RDD编程初级实践
1.需求描述
本次实验需要基于Linux操作系统,熟悉Spark的RDD基本操作及键值对操作;熟悉使用RDD编程解决实际具体问题的方法。
RDD 是 Spark 提供的最重要的抽象概念,它是一种有容错机制的特殊数据集合,可以分布在集群的结点上,以函数式操作集合的方式进行各种并行操作。 RDD典型的执行过程如下:RDD读入外部数据源(或者内存中的集合)进行创建;RDD经过一系列的“转换”操作,基于现有的数据集创建一个新的数据集;最后一个RDD经“行动”操作进行处理,在数据集上进行运算,返回计算值。
RDD采用了惰性调用,即在RDD的执行过程中,真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。
2.环境介绍
实验环境基于:
虚拟机:Oracle VM VirtualBox
操作系统:Ubuntu16.04
Spark版本:3.1.1
Python版本:3.8.5
Spark 的核心是建立在统一的抽象弹性分布式数据集(Resiliennt Distributed Datasets,RDD)之上的,这使得 Spark 的各个组件可以无缝地进行集成,能够在同一个应用程序中完成大数据处理。Spark最大的特点就是将计算数据、中间结果都存储在内存中,大大减少了IO开销,因而,Spark更适合于迭代运算比较多的数据挖掘与机器学习运算。
3.数据来源描述
本次实验数据来源指导老师提供的数据集,每个实验有对应的数据集,三个实验共6个实验数据文件,如下文所示:
实验一,提供分析数据data.txt,该数据集包含了某大学计算机系的成绩,数据格式如下所示:
| Tom,DataBase,80 Tom,Algorithm,50 Tom,DataStructure,60 Jim,DataBase,90 Jim,Algorithm,60 Jim,DataStructure,80 …… |
实验二,提供了两个输入文件(A.txt、B.txt),编写下面是输入文件和输出文件的一个样例:
输入文件A的样例如下:
20200101 x
20200102 y
20200103 x
20200104 y
20200105 z
20200106 z
输入文件B的样例如下:
20200101 y
20200102 y
20200103 x
20200104 z
20200105 y
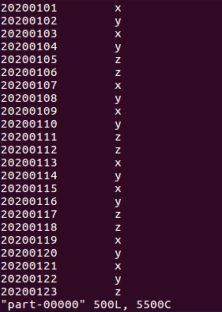
根据输入的文件A和B合并得到的输出文件C的样例如下:
20200101 x
20200101 y
20200102 y
20200103 x
20200104 y
20200104 z
20200105 y
20200105 z
20200106 z
实验三,提供了三个输入文件(Algorithm.txt、Database.txt、Python.txt)表示班级学生某个学科的成绩,下面是输入文件和输出文件的一个样例:
Algorithm成绩:
小明 92
小红 87
小新 82
小丽 90
Database成绩:
小明 95
小红 81
小新 89
小丽 85
Python成绩:
小明 82
小红 83
小新 94
小丽 91
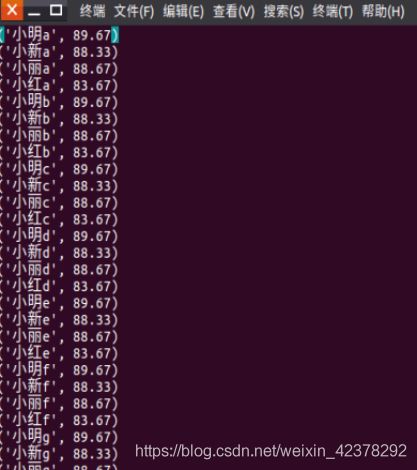
平均成绩如下:
(小红,83.67)
(小新,88.33)
(小明,89.67)
(小丽,88.67)
4.数据上传及上传结果查看
通过软件FileZilla,建立站点管理器,如图1,主机地址中填入虚拟机中的地址如图2,连接虚拟机,从左侧的本地站点将数据传入到右侧的虚拟机站点中路径为 /home/hadoop/下载 的地址中。


5、数据处理过程描述
5.1 pyspark交互式编程
本作业提供分析数据data.txt,该数据集包含了某大学计算机系的成绩,请根据给定的实验数据,在pyspark中通过编程来计算以下内容:
mkdir /usr/local/sparksqldata #创建文件夹
将data.txt文件放置在sparksqldata中
1.该系总共有多少学生;
从本地文件系统中加载数据,通过以下语句得出结果:

2.该系共开设了多少门课程;

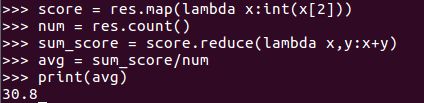
3.Tom同学的总成绩平均分是多少;
首先筛选Tom的成绩数据,使用foreach(print)输出查看

