各种经典卷积网络架构介绍
各种经典卷积网络架构介绍
内容来自论文:A Survey of the Recent Architectures of Deep Convolutional Neural Networks
参考网上的翻译:csdnblog
部分内容来自 cs231n 讲义
摘要
- 深度 CNN 的超强学习能力主要是通过使用多个非线性特征提取阶段实现的,这些阶段能够从数据中自动学习分层表征。
- 深度 CNN 架构研究表明,创新的架构理念以及参数优化可以提高 CNN 在各种视觉相关任务上的性能。
- 在表征能力方面的主要改进是通过重构处理单元来实现的。
- 使用块而不是层作为结构单元
介绍
- CNN 具有吸引力的特征是它提取数据中空间或时间关系的能力。
- 卷积核的输出被分配给非线性处理单元,这不仅有助于学习抽象表示,而且还将非线性嵌入到特征空间中。这种非线性为不同的响应生成了不同的激活模式,因此有助于学习图像中的语义差异。
- 非线性函数的输出通常经过下采样,这有助于总结结果,并使输入对于几何变形不变。
- 可以自动学习特征,而不需要很复杂的处理。
- CNN 的重要特点:层次的学习,自动特征提取,多任务和权重共享。
- 当处理复杂的学习问题时,深层架构比浅层架构具有优势。
- CNN 学习策略和结构经过了多种改进,以使CNN可扩展到大而复杂的问题。
- NN的重大创新主要在2012年以来提出,主要包括处理单元的重组和新区块的设计。
- Zeiler 和 Fergus 引入了特征的逐层可视化的概念
- Google 小组提出了一个有趣的想法,即分割、变换和合并,并且相应的块称为 inception 块。
- inception 块首次给出了在层内进行分支的概念,该概念允许在不同的空间尺度上提取特征
- ResNet 引入的用于深层 CNN 训练的跳跃连接概念广为人知,随后,此概念被大多数后续的网络使用,例如 Inception-ResNet,WideResNet,ResNext 等
- 为了提高CNN的学习能力,不同的结构设计,例如 WideResNet,Pyramidal Net,Xception 等,从附加基数和增加宽度的角度探讨了多尺度转换的效果
- 这种转变带来了许多新的体系结构思想,例如通道提升,空间和通道智能开发以及基于注意力的信息处理等。
- 本综述中讨论的各种 CNN 架构可以大致分为以下七个主要类别:空间利用,深度,多路径,宽度,特征图利用,通道提升和基于注意的 CNN
基础的 CNN 模块
- 典型的 CNN 体系结构通常包括卷积和池化层的交替,最后是一个或多个全连接层。在某些情况下,全连接层替换为全局平均池化层。除了学习的各个阶段外,还结合了不同的正则化单元,例如批次归一化和 dropout,以优化 CNN 性能。
- 卷积层由一组卷积核(每个神经元充当核)组成。这些核与图像的一小部分区域相关,称为 感受野。
- 通过使用相同的权重卷积核在整个图像上滑动来提取图像中的不同特征集。
- 与全连接网络相比,卷积运算的这种权重共享功能使 CNN 参数更有效。
- 进行池化或下采样是一个有趣的局部操作。它汇总了感受野附近的相似信息,并在该局部区域内输出主要响应。
- 激活功能起决策功能,有助于学习复杂的模式。选择适当的激活功能可以加快学习过程。
- 不同的激活函数,例如 sigmoid,tanh,maxout,ReLU 和 ReLU 的变体,例如 leaky ReLU,ELU 和 PReLU 用于引入特征的非线性组合。
- ReLU 及其变体优于其他激活函数,因为它有助于克服梯度消失问题。
- 批归一化用于解决与特征图中内部协方差偏移有关的问题。
- 内部协方差偏移量随隐藏层的分布变化
- 会降低收敛速度(通过将学习率设置为小值可以缓解)
- 对参数初始化要求高。
- 内部协方差偏移量随隐藏层的分布变化
- Dropout 引入了网络内的正则化,通过以一定概率随机跳过某些单元或连接来提高泛化性。
- 全连接层通常在网络末端用于分类任务。与池化和卷积不同,它是全局操作。
深度 CNN 的结构进化史
