CNN-PS: CNN-Based Photometric Stereo for General Non-convex Surfaces 2018ECCV
摘要
大多数传统的光度立体算法反过来解决了基于BRDF的图像形成模型。然而,由于在非凸表面上的全局光传播,实际的成像过程通常要复杂得多。本文提出了一种光度立体网络,该网络可以直接学习光度立体输入与场景表面法向之间的关系。为了处理无序输入,任意数量的输入图像问题,我们将所有输入数据合并到中间视图(称为观测图),该中间图具有固定的形状,可以馈入CNN。
为了改善训练和预测,我们考虑了从各向同性约束得出的观测图的伪旋转不变性。为了训练网络,我们创建了一个基于物理渲染器生成的合成光度立体数据集,因此考虑了全局光传播的效果。我们在合成和真实数据集上的实验结果表明,我们的方法优于传统的基于BRDF的光度立体算法,尤其是当场景高度非凸时。
非凸表面:
我理解的就是非凸集合的定义,把一个对象看做一个很多个点集的集合,如果任意两点的连线依然在这个集合之内,那就说明是凸集合,典型的圆,反之,就是非凸集合,对物体表面来说就是非凸表面了。
1.介绍
在3-D计算机视觉问题中,输入数据通常是非结构化的(即,输入图像的数量是变化的并且图像是无序的)。一个很好的例子是多视图立体问题,其中场景几何结构是从非结构化多视图图像中恢复的。除了一些结构化的问题(例如双目立体视觉[1]和两个视角的SfM [2],它们输入图像的数量始终固定)之外,由于这种非结构性,从多个图像进行的3-D重建较少依赖于基于监督学习的算法。但是,深度卷积神经网络(CNN)的最新进展促使研究人员使用深度神经网络解决非结构化3D计算机视觉问题。例如,Kar等人的最新著作文献[3]提出了一种用于多视点立体视觉的端到端学习系统。[4]提出了一种基于学习的表面反射率估计,该估计来自多个RGB-D图像。两项工作都聪明地将所有非结构化输入合并为结构化的中间表示形式(即3D特征网格[3]和2D半球形图像[4])。
光度立体是另一个3D计算机视觉问题,其输入是非结构化的,其中场景的表面法线从不同光照下的外观的变化中恢复。光度立体算法通常解决了基于双向反射分布函数(BRDF)的逐点图像形成模型的逆问题,就是从求I变成已知I反解N。虽然有效,但是基于BRDF的图像形成模型通常无法解决全局照明效果,例如阴影和相互反射,这对于恢复非凸表面通常是有问题的。一些算法尝试使用鲁棒的outliers抑制来抑制非朗伯效应[5-8],但是当非朗伯观测值占主导地位时,估计会失败。由于光和表面的多重相互作用很难以数学上可处理的形式进行建模,因此不可避免地会出现这种限制。
为解决此问题,本文提出了一种基于端到端CNN的光度立体算法,该算法无需物理的建模图像形成过程即可学习表面法线及其外观之间的关系。为了获得更好的可扩展性,我们的方法仍然是像素化的,而且没有继承传统的鲁棒方法[5-8],这意味着我们学习了自动“忽略”全局照明效果并从observation中的“inliers”估算表面法线的网络。也就是本文在学习过程中,会自动把非郎伯效应给视为离群值忽略掉。为了实现这一目标,我们将在尽可能多的输入合成样式下训练我们的网络,这些输入的样式会因全局效果而“损坏”。在不同的材质和光照条件下,使用不同的复杂对象渲染图像。
我们的挑战是将深度神经网络应用于输入是非结构化的光度立体问题。与最近的工作[3,4]类似,我们将所有的光度立体数据合并到一个称为“observation map”的中间表示形式,该图像具有固定的形状,因此自然地被馈送到标准的CNN。与许多光度学立体算法一样,我们的工作也主要涉及各向同性材料,这些材料的reflections在绕表面法线旋转时不变。我们将表明,可以通过观察图的伪旋转不变性的形式利用这种各向同性,既增加输入数据又减少预测误差。为了训练网络,我们利用基于物理学的Cycles渲染器[9]来模拟复杂的全局光传播,从而创建了合成的光度立体数据集(CyclesPS)。为了涵盖各种现实世界的材料,我们采用了迪士尼原则上的BSDF [10],该标准是为艺术家通过控制少量参数来渲染各种场景而提出的。
各向同性:指物体的物理、化学等方面的性质不会因方向的不同而有所变化的特性,即某一物体在不同的方向所测得的性能数值完全相同,亦称均质性。这里我理解的就是从不同方向观察一个物体,表面情况应该是一致的。
我们在DiLiGenT光度立体数据集[11]上评估我们的算法,该数据集是包含图像和已校准照明方向的真实基准数据集。我们将我们的方法与传统的光度学立体算法进行了比较[5–8,12–21],并表明我们基于端到端学习的算法最成功地恢复了所有相关算法中的非凸,非朗伯曲面。
总的贡献如下:
(1)首先,我们提出了一种已校准的基于CNN的监督光度立体算法,该算法将非结构化图像和照明信息作为输入。
(2)我们提出了一个合成的光度立体数据集(CyclesPS),并仔细注入了全局照明效果,例如cast shadow,相互反射。
(3)我们的广泛评估表明,在各种常规算法中,尤其是当表面高度非凸且非朗伯时,我们的方法在DiLiGenT基准数据集[11]上表现最佳。
此后,我们将基于对光度立体问题的经典假设(即固定位置,线性正交摄影机(小孔成像摄像机)和已知的定向照明)。
2.相关工作
讲什么是图像形成模型,ρ()就是BRDF函数,
