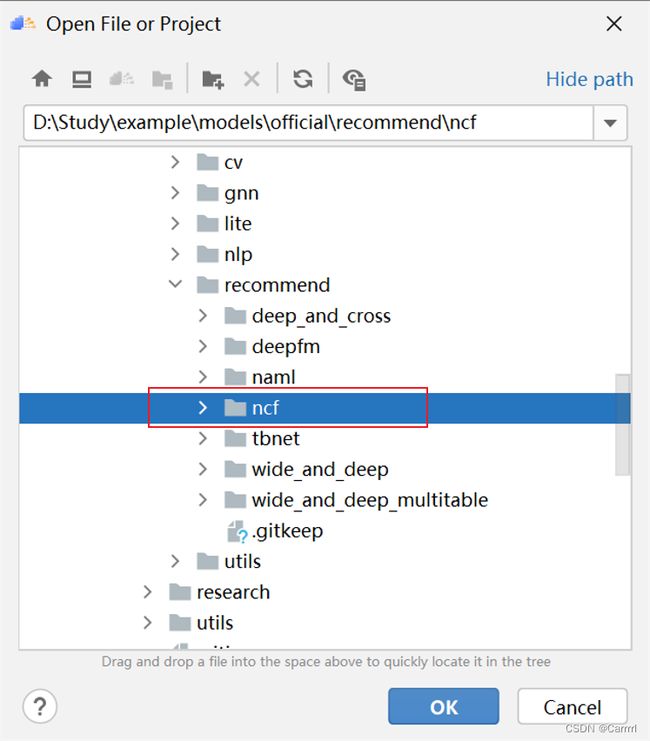
(2) 选择项目所在位置,添加 ncf 项目,点击 OK确定。
(3) 项目结构如图所示。
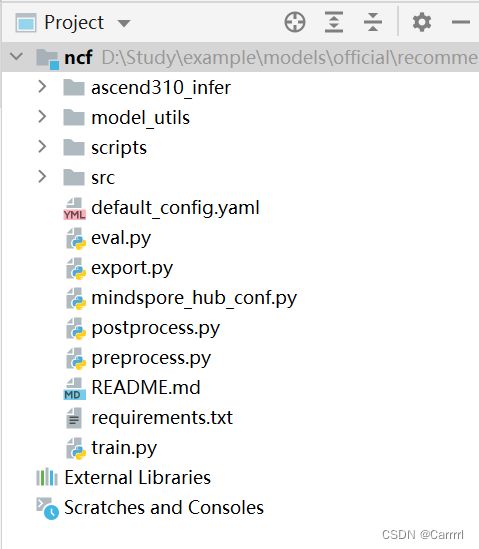
2 配置远程环境
2.1 连接远程服务器
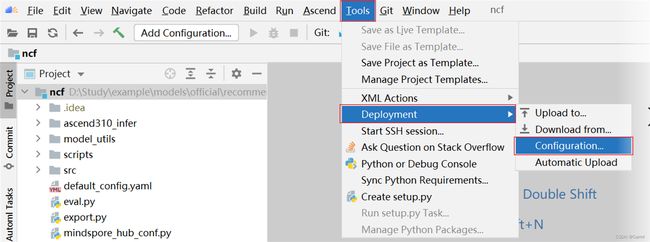
(1) 点击 Tools -> Deployment -> Configuration,配置远程连接服务器。
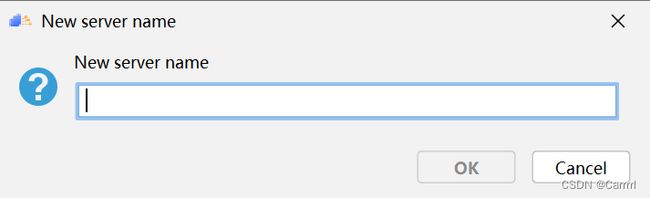
(2) 选中左侧 Deployment 选项卡,点击左上角加号,输入自定义远程连接名称。
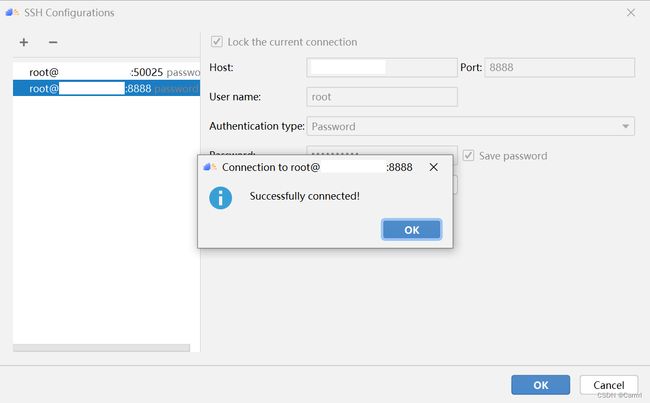
(3) 输入服务器 IP 地址、端口号、用户名及密码,建议勾选 Save password 保存密码,测试可以成功连接后,点击OK确定。
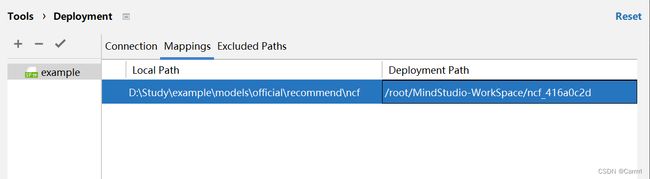
(4) 点击 Mappings 配置本地到服务器的文件路径映射。Local Path 填入本地项目路径,Deployment Path 选中远程服务器的项目路径,这两个文件夹名称不必完全相同。Excluded Paths(非必需)为配置忽略路径,表示忽略的项目文件不会上传到远程服务器。配置完成后,点击 OK 确定。
2.2 设置CANN
(1) 点击 File -> Settings,进入设置。
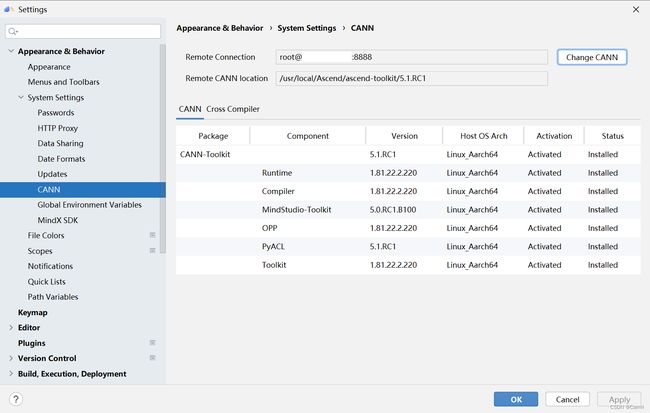
(2) 在左侧菜单依次选中 Appearance & Behavior -> System Settings -> CANN, 进入 CANN 配置选项卡中,设置远程服务器CANN路径。
2.3 配置远程SDK
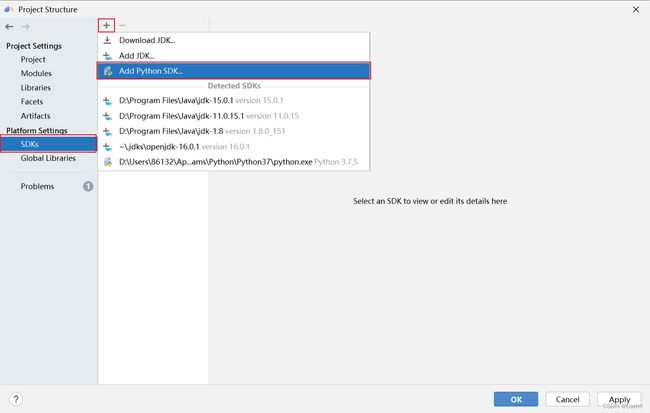
(1) 点击 File -> Projects Structure 进入项目设置。
(2) 在左侧菜单中选择 SDKs,点击左上角加号,选择 Add Python SDK… 进行SDK配置。
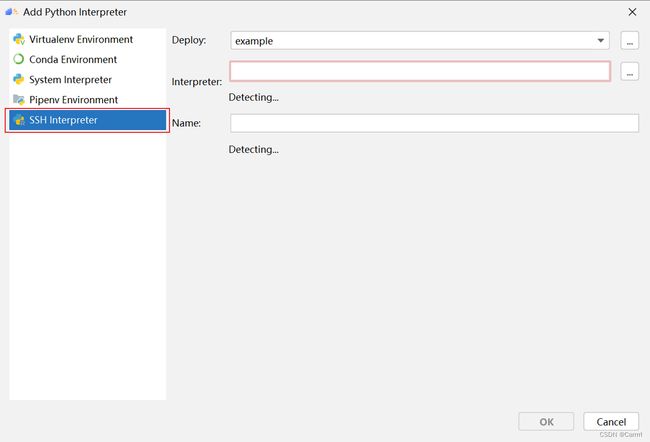
(3) 在弹出的选项卡中选择 SSH Interpreter,在Deploy中选择远程连接名称,等待 IDE 自动检测可用的Interpreter。