- 深度 CNN 演化史
- 1980年代末至1999年:CNN 的起源
- 1989年,LeCuN 等人提出了第一个名为 ConvNet 的多层 CNN。LeCuN 提出了 ConvNet 的监督训练,使用了反向传播算法,为现代 2D CNN 奠定了基础。成功解决了手写数字和邮政编码识别相关问题。
- 1998年, LeCuN 改进了 ConvNet,并用于文档识别程序中的字符分类。它可以从原始像素中以分层的方式提取特征表示。
- 存在的主要问题:识别能力并未扩展到除手写识别之外的其他分类任务。
- 2000年初:CNN 停滞不前
- 其他统计方法,尤其是 SVM 比 CNN 更为流行
- Simard等人在2003年改进了 CNN 架构,并在 MNIST 上得到了与 SVM 相比更好的结果。
- 通过将其在光学字符识别(OCR)中的应用扩展到其他的字符识别,如部署在视频会议中用于面部检测的图像传感器中以及对街头犯罪的管制等
- 2006-2011年:CNN 的复兴
- Hinton 在 2006 年针对深度架构提出了贪婪的 逐层预训练 方法,从而复兴并恢复了深度学习的重要性。
- 黄等(2006)使用最大池化而不是下采样,通过学习不变特征显示出良好的结果。
- 在 2006 年末,研究人员开始使用图形处理单元(GPU)来加速深度 NN 和 CNN 体系结构的训练。这是改善 CNN 性能和增加其使用的转折点。
- 2012-2014年:CNN 的崛起
- CNN性能的主要突破体现在 AlexNet。AlexNet 赢得了 2012-ILSVRC 竞赛,这是图像检测和分类中最困难的挑战之一。
- AlexNet 通过利用深度提高了性能,并在 CNN 中引入了正则化。
- 2013 年,Zeiler 和 Fergus 定义了一种机制,可以可视化每个 CNN 层学习的滤波器。可视化方法用于通过减小过滤器的尺寸来改进特征提取阶段。
- 牛津大学小组提出的 VGG 架构在2014年 ILSVRC 竞赛中获得亚军,与 AlexNet 相比,其感受野要小得多(11×11变为3×3)。深度从 9 层增加到 16 层和 19 层。
- 提出一个有建设性的观点:三个 3×3 的卷积核堆叠起来的感受野与 7×7 的卷积核感受野相同
- 但是带来的好处是网络更深了,有了更多的非线性,而且有更少的参数
- 同年,赢得 2014-ILSVRC 竞赛的 GoogleNet 不仅致力于通过更改层设计来降低计算成本,而且根据深度扩展了宽度,以改善 CNN 性能。
- GoogleNet 引入了分割、变换和合并块的概念,其中合并了多尺度和多层转换信息以获取局部和全局信息。
- 使用多层转换信息有助于 CNN 处理不同层级的图像细节。
- CNN性能的主要突破体现在 AlexNet。AlexNet 赢得了 2012-ILSVRC 竞赛,这是图像检测和分类中最困难的挑战之一。
- 2015 年至今:CNN 的结构创新和应用迅速增长
- CNN 的表示能力取决于其深度,从某种意义上说,它可以通过定义从简单到复杂的各种级别特征来帮助学习复杂的问题。
- 深度架构所面临的主要挑战是梯度消失的问题。
- 2015 年初,Srivastava 等人使用跨通道连接和信息门控机制的概念来解决梯度消失问题并提高网络表示能力。
- 这个想法在 2015 年末成名,并提出了类似的概念:残差块或跳跃连接。
- 残差块是跨通道连接的一种变体,它通过规范跨块的信息流来平滑学习。
- 这个想法在 ResNet 体系结构中用于训练 150 层深度网络。跨通道连接的思想被 DelugeNet,DenseNet 等进一步扩展到了多层连接,以改善表示性。
- 在 2016 年,研究人员还结合深度探索了网络的宽度,以改进特征学习。
- Hu 等人介绍了特征图开发的思想,并指出少量信息和领域无关的特征可能会在更大程度上影响网络的性能。他利用了上述想法,并提出了名为“挤压和激发网络(SE-Network)”的新架构。

CNN 中的结构创新