现实世界对象的各种外观可以通过BRDFρ进行编码,BRDFρ将观察到的强度Ij与表面法线n∈R3,第j个入射照明方向lj∈R3,光照强度Lj∈R和出射方向v∈R3相关联,通过
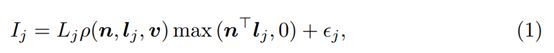
其中max(nT lj,0)解释了attached shadow,Ej是模型的附加误差。 等式(1)通常被称为图像形成模型。
大多数光度立体算法采用ρ的特定shape,并从来自m个不同光照条件下(j∈1,···,m)的观察值集合通过反求解方程(1)来恢复场景的表面法线。
通常,所有未用BRDF表示的效果(图像噪声,cast shadow,相互反射等)都放在Ej中。
注意,当BRDF为Lambertian且去除了附加误差时,它简化为传统的Lambertian图像形成模型[12]。
自Woodham首次引入Lambertian光度立体算法以来,将其工作扩展到非Lambertian场景一直是引起人们极大关注的问题。处理非朗伯效应的光度立体方法主要分为四类:(a)robust方法;(b)使用非朗伯BRDF进行反射建模;(c)基于示例的反射建模和(d)基于学习的方法。
许多光度立体算法通过简单的漫反射模型(例如Lambertian)恢复场景的表面法线,同时将其他效果视为outliers。例如,吴等[5]提出了一种基于秩最小化的方法,将图像分解为低秩的朗伯图像和非朗伯的稀疏崩坏效果。 Ikehata等通过限制3级朗伯结构[6](或一般的漫反射结构[7])扩展了他们的方法,以获得更好的计算稳定性。最近,Queau等[8]提出了一种鲁棒的变分方法,用于不准确的照明以及各种非朗伯式的corruption。虽然有效,但此方法的缺点是,如果不是针对密集的漫反射diffuse inliers,估计法向将失败。
尽管计算复杂,但是各种算法仍会使用非朗伯BRDF的参数或非参数模型。近年来,一直强调用少量参数的基础BRDF表示材料。高盛等[22]通过Ward模型[23]和Alldrin等人近似了每个基础BRDF。 [13]后来将其扩展为非参数表示。由于高维不适定问题可能会导致估算的不稳定性,Shi等人【18】提出了各向同性BRDF的紧凑的二次方程表示。另一方面,池田等人[17]引入了波瓣和各向同性反射模型[24]来说明各向同性观测中的所有频率。为了提高优化效率,Shen等人[25]提出了一种核回归方法,可以将其转化为特征分解问题。只要生成的图像形成模型正确且没有模型outliers,该方法就可以正常工作。
少量光度立体算法被分组到基于示例的方法中,该方法利用了在与目标场景相同的照明环境下捕获的已知形状的对象的表面反射率的优势。基于最早示例的方法[26]要求参考对象的材质与目标对象的材质完全相同。 Hertzmann等[27]通过假设材料可以表示为少量的基础材料,减轻了处理未校准场景和空间变化材料的限制。最近,Hui等[20]通过利用各种材料渲染的虚拟球体,提出了一个没有物理参考对象的基于实例的方法。尽管这种方法有效,但是也存在模型outliers的缺点,并且具有必须在目标场景处采用参考场景的照明配置的缺点。
机器学习技术已经在一些最近的光度学立体作品中得到应用[19,21]。 Santo等[19]提出了一种基于光度立体的使用神经网络的监督学习方法,该神经网络采用归一化向量作为输入,其中每个元素对应于在特定光照下的观察结果。通过将向量馈送到一个dropout层和相邻的六个dense层来预测表面法线。尽管有效,但该方法的局限性在于在训练和测试阶段之间的照明保持相同,从而使其不适用于非结构化输入。Taniai和Maehara的另一篇论文[21]提出了一种无监督的学习框架,其中,使用渲染方程将观测图像和合成图像之间的重建损失最小化,通过训练的网络预测了表面法线和BRDF。尽管它们的网络对于图像的数量和排列是不变的,但渲染方程式仍基于逐点BRDF,并且无法容忍模型outliers。此外,由于其自我监督方式,他们报告了运行时间较慢(即每个场景需要1小时进行1000次SGD迭代)。
总而言之,光度立体算法的设计在复杂性,效率,稳定性和鲁棒性方面仍存在不懈的努力。我们的目标是解决这个难题。我们基于端对端学习的算法建立在对合成数据集进行训练的深层CNN的基础上,放弃了复杂图像形成过程的建模。我们的网络接受非结构化的输入(即,我们的网络对于输入图像的数量和顺序均可变),并适用于各种非朗伯反射与全局照明效果混合在一起的现实世界场景。
3.提出的方法
我们的目标是恢复
(a)空间变化的各向同性材料并具有
(b)全局照明效果(例如阴影和互反射)
(c)场景被未知数量的光照明
的场景的表面法线。为了实现这一目标,我们提出了一种用于已经校准的光度立体问题的CNN架构,该架构对于输入图像的数量和顺序均不变。从使用基于物理的渲染器渲染的非凸场景的合成图像中可以了解对全局照明效果的容忍度。
3.1非结构化光度立体输入的二维观察图
我们首先介绍observation map,该observation map是根据已知的照明方向由观测值的像素级半球投影生成的。由于照明方向是跨单位半球的向量,因此通过将向量投影到lj [ljx ljy ljz]∈R3到[ljx ljy]∈R2(l2x + l2y + l2z = 1)有一个客观映射。垂直于观察方向(即v = [0 0 1])的xy坐标系。(我们初步尝试了在球坐标系(θ,φ)上的投影,但是性能不如在标准x-y坐标系上的投影)然后,将观察图O∈Rw×w定义为