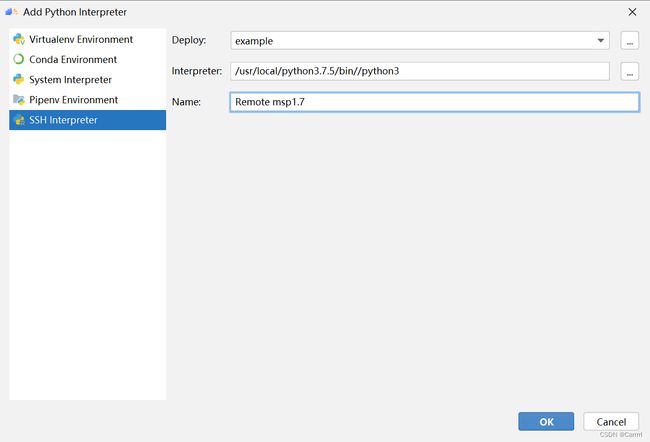
(4) 自动检测远程的SDK并显示如下,可以对其进行手动修改,我将 SDK 名称更改为 msp1.7 以便区分。
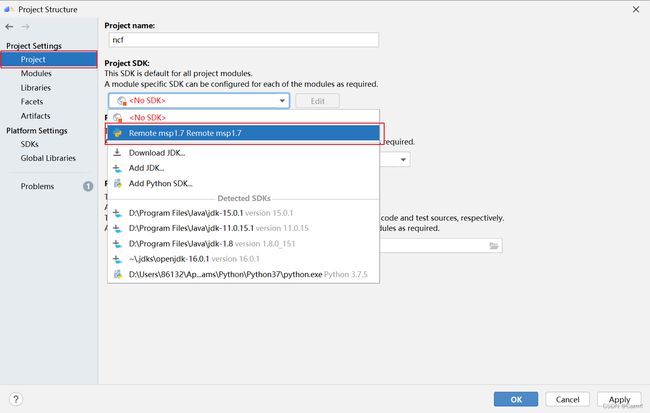
(5) 在 Project 中设置刚才配置的远程SDK msp1.7。
3 运行训练脚本
3.1 安装项目依赖
(1) 点击 Tools -> Start SSH session 打开远程服务器终端。
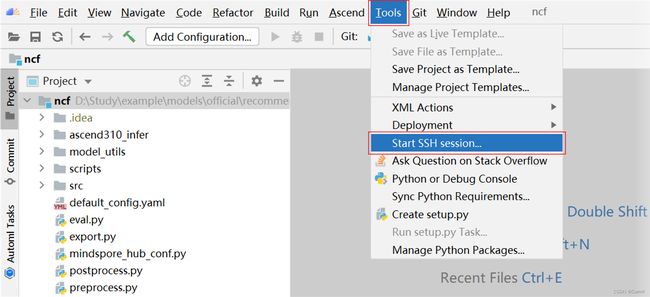
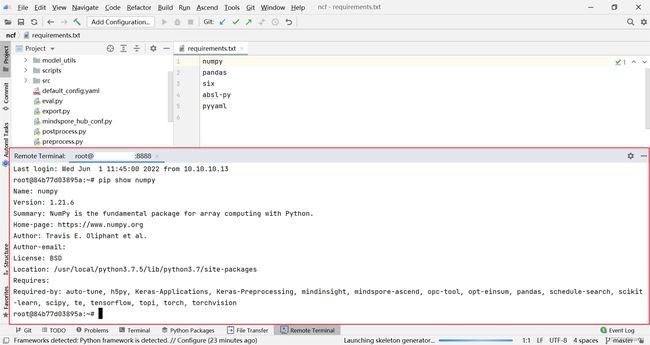
(2) 远程服务器终端显示在 IDE 下方控制台处,输入 pip list 检查所需依赖是否已安装。
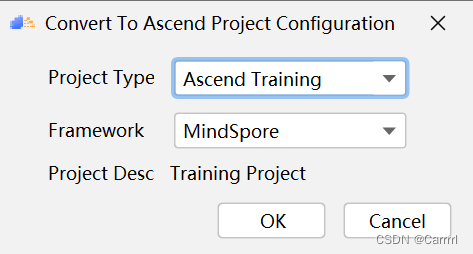
(3) 菜单栏中点击 Ascend -> Convert To Ascend Project,将当前项目转换为昇腾项目。

(4) 在弹出的对话框中选择转换的类型和框架,此处选择 Ascend Training 和 MindSpore 框架,点击 OK 确定。
3.2 数据集下载和处理
(1)NCF模型介绍
NCF 是用于协同过滤推荐的通用框架,其中神经网络架构用于对用户交互进行建模。与传统模型不同,NCF 不诉诸矩阵分解 (MF),其对用户和项目的潜在特征进行内积。它用可以从数据中学习任意函数的多层感知器代替积。
详见:https://gitee.com/mindspore/models/tree/master/official/recommend/ncf
(2)展开src目录,右击 movielens.py,配置运行参数。
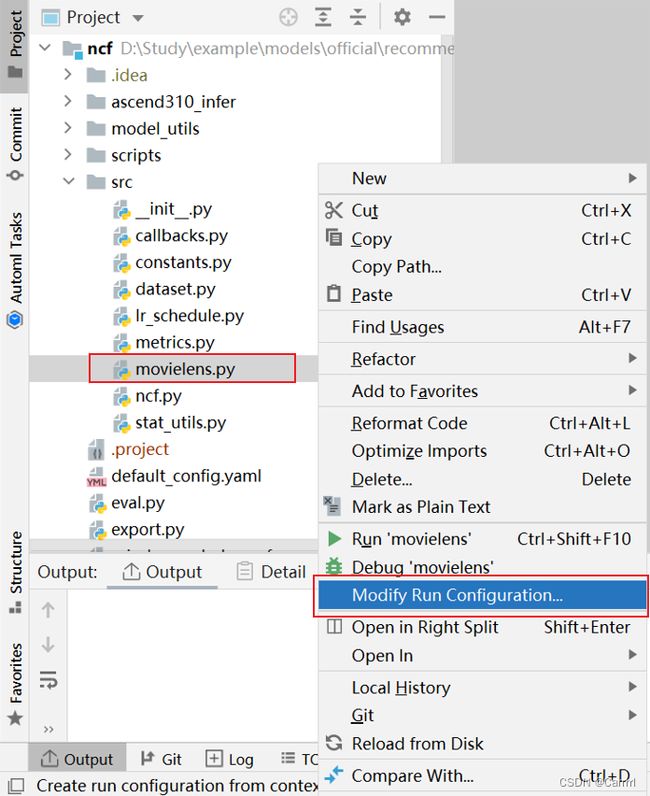
(3)配置运行参数,其中 Script path 设置为运行文件,Parameters 中设置参数,Python interpreter 选择前文配置的远程服务器中的 SDK,点击 OK 确定。
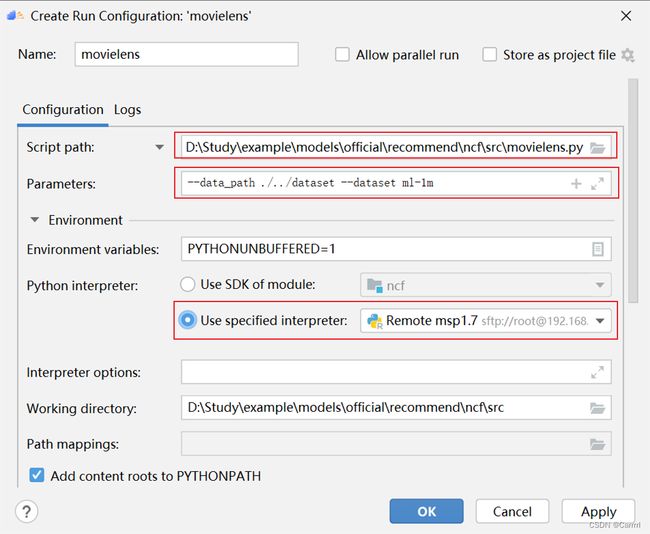
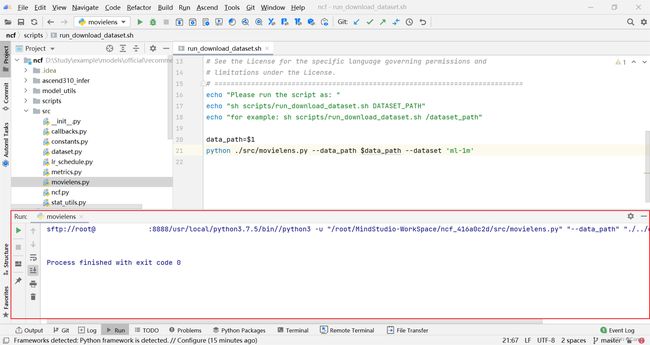
(4) 点击工具栏中的运行按钮,等待 ml-1m 数据集下载和预处理,大家可以在控制台输出查看当前程序运行的实时日志。

如果数据处理结束,会在控制台输出正常退出。
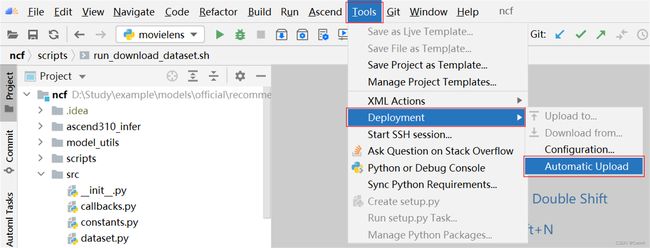
