Spark数据清洗案例
读完本篇你将收获
- 如何利用spark读取csv文件,并设置灵活的参数
- spark dataframe和rdd的转换
- spark 如何写到mysql内
- 熟悉java正则
- 熟悉日期类
- spark 常见算子
查看原数据格式(51job上的数据)
job_id,job_name,job_price,job_url,job_time,job_place,job_edu,job_exp,job_well,company_name,company_type,company_mag,company_genre
131132713,Java开发工程师,,https://jobs.51job.com/shenzhen-ftq/131132713.html?s=sou_sou_soulb&t=0,2021-04-19 13:31:43,深圳-福田区,大专,3-4年经验,五险一金 专业培训,上海任仕达人才服务有限公司,外资(欧美),150-500人,专业服务(咨询、人力资源、财会)
130900194,Java后台开发,1-1.5万/月,https://jobs.51job.com/wuhan-dxhq/130900194.html?s=sou_sou_soulb&t=0,2021-04-19 12:08:32,武汉-东西湖区,大专,3-4年经验,五险一金 绩效奖金 年终奖金 定期体检 带薪年假 节日福利 14薪,良品铺子股份有限公司,上市公司,10000人以上,快速消费品(食品、饮料、化妆品)
清洗要求
- job_exp :取最大数值,例如:5-7年经验 ->7,无需经验则为0,空值设为0
- job_price:取平均工资,1-1.5万/月 ->12500,空值设为0
- job_time:精确到日期,2021-04-19 13:31:43->2021-04-19,空值设为无发布时间
- company_type:去掉括号以及括号里的数据
- company_mag:取最大数,150-500人->500,空值设为0
- company_genre:去掉括号以及括号里的数据
- 去重
编写代码
- 创建maven项目贴入依赖(注意和自己的scala版本对应)
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.15</version>
</dependency>
- 编写主程序
case class Res(job_id:String,job_name:String,job_price:String,job_url:String,job_time:String,job_place:String,job_edu:String,job_exp:String,job_well:String,company_name:String,company_type:String,company_mag:String,company_genre:String)
object homework1 {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local").appName("te").getOrCreate()
val rdd: RDD[Row] = session.read.option("delimiter",",").option("header","true").csv("C:\\Users\\fanhuazeng\\Desktop\\data2.csv").distinct().rdd
val properties: Properties = new Properties()
properties.put("user","root")
properties.put("password","123456")
val pattern = Pattern.compile("\\d+")
val format: SimpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val toformat: SimpleDateFormat = new SimpleDateFormat("yyyy-MM-dd")
val pattern1 = Pattern.compile("^(\\d+?\\.?\\d*?)\\-(\\d+?\\.?\\d*?)万/月$")
val pattern2 = Pattern.compile("^(\\d+?\\.?\\d*?)\\-(\\d+?\\.?\\d*?)千/月$")
val pattern3 = Pattern.compile("^(\\d+?)元/小时$")
val pattern4 = Pattern.compile("^(\\d+?)元/天$")
val pattern5 = Pattern.compile("^(\\d+?\\.?\\d*?)千(以下|以上)?/月$")
val pattern6 = Pattern.compile("^(\\d+?\\.?\\d*?)\\-(\\d+?\\.?\\d*?)万/月$")
val pattern7 = Pattern.compile("^(\\d+?\\.?\\d*?)万(以下|以上)/月$")
val pattern8 = Pattern.compile("^(\\d+?\\.?\\d*?)万(以下|以上)/年$")
val pattern9 = Pattern.compile("^(\\d+?\\.?\\d*?)\\-(\\d+?\\.?\\d*?)万/年$")
import session.implicits._
rdd.map((item)=>{
//1.jobexp
var item6="0"
if(item.isNullAt(7)||item.equals("")||((!item.isNullAt(7))&item.getAs[String](7).equals("无需经验"))){
item6="0"
}else{
val matcher: Matcher = pattern.matcher(item.getAs[String](7))
while (matcher.find()){