其中“ int”是对浮点值进行取整的运算符取一个整数,α是一个比例因子以标准化数据(即,我们简单地使用α= max Lj / Ij)。一旦所有观测值和照明都存储在观测图中,我们就将其作为CNN的输入。尽管它很简单,但是它具有三个主要优点。
首先,其形状与输入图像的数量和大小无关。
其次,观测值的投影与顺序无关(即,交换第i和第j图像时,观测图不变)。
第三,没有必要将照明信息明确地馈送到网络中。
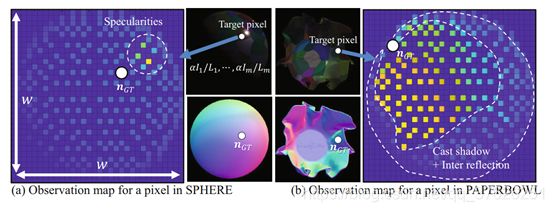
图1展示了两个对象(SPHERE和PAPERBOWL)的观测图示例,一个是纯凸的,另一个是高度非凸的。图1(a)指出目标点可能在凸面上,因为随着光方向偏离真实表面法线(nGT),观察图的值逐渐减小到零。高强度值的局部集中值也表明在光滑表面上存在窄镜面反射。另一方面,图1(b)中值的突然变化证明了在非凸表面上存在cast shadow或相互反射。由于没有局部集中的强度值,因此表面可能很粗糙。通过这种方式,观察图可以合理地编码表面点周围的光的几何形状,材质和行为。
图。1。
我们基于从半球到垂直于视轴的二维坐标系的光方向的客观映射,将图像和照明对投影到固定大小的observation map上。该图显示了(a)光滑凸面上的点和(b)粗糙非凸面上的点的观察图。我们还将该点的真实表面法线投影到观测图的相同坐标系上,以供参考。
3.2各向同性约束的旋转伪不变性
在一般的光度立体设置中(没有互相反射和阴影存在),观察图O稀疏(例如,假设w = 32,并且我们有100张图像作为输入,则O中非零项的比率约为10%,也就是一个光照对应一个观察图的值)。丢失的数据通常被认为是CNN输入的问题,并且经常被插值平滑处理[4]。但是,我们凭经验发现,平滑插入丢失的条目会降低性能,因为观察图通常不平滑,并且零值具有重要意义(即阴影)。因此,我们可以选择通过考虑材料的各向同性来提高性能。
当表面沿表面法向旋转时,许多现实世界的材料都具有相同的外观。这种行为的存在被称为各向同性[29,30]。各向同性BRDF是用三个值而不是四个[31]作为