(5) 当运行程序后产生新的文件时,需要本地同步更新。建议大家点击Tools -> Deployment -> Automatic Upload 开启本地与服务器文件自动同步的功能。
(6)开启自动同步后,更新过程如图所示:
3.3 训练项目
(1)如图所示,点击Edit Configuration来编辑配置
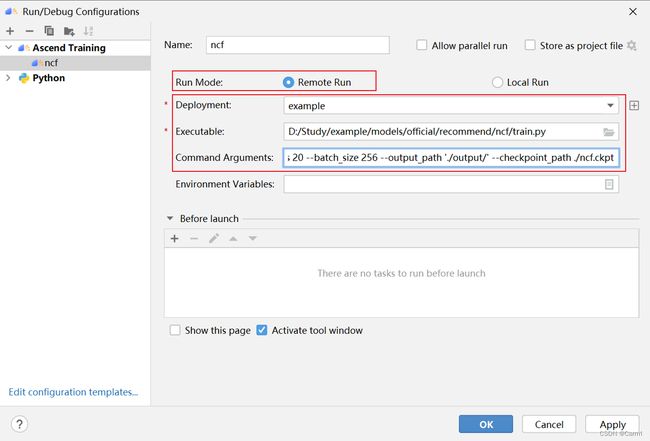
(2)设置训练参数,此处设置了训练20个epoch,batch_size为256,输出保存在 ./output文件夹中,checkpoint保存在 ./nfc.ckpt 文件夹中,点击 OK 确定。
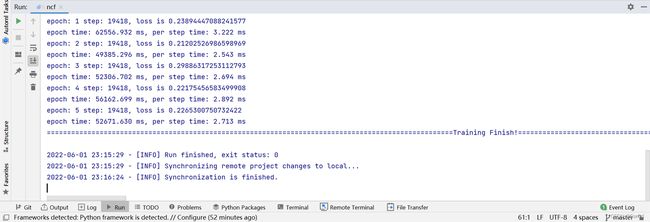
(3)点击运行,项目开始进行训练。

(4)在控制台中查看训练过程中实时打印的日志。
四、MindInsight训练可视化及精度调优指南
1 准备训练脚本
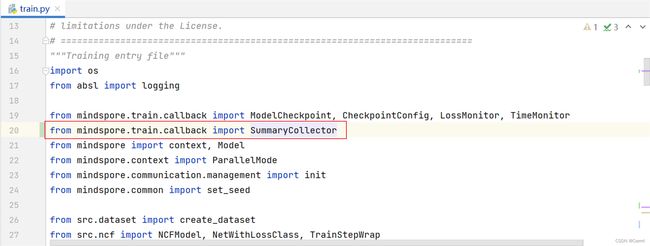
(1)在train.py中,导入SummaryCollector。
from mindspore.train.callback import SummaryCollector
(2)在train.py代码中,实例化 SummaryCollector,并添加到callbacks中。
# Init summary_collector
summary_collector = SummaryCollector(summary_dir="./summary_dir")
model.train(epochs,
ds_train,
callbacks=[TimeMonitor(ds_train.get_dataset_size()),
callback, ckpoint_cb, summary_collector],
dataset_sink_mode=False)
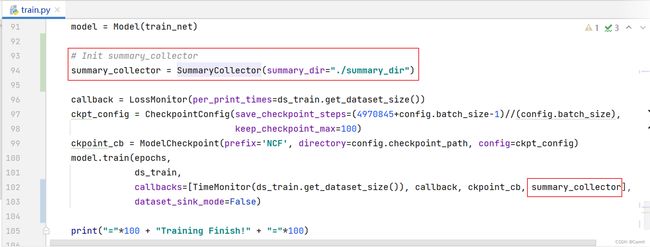
(3)增加如上代码后,须重新训练模型,收集的数据存放于 ./summary_dir 中。
2 MindInsight训练可视化配置
(1)在工具栏选择 Ascend -> MindInsight 打开 MindInsight 管理界面。
(2) MindInsight 管理界面可显示并管理多个 MindInsight训练可视化工程。MindInsight 管理界面相关属性说明如下图所示,点击Enable按钮,配置MindInsight组件相关参数。
