Spark入门简介
大家好我是你们的好朋友,大数据老虾。相遇是缘,既然来了就拎着小板凳坐下来一起唠会儿,如果在文中有所收获,请别忘了一键三连,动动你发财的小手,你的鼓励,是我创作的动力!废话不多说,直接 开干吧!
PS:文末干货,记得拎着小板凳离开的时候也给它顺走
座右铭:“懒”对一个人的毁灭性有多大,早起的重要性就多大。
Spark入门概述
- Spark概述
-
- Apache Spark ™简介
- 主要特征
-
- 批处理/流式数据
- SQL 分析
- 大规模数据科学
- 机器学习
- Spark入门
-
- Python
- SQL
- Scala
- Spark SQL&DataFrame
-
- 融合的
- 统一数据访问
- 与Hive集成
- 标准连接
- 性能和可扩展性
- Spark Streaming
-
- 易使用
- 容错
- Spark集成
- 文末彩蛋
Spark概述
Apache Spark ™简介
Apache Spark ™是一种多语言引擎,用于在单节点机器或集群上执行数据工程、数据科学和机器学习。 用于大规模数据分析的统一引擎。 Apache Spark ™建立在用于大规模数据的高级分布式 SQL 引擎之上
主要特征
批处理/流式数据
使用语言:Python、SQL、Scala、Java 或 R,统一批量处理和实时流式处理您的数据。

SQL 分析
为仪表板和临时报告执行快速、分布式的 ANSI SQL 查询。比大多数数据仓库运行得更快。
大规模数据科学
对 PB 级数据执行探索性数据分析 (EDA),而无需进行下采样。

机器学习
在笔记本电脑上训练机器学习算法,并使用相同的代码扩展到包含数千台机器的容错集群。

Spark入门
Python
$ pip install pyspark
$ pyspark
QuickStart
df = spark.read.json("logs.json")
df.where("age > 21").select("name.first").show()
Machine Learning
# Every record contains a label and feature vector
df = spark.createDataFrame(data, ["label", "features"])
# Split the data into train/test datasets
train_df, test_df = df.randomSplit([.80, .20], seed=42)
# Set hyperparameters for the algorithm
rf = RandomForestRegressor(numTrees=100)
# Fit the model to the training data
model = rf.fit(train_df)
# Generate predictions on the test dataset.
model.transform(test_df).show()
Analy&Data Science
df = spark.read.csv("accounts.csv", header=True)
# Select subset of features and filter for balance > 0
filtered_df = df.select("AccountBalance", "CountOfDependents").filter("AccountBalance > 0")
# Generate summary statistics
filtered_df.summary().show()
SQL
$ SPARK-HOME/bin/spark-sql
spark-sql>
SELECT
name.first AS first_name,
name.last AS last_name,
age
FROM json.`logs.json`
WHERE age > 21;
Scala
$ SPARK-HOME/bin/spark-shell
scala>
val df = spark.read.json("logs.json")
df.where("age > 21")
.select("name.first").show()
Spark SQL&DataFrame
Spark SQL是 Apache Spark 用于处理结构化数据的模块。
融合的
将 SQL 查询与 Spark 程序无缝混合。Spark SQL 允许您使用 SQL 或熟悉的DataFrame API在 Spark 程序中查询结构化数据。可用于 Java、Scala、Python 和 R。
将函数应用于 SQL 查询的结果
results = spark.sql(
"SELECT * FROM people")
names = results.map(lambda p: p.name)
统一数据访问
以相同的方式连接到任何数据源。DataFrames 和 SQL 提供了一种访问各种数据源的通用方法,包括 Hive、Avro、Parquet、ORC、JSON 和 JDBC。您甚至可以跨这些来源连接数据。
查询和连接不同的数据源
spark.read.json("s3n://...")
.registerTempTable("json")
results = spark.sql(
"""SELECT *
FROM people
JOIN json ...""")
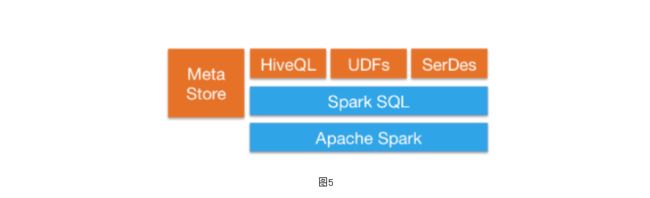
与Hive集成
在现有仓库上运行 SQL 或 HiveQL 查询。Spark SQL 支持 HiveQL 语法以及 Hive SerDes 和 UDF,允许您访问现有的 Hive 仓库。
Spark SQL 可以使用现有的 Hive 元存储、SerDes 和 UDF
标准连接
通过 JDBC 或 ODBC 连接。服务器模式为商业智能工具提供行业标准的 JDBC 和 ODBC 连接。
使用现有的 BI 工具查询大数据

性能和可扩展性
Spark SQL 包括一个基于成本的优化器、列式存储和代码生成,以加快查询速度。同时,它使用 Spark 引擎扩展到数千个节点和多小时查询,提供完整的中间查询容错。不要担心使用不同的引擎来处理历史数据。
Spark Streaming
Spark 流式处理使构建可扩展的容错流式处理应用程序变得容易。
易使用
通过高级操作员构建应用程序。Spark Streaming 将 Apache Spark 的 语言集成 API 引入了流处理,让您可以像编写批处理作业一样编写流作业。它支持 Java、Scala 和 Python。
在滑动窗口上计算推文
TwitterUtils.createStream(...)
.filter(_.getText.contains("Spark"))
.countByWindow(Seconds(5))
容错
开箱即用的有状态的一次性语义。Spark Streaming 开箱即用地恢复丢失的工作和操作员状态(例如滑动窗口),无需任何额外代码。

Spark集成
将流式传输与批处理和交互式查询相结合。通过在 Spark 上运行,Spark Streaming 允许您重用相同的代码进行批处理、根据历史数据连接流或对流状态运行临时查询。构建强大的交互式应用程序,而不仅仅是分析。
查找频率高于历史数据的单词
stream.join(historicCounts).filter {
case (word, (curCount, oldCount)) =>
curCount > oldCount
}
文末彩蛋
✨给各位朋友安利一下平时收集的各种学习资料!!!有需要的朋友点击一下⏩传送门,自行领取。程序员经典名言:“收藏了就等于学会啦”。 做人也要像蜡烛一样,在有限的一生中有一分热发一份光,给人以光明,给人以温暖!
图灵程序丛书300+
Linux实战100讲
Linux书籍
计算机基础硬核总结
计算机基础相关书籍
操作系统硬核总结
Java自学宝典
Java学习资料
Java硬核资料
Java面试必备
Java面试深度剖析
阿里巴巴Java开发手册
MySQL入门资料
MySQL进阶资料
深入浅出的SQL
Go语言书籍