参数化的,其中f是任意反射函数(请注意,各向同性BRDF还有其他参数设置[32]。)。 结合式(3)与式(1),得到以下图像形成模型。
![]()
注意,为简洁起见,省略了照明参数和模型误差。让我们考虑表面法线n和照明方向l绕z轴(即观察轴)的旋转,其中
![]()
是任意旋转矩阵。然后

把他们代入到等式(4)给出以下方程

因此,光照方向和表面法线绕z轴的旋转不会改变外观,如图2(a)所示。请注意,通过绕视轴旋转所有表面外观和环境照明,该定理甚至适用于非凸场景中的间接照明。这个结果对于我们基于CNN的算法很重要。我们假设神经网络是一个映射函数g:x→g(x)将x(即一组图像和光照)映射到g(x)(即一个表面法线),并且r是一个旋转运算符围绕z轴以相同角度旋转光线/法线的角度。从等式(8),我们得到r(g(x))= g(r(x))。我们称这种关系为旋转伪不变性(标准旋转不变性为g(x)= g(r(x)))。注意,由于围绕视轴的光照方向的旋转导致观察图也围绕z轴旋转,因此该旋转伪不变性也应用于观察图。(严格来说,我们旋转照明方向,而不是观察图本身。因此,我们不需要像标准旋转数据增强那样遭受边界问题的困扰。)
我们以实现旋转不变的类似方式,用旋转伪不变性约束网络。在CNN框架内,通常采用两种方法来编码旋转不变性。一种是将旋转应用于输入图像[33],另一种是将旋转应用于卷积核[34]。由于其简单性,我们采用第一种策略。具体来说,我们使用许多旋转版本的光照方向和曲面法线来增强训练集,这使网络不用人为强制即可学习旋转不变性。在我们的实现中,我们以10为标准间隔将向量从0旋转到360。

图2。(a)各向同性保证了v曲面的外观与l和n围绕视轴的旋转无关。 (b)我们的网络体系结构是DenseNet [28]的一种变体,它从32×32观察图输出标准化的表面法线。过滤器的编号显示在每层下方。
3.3架构细节
在本节中,我们描述了训练和预测的框架。给定图像和光照,我们根据等式2生成观察图。通过围绕视轴旋转光照方向和表面法线矢量,可以增强数据以实现旋转伪不变性。注意,彩色图像被转换为灰度图像。观察图的尺寸(w)应谨慎选择。随着w的增加,观测图变得稀疏。另一方面,较小的观察图具有较小的可表示性。考虑到这种折衷,我们凭经验发现w = 32是一个合理的选择(我们尝试w = 8、16、32、64,w = 32在图像数量少于一千时显示出最佳性能)。也就是说w是自己定的,这个方程的意思就是给每个像素的观察图里对应的像素找一个索引值吧