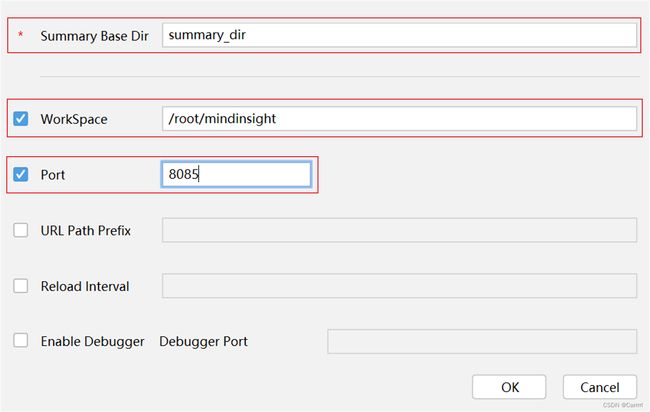
(3)在弹出的选项卡中,配置MindInsight组件相关参数,其中 Summary Base Dir 填入代码中设置的目录,WorkSpace 可以在 SSH 终端中输入 mindinsight start 查看,Port为端口号。
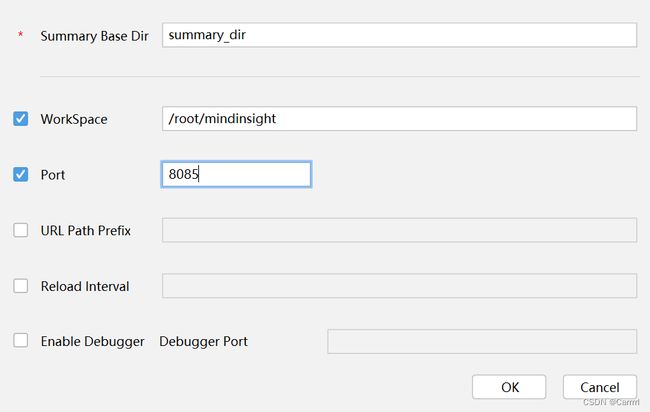
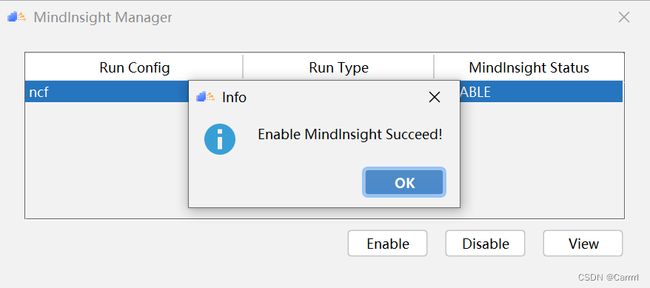
(4)单击 OK 完成 MindInsight 组件相关参数配置,出现如图所示界面,说明配置成功。
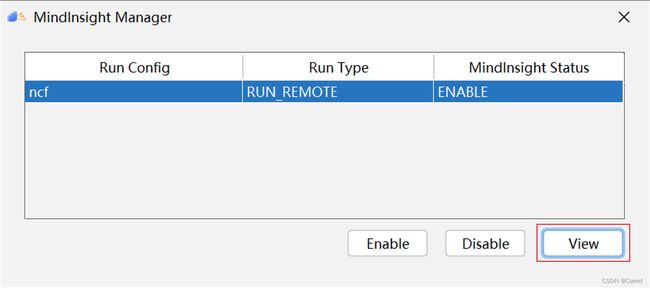
(5)点击 View 按钮即可跳转 MindInsight 界面。
3 查看MindInsight训练看板及精度调优指南
代码是精度问题的重要源头,超参问题、模型结构问题、数据问题、算法设计和实现问题会体现在脚本中,而我们使用的MindInsight生态工具可以将脚本中的各类问题以生动的可视化数据呈现给开发者,下面我们开始探究如何使用MindInsight进行精度调优。
(1)进入训练列表后,我们可以点击右上角的按钮选择开启/关闭自动刷新看板信息和设置刷新频率,以及切换语言和主题。
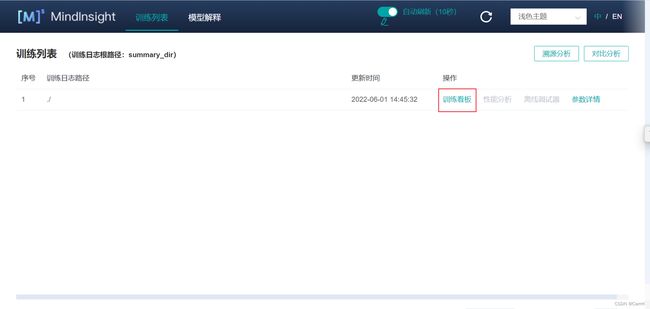
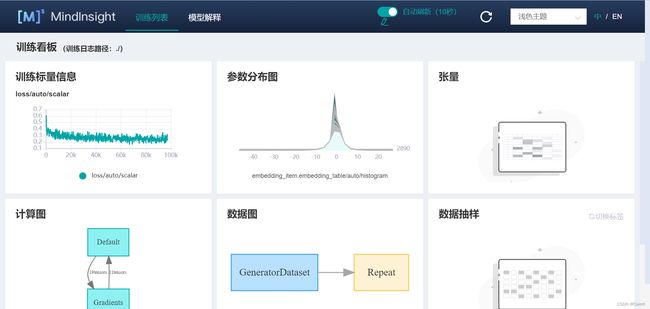
(2)点击“训练看板”后,可以看见训练时的各类可视化数据。主要包括损失函数、训练参数、训练数据以及网络计算图等。
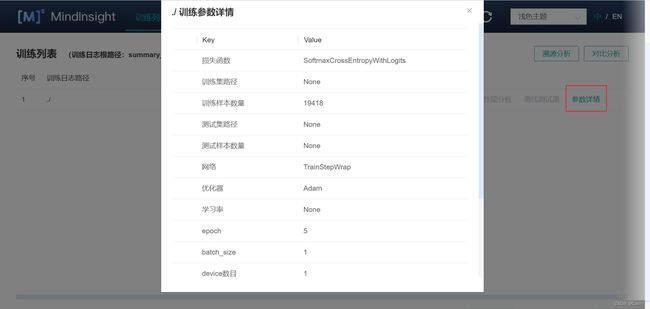
(3)点击 “参数详情” ,检查超参。
MindInsight可以辅助用户对超参做检查,大多数情况下,SummaryCollector会自动记录常见超参,大家可以通过MindInsight的训练参数详情功能和溯源分析功能查看超参。结合MindInsight模型溯源分析模块和脚本中的代码,可以确认超参的取值,识别明显不合理的超参。如果有标杆脚本,建议同标杆脚本一一比对超参取值,如果有默认参数值,则默认值也应一并比对,以避免不同框架的参数默认值不同导致精度下降或者训练错误。
根据我们的经验,超参问题主要体现为几个常见的超参取值不合理,例如:
①学习率过大导致loss震荡难收敛,学习率过小导致训练不充分,学习率带来的影响可以直观地从loss曲线观察到;