然后计算分数总分,计算成绩个数,用总分除以个数,得出平均值。
4.求每名同学的选修的课程门数;
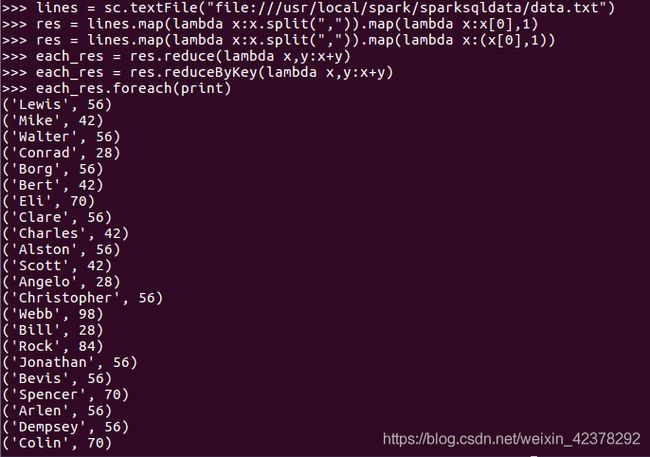
5.该系DataBase课程共有多少人选修;

6.各门课程的平均分是多少;

7.使用累加器计算共有多少人选了DataBase这门课。

5.2 编写独立应用程序实现数据去重
对于两个输入文件A和B,编写Spark独立应用程序,对两个文件进行合并,并剔除其中重复的内容,得到一个新文件C。本实验给出文件(A.txt、B.txt)
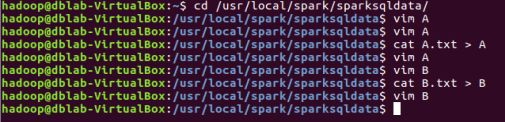
①使用命令 mkdir /usr/local/sparksqldata #创建文件夹
②将A.txt,B.txt文件放置在sparksqldata中
③使用cat命令分别将A.txt、B.txt文件中内容复制到新建的A、B文件中。
④vim C.py #新建C.py文件,在其中使用python语言编写独立应用程序;
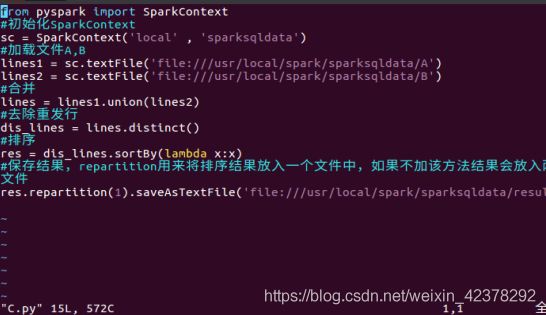
⑤编译 C.py
⑥编译成功结果生成result文件夹中生成part-0000文件。
![]()
文件内容
5.3 编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序求出所有学生的平均成绩,并输出到一个新文件中。本实验给出文件(Algorithm.txt、Database.txt、Python.txt)。
①使用命令 mkdir /usr/local/mycode/avdscore #创建文件夹
②将Algorithm.txt、Database.txt、Python.txt文件放置在/mycode/avdscore中
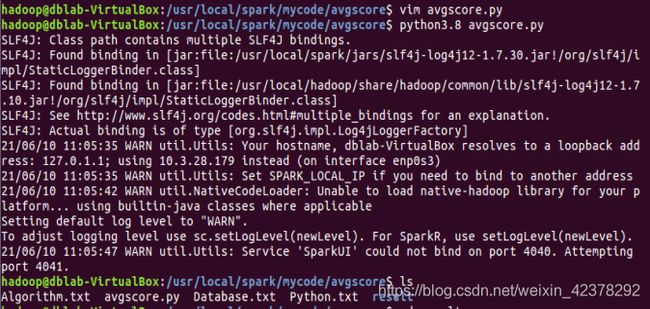
③创建avgscore.py文件 ,编写Spark独立应用程序。
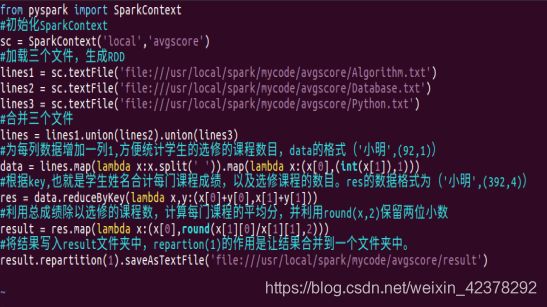
④编译avgscore.py。
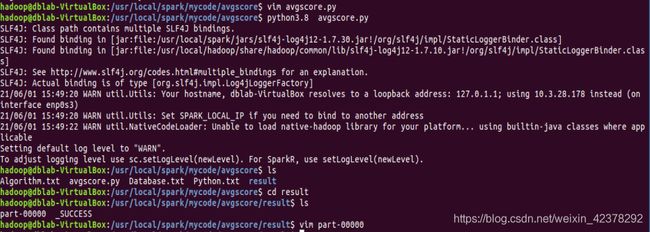
6、经验总结
在实验过程中,遇到一些问题,导致了编译的失败。我在实验过程中为了方便在两个终端都开启了spark,导致端口被占满。解决方法为,关闭一个终端,结束spark进程,再重新启动spark。
实验总结:在本次实验中,我基本上可以熟悉Spark的RDD基本操作及键值对操作;可以熟悉使用RDD编程解决实际具体问题的方法,包括对数据去重、数据的计算与统计、spark的独立应用程序编程等等。对于RDD而言,每一次转换操作都会产生不同的RDD,供给下一个“转换”使用,转换得到的RDD是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,Spark程序执行到行动操作时,才会执行真正的计算,从文件中加载数据,完成一次又一次转换操作,最终,完成行动操作得到结果。