紧密连接的卷积神经网络(DenseNet [28])体系结构的一种变体用于从观察图估计表面法线。网络架构如图2(b)所示。该网络包括两个2层dense blocks,每个block由一个激活层(relu),一个卷积层(3×3)和一个dropout层(20%drop)组成,并与先前的层串联在一起。在两个dense blocks之间,有一个过渡层Transition,可通过卷积和池化来更改特征图的大小。(这里留个悬念1x1卷积和池化配合起来的作用)
我们没有插入在我们的实验中发现会降低性能的BN批处理归一化层。在dense blocks之后,网络具有两个dense层,然后是一个归一化层,该归一化层将特征转换为单位矢量(法向量的坐标)。使用预测的和GT表面法线之间的简单均方误差损失函数来训练网络。损失函数使用Adam求解器[35]最小化。

我们应该注意,由于我们的输入数据大小相对较小(即32×32×1),因此网络体系结构的选择并不是我们框架中的关键组件。(我们比较了AlexNet,VGG-NET和Densenet的体系结构,以及只有两个或三个卷积层和密集层的简单得多的体系结构。在我们测试过的架构中,当前架构略胜一筹。)
预测模块如图3所示。给定观测图,我们根据训练后的网络预测表面法线。 由于实际上不可能训练出理想的旋转伪不变网络,因此不同旋转程度的观测图的表面法线估计并不相同(通常每两个不同旋转之间的角度误差的差 小于其平均值的10%–20%) 。 为了进一步强调旋转伪不变性,我们再次通过以特定角度θ∈θ1,…·θK旋转照明向量来扩充输入数据,然后将输出合并为一个。 假设表面法线(nθ)是根据旋转Rθ的输入数据的预测,则我们只需对反解出来的表面法线进行平均,如下所示
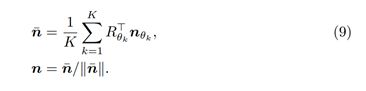

图3.预测模块的示意图。对于每个表面点,我们都会考虑旋转伪不变性生成K个观测图。每个观察图都被馈入网络,并对所有输出法线取平均值。
3.4训练数据集(CyclesPS数据集)
在本节中,我们介绍了CyclesPS训练数据集。 DiLiGenT [11],最大的实际光度立体数据集仅包含十个具有固定照明配置的场景。一些工作[17–19]尝试使用MERL BRDF数据库[29]来合成图像,但是只有一百个测量到的BRDF无法覆盖大量的现实世界材料。因此,我们决定创建自己的具有不同材质,几何形状和照明的训练数据集。
为了渲染场景,我们从互联网上收集了免版税许可下的高质量3-D模型。我们仔细选择了15种模型进行训练,并选择了3种模型进行测试,它们的表面几何形状足够复杂以涵盖各种表面法向分布。请注意,我们根据经验发现,在先前的工作[4]中使用的ShapeNet [36]中的3-D模型通常过于简单(例如,模型通常是低多边形的,大多是平面的),无法训练网络。
反射率的表示对于使网络对各种实际材料都具有鲁棒性也很重要。由于其可表示性,我们选择迪士尼原则的BSDF [10],它集成了五个不同的BRDF,这些BRDF由11个参数(baseColor,次表面,金属,镜面,镜面着色,粗糙度,各向异性,光泽,sheenTint,透明涂层,clearcoatGloss)
(baseColor, subsurface, metallic, specular, specularTint, roughness, anisotropic, sheen, sheenTint, clearcoat, clearcoatGloss)控制。由于我们的目标是没有subsurface的各向同性材料,因此我们忽略了诸如subsurface和anisotropic之类的参数。我们还忽略了specularTint,它在艺术上给镜面反射着色,还有clearcort和clearcoatGloss不会严重影响渲染结果。虽然principled的BSDF有效,但我们发现有一些不切实际的参数要跳过(例如,金属= 1,粗糙度= 0,或金属= 0.5)。为了避免这些不切实际的参数,我们将整个参数集分为三类:(a)漫反射,(b)镜面反射和(c)金属。我们分别生成三个数据集,并在训练网络时将它们均匀地合并。在每个参数的特定范围内随机选择每个参数的值(参见图4(a))。为了实现空间变化的材料,我们将渲染图像中的对象区域划分为P个超像素(即训练数据为5000个)超像素(超像素由一系列位置相邻且颜色、亮度、纹理等特征相似的像素点组成的小区域。),并在超像素内的像素中使用相同的参数集(见图4(b))。