if(matcher.group().toInt>item6.toInt){
item6=matcher.group()
}
}
}
//3.jobtime
var jobtime="无发布时间"
if(!item.isNullAt(4)){
jobtime = toformat.format(format.parse(item.getAs(4)))
}
//4.company_type 去掉括号数据
var company_type=""
if(!item.isNullAt(10)){
val strings: Array[String] = item.getAs(10).toString.split("\\(.*?\\)")
for (i <- strings){
company_type+=i
}
}
//6.company_genre:去掉括号数据
var company_genre=""
if(!item.isNullAt(12)) {
val strings2: Array[String] = item.getAs(12).toString.split("\\(.*?\\)")
for (i <- strings2) {
company_genre += i
}
}
//5.company_mag
var company_mag="0"
if(!item.isNullAt(11)){
val matcher2: Matcher = pattern.matcher(item.getAs(11).toString)
while (matcher2.find()){
if(matcher2.group().toInt>company_mag.toInt){
company_mag=matcher2.group()
}
}
}
//2.job_price:取平均工资
var job_price=0
if(item.isNullAt(2)){
job_price=0
}else{
val matcher1 = pattern1.matcher(item.getAs(2))
val matcher2 = pattern2.matcher(item.getAs(2))
val matcher4 = pattern4.matcher(item.getAs(2))
val matcher3 = pattern3.matcher(item.getAs(2))
val matcher5 = pattern5.matcher(item.getAs(2))
val matcher6 = pattern6.matcher(item.getAs(2))
val matcher7 = pattern7.matcher(item.getAs(2))
val matcher8 = pattern8.matcher(item.getAs(2))
val matcher9 = pattern9.matcher(item.getAs(2))
if(matcher1.find()){
job_price=(matcher1.group(1).toDouble*10000+matcher1.group(2).toDouble*10000).toInt/2
}else if(matcher2.find()){
job_price= (matcher2.group(1).toDouble*10000+matcher2.group(2).toDouble*10000).toInt/2
}else if(matcher3.find()){
job_price= matcher3.group(1).toInt*24*30
}else if(matcher4.find()){
job_price=matcher4.group(1).toInt*30
}else if(matcher5.find()){
job_price=(matcher5.group(1).toDouble*1000).toInt
} else if(matcher6.find()) {
job_price=(matcher6.group(1).toDouble*10000+matcher6.group(2).toDouble*10000).toInt
} else if(matcher7.find()) {
job_price = (matcher7.group(1).toDouble*10000).toInt
} else if(matcher8.find()){
job_price = (matcher8.group(1).toDouble*10000/12).toInt
} else if(matcher9.find()){
job_price=((matcher9.group(1).toDouble*10000+matcher9.group(2).toDouble*10000)/12 ).toInt
}
}
Res(item.getAs[String](0),item.getAs[String](1),job_price.toString,item.getAs[String](3),jobtime,item.getAs[String](5),item.getAs[String](6),item6,item.getAs[String](8),item.getAs[String](9),item.getAs[String](10),company_mag,company_genre)
}).toDF().write.mode(SaveMode.Overwrite).jdbc("jdbc:mysql://127.0.0.1:3306/test?useSSL=false&serverTimezone=GMT%2B8&useUnicode=true&characterEncoding=UTF-8","test",properties)
}
}
我的收获
在利用spark做清洗的时候,需要十分严谨,如果你无法保证每个字段都不为空的清况,十分有必要判空,否则爆空指针异常就会终止程序的运行
文末
我通过sql发现一个1500-3000万/月的岗位,哈哈哈哈哈哈哈哈哈哈哈哈!
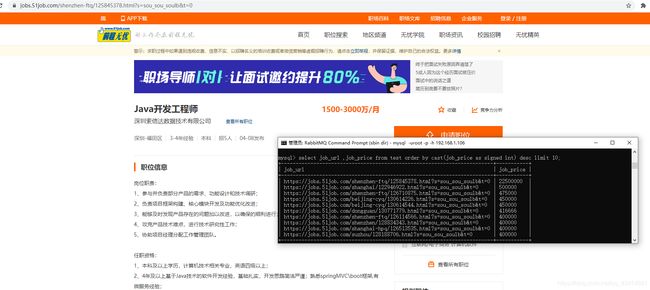
如果需要本程序数据的可以私信我哦!共同学习!