②loss_scale参数不合理,有可能导致loss为nan或loss迟迟不收敛;
③权重初始化参数不合理等。
参数详情可以显示常见的超参数。如下图所示:
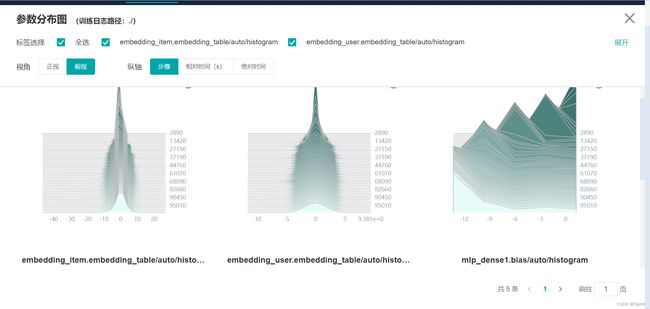
(4)点击 “参数分布图”,可以查看网络可训练参数随着迭代次数增加而产生的分布变化情况。大多数情况下,SummaryCollector会自动记录模型参数变化情况(默认记录5个参数),可以通过MindInsight的参数分布图模块查看。如果想要记录更多参数的参数分布图,请参考SummaryCollector的histogram_regular参数,或参考HistogramSummary算子。
(5)点击“计算图”,检查模型结构。
在模型结构方面,常见的问题有:
①算子使用错误(使用的算子不适用于目标场景,如应该使用浮点除,错误地使用了整数除)。
②权重共享错误(共享了不应共享的权重)。
③权重冻结错误(冻结了不应冻结的权重)。
④节点连接错误(应该连接到计算图中的block未连接)。
⑤loss函数错误。
⑥优化器算法错误(如果自行实现了优化器)等。
MindInsight可以辅助用户对模型结构进行检查。大多数情况下,SummaryCollector会自动记录计算图,点击 “计算图”,可以直观地看到各个网络节点的关系,如下图所示:
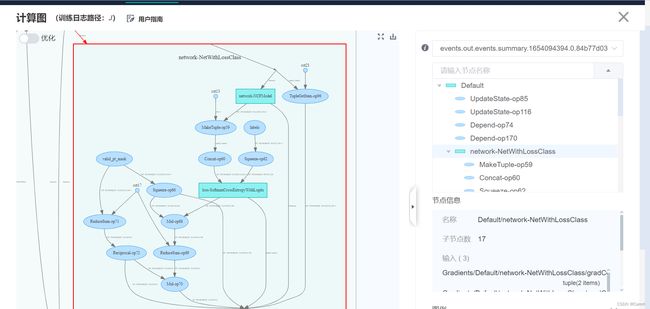
图中左侧为直观的计算图,右侧为各节点的树状结构图,点击相应的节点可以将其展开或折叠,方便用户查看。
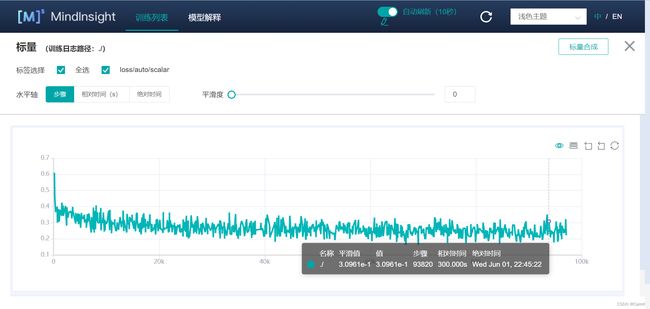
(6)点击“标量信息”,检查loss曲线。
大多数精度问题会在网络训练过程中发现,并且可以直观地体现在损失函数的图表中,我们总结了一些可以体现在损失函数异常的常见问题:
①权重问题(例如权重不更新、权重更新过大、权重值过大/过小、权重冻结不准确、权重共享设置有误);
②激活值问题(激活值饱和或过弱,例如Sigmoid的输出接近1,Relu的输出全为0);
③梯度问题(例如梯度消失、梯度爆炸);
④训练epoch不足(loss还有继续下降的趋势);
⑤算子计算结果存在NAN、INF等。
如下图,我们可以查看详细的损失函数信息,并且面板设置有开启/关闭Loss曲线全屏等功能,在这里可以直观地看到损失函数的收敛趋势以及波动幅度。
五、MindInsight训练耗时统计及性能调优指南
1 准备训练脚本
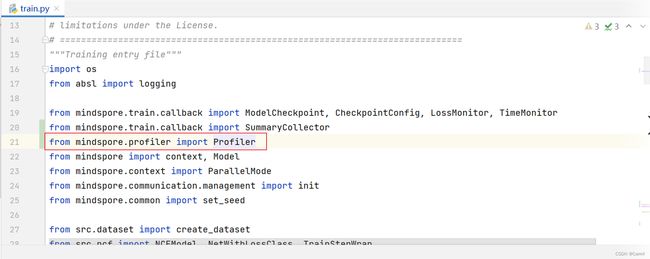