图4.(a)principled BSDF [10]中每个参数的范围受三种不同的材料配置(漫反射,镜面反射,金属)限制。 (b)材质参数以2D纹理贴图的形式传递到渲染器。
为了模拟复杂的光传播过程,我们使用Blender [37]中捆绑的Cycles [9]渲染器。指定了正交摄影机和定向光。对于每个渲染,我们选择一组对象,BSDF参数maps(每个参数一个)和光照配置(即,一旦在半球上均匀分布约1300个光源,便会向每个光源添加少量随机噪声)。渲染图像后,我们通过逐像素生成观察图来创建CyclesPS数据集。为了使网络对任何数量的图像的测试数据都具有鲁棒性,可以逐像素从不同数量的图像中生成观察图。具体来说,在生成观察图时,我们选择图像的随机子集,其数量在50到1300之间,并且相应的光方向仰角大于20-90o度内的随机阈值。6(为了避免观察图太稀疏,最小图像数量为50,而我们只选择了仰角大于20°的灯,因为从侧面照亮场景的可能性很小。)
训练过程需要150个图像集的10个epochs(即15个object×10个rotations for 旋转伪不变性)。每个图像集包含大约50000个样本(即,object mask中的像素数)。
4实验结果
我们在合成和真实数据集上评估我们的方法。所有实验均在配备3×GeForce GTX 1080 Ti和64 GB RAM的计算机上进行。为了进行训练和预测,我们使用具有Tensorflow的Keras库[38],并使用默认的学习参数。培训过程耗时约3小时。
4.1数据集
我们在三个数据集上评估了我们的方法,两个是合成的,一个是真实的。
MERLSphere是一个合成数据集,其中使用MERL数据库[29]中的100个各向同性的BRDF从漫反射到金属渲染图像。我们生成了具有GT表面法线贴图和前景mask的球体(256×256)的32位HDR图像。没有投射阴影和相互反射。
CyclesPSTest是三个对象(SPHERE,TURTLE和PAPERBOWL)的合成数据集。 TURTLE和PAPERBOWL是非凸对象,在渲染的图像上会出现相互反射和投射阴影。除了参数图中的超像素数为100,材质条件为“镜面”或“金属”(请注意,CyclesPSTest中的对象和参数图不在CyclesPS中)之外,该数据集以与CyclesPS训练数据集相同的方式生成。每个数据包含16位整数图像,在17或305种已知的均匀照明下分辨率为512×512。
DiLiGenT [11]是包含10个具有一般反射率的真实对象的公共基准数据集。每个数据从96个不同的已知照明方向提供分辨率为612×512的16位整数图像。还提供了正交投影和单视图设置的GT表面法线。
4.2对MERLSphere数据集的评估
我们将我们的方法(在等式(9)中K = 10)与MERLSphere数据集上最新的各向同性光度学立体算法之一(IA14 [17] 我们使用作者[17]的实现(其中N1 = 2,N2 = 4)并打开retro-reflection处理。 通过简单的阈值去除Attached阴影。 注意,与[17]不同,我们的方法考虑了所有输入信息。)进行了比较。如果没有全局照明效果,与IA14中引入的总和BRDF [24]相比,我们只需评估网络表示各种材料的能力。结果如图5所示。我们观察到,对于大多数材料,基于CNN的算法性能相当好,尽管不比IA14好,这表明principled 迪士尼BSDF [10]涵盖了各种现实材料。我们应该注意到,正如[10]所述,一些非常光亮的材料,特别是金属(例如铬钢和碳化钨)表现出不对称的高光,表现出了镜头眩光或各向异性的表面划痕。由于我们的网络是在纯各向同性材料上进行训练的,因此它们不可避免地会降低性能。

图5.对MERLSphere数据集的评估。 在MERL BRDF数据库[29]中用100个测得的BRDF渲染一个球体。 基于预测的表面法线在角度上的平均角度误差,将基于CNN的方法与基于模型的算法(IA14 [7])进行了比较。 我们还展示了一些渲染图像和观察图的示例,以供进一步分析(请参见第4.2节)。
4.3对CyclesPSTest数据集的评估
为了评估我们的方法恢复非凸曲面的能力,我们在CyclesPSTest上测试了我们的方法。我们的方法与两个robust的算法IW12 [6]和IW14 [7] (We used authors’ implementation and set parameters of [6] as λ = 0, σ = 1.0−6 and parameters of [7] as λ = 0, p = 3, σa = 1.0.)进行了比较,还和两个基于模型的算法ST14 [18] (We used our implementation of [18] and set Tlow = 0.25.)和IA14 [17]和BASELINE [12]进行了比较。在运行除我们算法以外的算法时,我们会在16位整数图像中丢弃强度值小于655的样本以去除阴影。在该实验中,我们还研究了图像数量和把旋转后得到的法向的合并对预测的影响。(We still augument data by rotations in the training step)具体来说,我们在等式9中对K = 1和K = 10的17幅或305张图像进行了测试。我们在表1和图6中显示了结果。我们观察到所有算法在凸镜面SPHERE数据集上都能很好地工作。但是,当曲面不为凸面时,由于强烈的投射阴影和相互反射,所有算法(除了我们的算法)都无法通过估计。有趣的是,即使是robust的算法(IA12 [6]和IA14 [7])也无法将全局影响视为outliners。我们还观察到,基于旋转伪不变性的旋转平均确实提高了准确性,尽管不是很多。

表1.对CyclesPSTest数据集的评估。 这里m是每个数据集中输入图像的数量,{S,M}是材料的类型,即镜面(S)或金属(M)(有关详细信息,请参见图4)。 对于每个单元,我们以度为单位显示平均角度误差

图6.(a)高光材料的TURTLE和(b)PAPERBOWL的恢复的表面法线和误差图。 在统一的305灯光下渲染图像
4.4对DiLiGenT数据集的评估
最后,我们在DiLiGenT数据集[11]上进行了并排比较。我们收集了校准光度立体算法的现有基准测试结果[5–8,12–21]。请注意,我们比较了[11]中报告的[5,12–18],他们自己的工作[19–21]报告的平均角误差和使用作者实现的实验[6–8]的平均角误差。11结果如表2所示。由于篇幅所限,我们只显示了总体平均角度的前10个算法12和BASELINE [12]。我们观察到,我们的方法在10个对象上实现了最小的平均误差,在10个对象中有6个获得了最高分数。值得注意的是,其他排名靠前的算法[20,21]都很耗时,因为HS17 [20]要求针对每种不同的灯光配置进行字典学习,而TM18 [21]的每种估算都需要无监督训练,而我们的推理时间更少对于CPU上的每个数据集,时间间隔不超过5秒(当K = 1时)。

表2.对DiLiGenT数据集的评估。 我们显示了每个对象内以及所有对象上平均的角度误差。 (*)我们的方法丢弃了BEAR中的前20张图像,因为它们已损坏(我们在补充说明中对此问题进行了说明)
仔细观察每个对象,图7提供了一些重要的见解。在DiLiGenT和其他最新算法(TM18 [21],IW14 [7],ST14 [18])中,HARVEST是最不凸的场景,原因是阴影强烈,无法估计“袋”内的法线和相互反射。得益于基于精心创建的CyclesPS数据集进行训练的网络,我们基于CNN的方法在那里估计了更合理的表面法线。另一方面,对于另一个非凸场景的READING,我们的方法效果最好(尽管还不错)。我们的分析表明,这是由于在训练数据集中很少观察到的高强度窄镜面反射的相互反射(窄镜面反射仅在principled BSDF的粗糙度接近零时出现)。

5.结论
在本文中,我们提出了一种基于CNN的光度立体方法,该方法适用于具有全局照明效果的各种各向同性场景。通过将光度图像和照明信息投影到观察图上,自然可以将非结构化信息输入到CNN中。我们详尽的实验结果表明,对于合成数据和真实数据,我们的方法均具有最先进的性能,尤其是在表面非凸面的情况下。为处理狭窄的相互反射问题提供更好的训练是我们未来的方向。