(1) 在train.py中导入Profiler。
from mindspore.profiler import Profiler
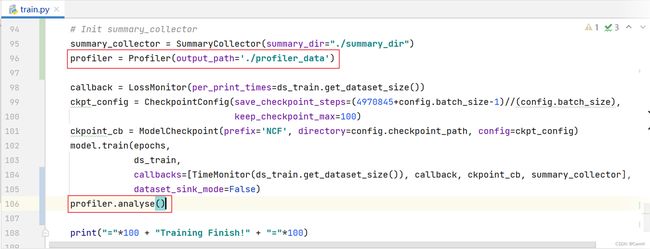
(2)收集profiler数据并分析。
profiler = Profiler(output_path='./profiler_data')
profiler.analyse()
(3)再次训练项目。此处仅仅作为模型性能调优,可以适当将训练总分步数调小(例如两个step,数据经过整个计算图即可得到算子耗时)。
2 MindInsight调优配置
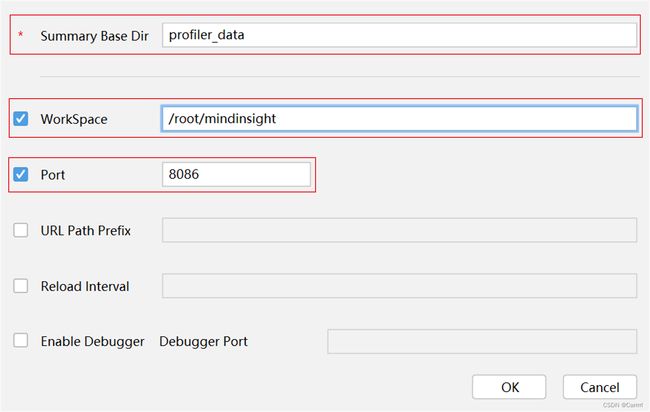
(1)更改MindInsight配置参数,与训练可视化的操作相似,这里的 Summary Base Dir 填入代码里设置的参数。
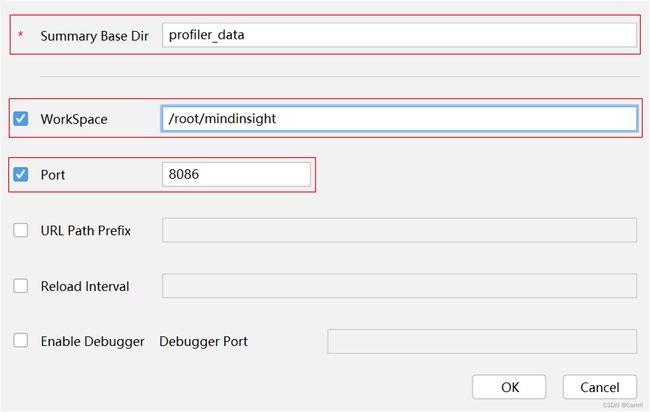
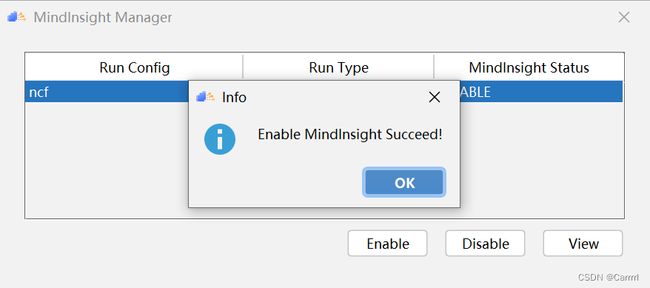
(2)单击 OK 完成 MindInsight 组件相关参数配置,出现如图所示界面,说明配置成功。
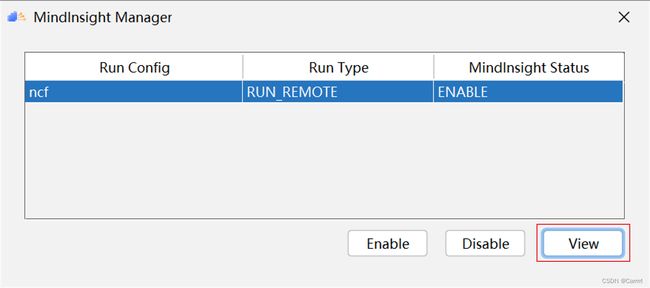
(3)点击 View 按钮即可跳转 MindInsight 界面。
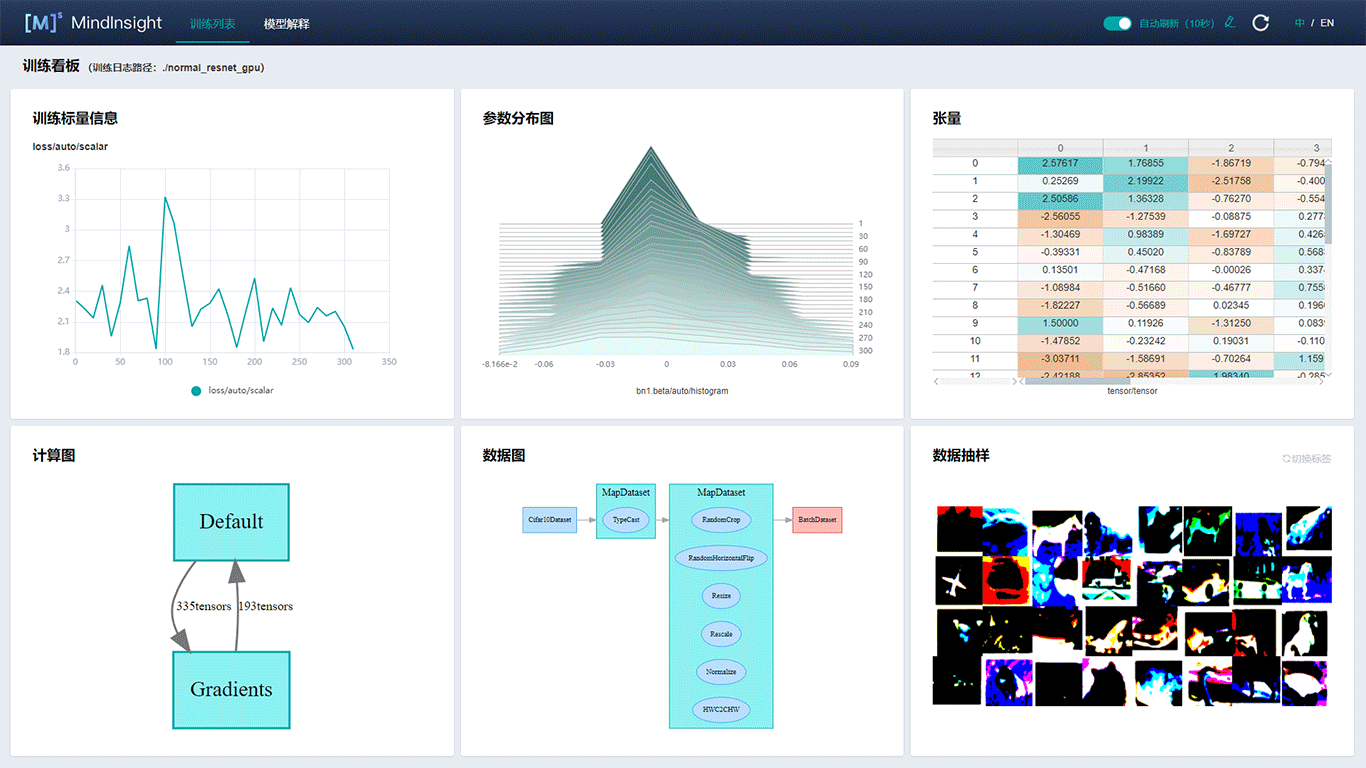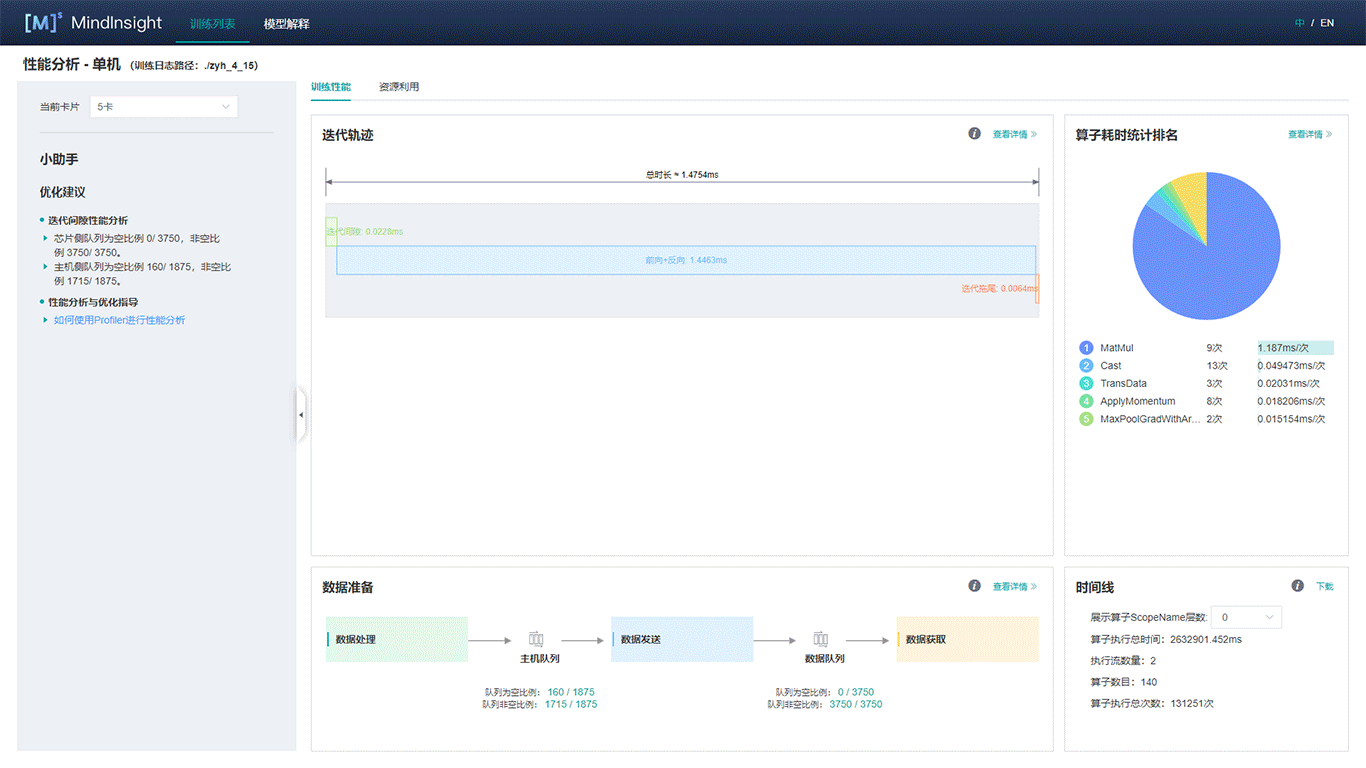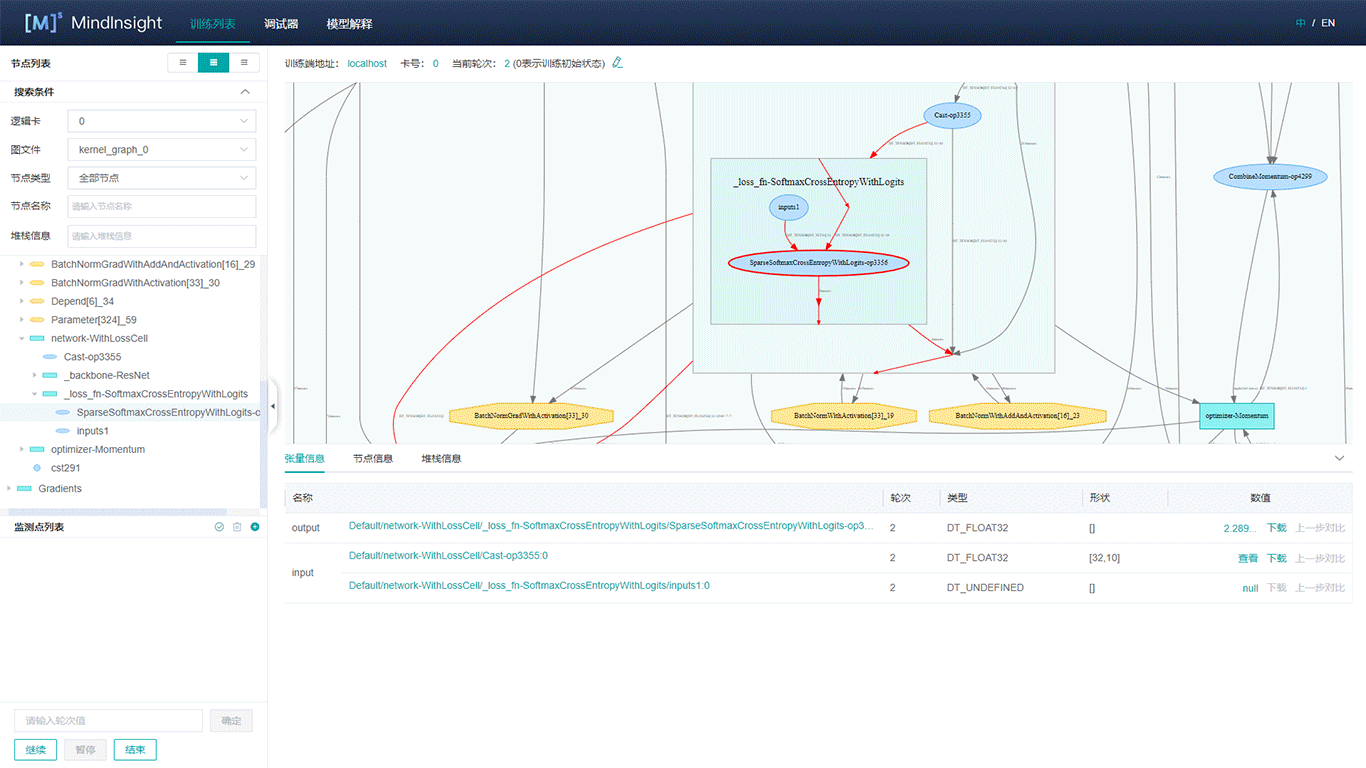
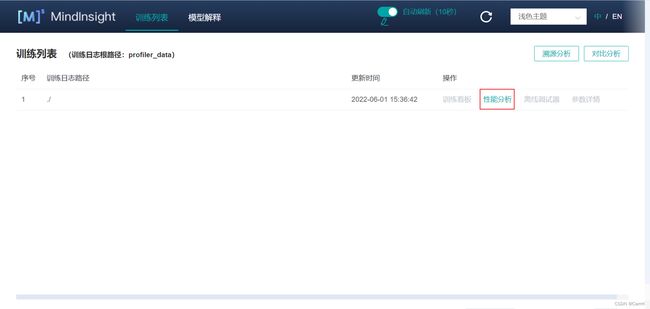
3 查看MindInsight性能看板及性能调优指南
(1)右上角可以选择开启/关闭自动刷新看板信息和刷新频率,以及切换语言和主题。点击 “性能分析”。
(2)进入性能分析看板后,可以看见有关训练耗时的各类数据图表。
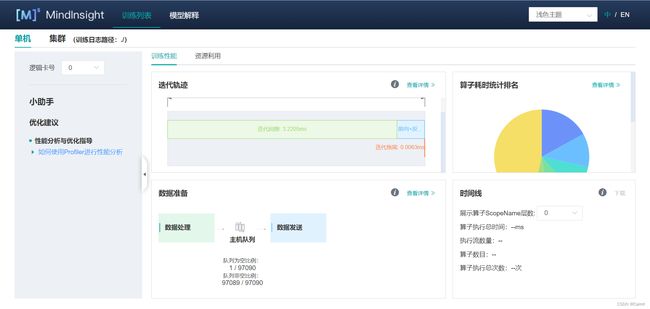
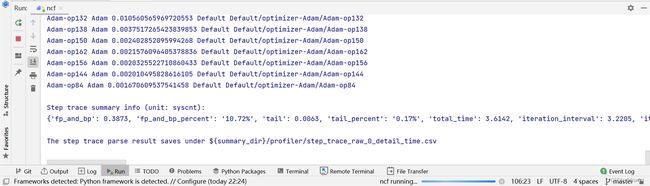
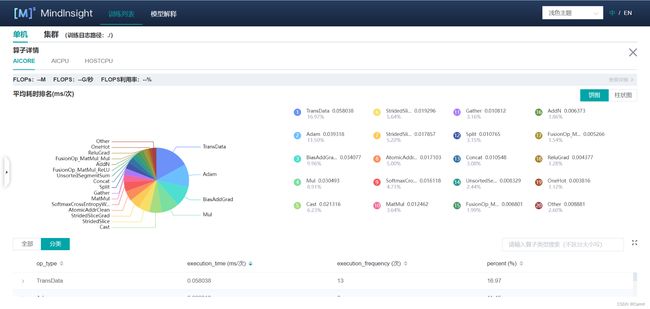
(3)点击“算子耗时统计排名”,可以查看各个算子的执行时间进行统计展示(包括AICORE、AICPU、HOSTCPU算子)。在右上角可以选择饼图/柱状图展示各算子类别的时间占比,每个算子类别的执行时间会统计属于该类别的算子执行时间总和。统计前20个占比时间最长的算子类别,展示其时间所占的百分比以及具体的执行时间(毫秒),我们可以选择算子耗时排名靠前的算子进行性能优化,这样有更大的优化空间。
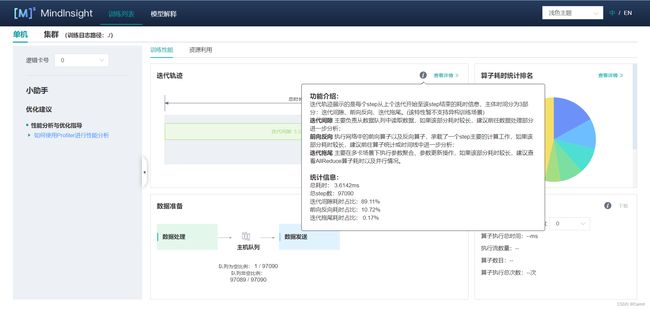
(4)点击“迭代轨迹”,查看每次迭代中各阶段的耗时,确定性能瓶颈点在哪个阶段,然后再针对该阶段进行详细分析。下面简单解释一下迭代轨迹中的三个阶段:
- 迭代间隙:该阶段反映的是每个迭代开始时等待训练数据的时间。如果该阶段耗占比较高,说明数据处理的速度跟不上训练的速度。
- 前反向计算:该阶段主要执行网络中的前向及反向算子,承载了一个迭代主要的计算工作。如果该阶段耗占比较高,较为合理。
- 迭代拖尾:该阶段主要包含参数更新等操作,在多卡场景下还包括集合通信等操作。如果该阶段耗占比较高,可能是集合通信耗时比较长。
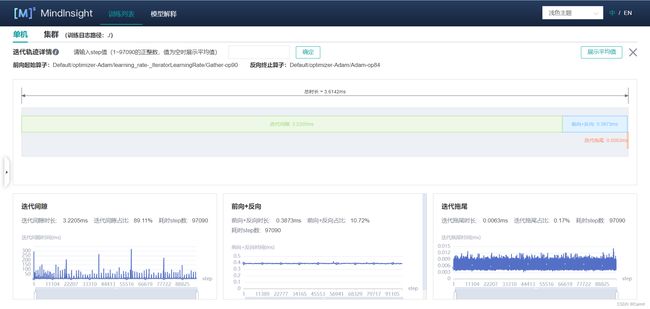
(5)进入“迭代轨迹”面板查看迭代轨迹详情。当我们确定性能瓶颈点在哪个阶段时,就可以更有针对性地进行性能优化。此处我们总结了三个阶段时间异常的原因分析及解决方案:
-
针对迭代间隙过长的问题:理想情况下,某个迭代开始前向训练时,其所需要的训练数据已经在Host侧完成了加载及增强并发送到了Device侧,反映到迭代间隙耗时通常在1毫秒内,否则就会由于等待训练数据而造成芯片算力的浪费。迭代间隙耗时长,说明该迭代开始前向计算时等待了较长的时间后训练数据才发送到了Device侧。用户需要到“数据准备”页面进一步确认是数据增强还是数据发送过程存在性能问题。
-
针对前反向耗时过长的问题:该阶段主要包含网络中前向及反向算子的执行时间。若该时间段耗时较长,建议按跳转到“算子耗时统计排名”标签页,查看训练过程中各算子的耗时情况,重点关注耗时排名靠前的部分算子。分享一些解决算子耗时长的小tips(欢迎补充~):
- 在不影响精度的前提下,将float32类型修改为float16类型;
- 存在转换算子过多(TransData、Cast类算子)且耗时明显时,如果是用户手动加入的算子,可分析其必要性,如果对精度没有影响,可去掉冗余的Cast、TransData算子;
-
针对迭代拖尾耗时过长的问题:该阶段在单卡场景主要包含参数更新等操作。从实际的调优经验来看,在单卡训练场景下该阶段耗时都很短,不会存在性能瓶颈。如果用户遇到单卡场景下该阶段耗时长,可以下载“时间线”,使用chrome://tracing工具观察参数更新相关的算子耗时是否有异常,并到MindSpore社区 反馈。
六、FAQ
1、使用远程conda环境无法识别conda环境里的包
原因:使用MindStudio进行远程连接服务器资源时,默认使用/usr/local/…下的本地环境。
解决方法:可以尝试指定运行文件为shell脚本,在shell脚本靠前位置指明source activate xxx-env来激活远程conda环境。
2、启动MindInsight训练看板卡顿,单击无响应。
解决方法:
(1)尝试disable后重新开启;
(2)尝试重新存储训练数据;
(3)SummaryCollector实例化的参数收集频率collect_freq设置的值过小,尝试调大一点。
3、点击View查看MindInsight训练面板,显示为空。
解决方法:Summary Base Dir 填入正确的目录,无需加前缀“./”。
4、MindInsight训练面板显示异常数据(数据不符合预期)。
原因:每个summary日志文件目录中,应该只放置一次训练的数据。一个summary日志目录中如果存放了多次训练的summary数据,MindInsight在可视化数据时会将这些训练的summary数据进行叠加展示,可能会与预期可视化效果不相符。
解决方法:将summary日志文件目录删除后,重新训练生成文件。
5、训练看板中Loss曲线过于平滑,难以分析Loss震荡幅度。
解决方法:将model.train方法的dataset_sink_mode参数设置为False,从而以step作为collect_freq参数的单位收集数据。当dataset_sink_mode为True时,将以epoch作为collect_freq的单位,此时建议手动设置collect_freq参数。collect_freq参数默认值为10。
七、从昇腾官方中体验更多内容
MindSpore模型开发教程与API可参考MindSpore官网:https://www.mindspore.cn/,
也可以在昇腾论坛进行讨论和交流:
https://bbs.huaweicloud.com/forum/forum-726-1.html
总结
本文主要介绍了如何使用MindStudio在MindSpore模型开发时使用MindInsight工具进行调优,详细介绍了其中的MindSpore环境搭建和配置介绍、MindStudio的安装与使用、训练工程的导入与配置、MindInsight训练可视化以及MindInsight性能调优等。
欢迎大家提出意见与反馈,谢谢!