- 基于空间利用的卷积网络。通常,小尺寸滤波器会提取细粒度信息,大尺寸过滤器会提取粗粒度信息。这样,通过调整滤波器大小,CNN可以在粗粒度和细粒度细节上均表现良好。
- LeNet。LeNet 由 LeCuN 在 1998 年提出。它以其历史重要性而闻名,因为它是第一个 CNN,显示了手写体识别的最佳性能。
- 结构是 Conv-Pool-Conv-Pool-FC-FC

- LeNet 利用了图像的潜在基础,即相邻像素彼此相关并分布在整个图像中。因此,使用可学习的参数进行卷积是一种在很少参数的情况下从多个位置提取相似特征的有效方法。
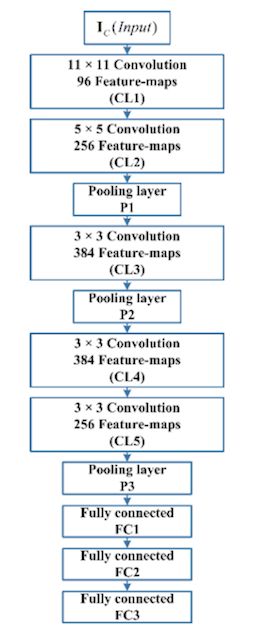
- AlexNet。AlexNet 被认为是第一个深度 CNN架构,它显示了图像分类和识别任务的开创性成果。
- 由于显存的关系,AlexNet 在两张显卡上面训练。
- 使用了 ReLU 来减弱梯度消失的问题。
- 使用了局部相应归一化(但现在已经不常见了)
- 使用了 0.5 的 dropout
- 在初始阶段使用感受野很大的卷积核 (11×11 和 7 × 7)
*
- ZfNet。2013年,Zeiler 和 Fergus 提出了一种有趣的多层反卷积神经网络(DeconvNet),该网络以ZefNet 闻名。
- 开发 ZfNet 是为了定量可视化网络性能。网络活动可视化的想法是通过解释神经元的激活来监视CNN的性能。
- DeconvNet 的工作方式与前向 CNN 相同,但颠倒了卷积和池化操作的顺序。这种反向映射将卷积层的输出投影回视觉上可感知的图像模式,给出了在每一层学习的内部特征表示的神经元级别的解释
- 结果表明在网络的第一层和第二层中只有少数神经元处于活动状态,而其他神经元则死了(处于非活动状态)
- 此外,它表明第二层提取的特征表现出混叠伪像(aliasing artifacts)
- 基于这些发现,Zeiler 和 Fergus调整了 CNN 拓扑并进行了参数优化。Zeiler 和 Fergus 通过减小卷积核尺寸和步幅以在前两个卷积层中保留最大数量的特征,从而最大限度地提高了CNN的学习能力。
- VGG。Simonyan 等人提出了一种简单有效的 CNN 架构设计原则。他们的名为 VGG 的体系结构是模块化的分层模式。在 14 年的比赛中分类排亚军,图像目标定位排冠军。
- VGG的深度为19层,以模拟深度与网络表示能力的关系。
- VGG用 3x3 卷积层的堆叠代替了 11x11 和 5x5 滤波器
- 通过实验证明,同时放置 3x3 滤波器可以达到大尺寸滤波器的效果(感受野同大尺寸滤波器同样有效(5x5和7x7))。
- 小尺寸滤波器的另一个好处是通过减少参数的数量提供了较低的计算复杂性。
- VGG 通过在卷积层之间放置 1x1 卷积来调节网络的复杂性,此外,还可以学习所得特征图的线性组合。
- 为了调整网络,将最大池化层放置在卷积层之后,同时执行填充以保持空间分辨率
- VGG 的主要限制是计算成本太高,参数量太大。

- GoogleNet。GoogleNet 赢得了 2014-ILSVRC 竞赛的冠军,也被称为 Inception-V1。GoogleNet 体系结构的主要目标是在降低计算成本的同时实现高精度。
- 在 CNN 中引入了 inception 块的新概念,通过拆分、变换和合并思想整合了多尺度卷积变换。
- inception 块封装了不同大小的滤波器(1x1、3x3和5x5),以捕获不同尺度(细粒度和粗粒度)的空间信息。
- 有助于解决与学习同一图像类别中存在的各种类型的变体有关的问题。
- GoogleNet 的重点还在于提高 CNN 参数的效率。在采用大尺寸内核之前,GoogleNet通过使用 1x1 卷积滤波器添加**瓶颈层(Bottleneck layer)**来减少计算量。
- 它使用稀疏连接(并非所有输出特征图都连接到所有输入特征图),从而通过省略不相关的特征图(通道)来克服冗余信息和降低成本的问题。
- 通过在最后一层使用全局平均池化来代替全连接层,从而降低了连接密度。

- LeNet。LeNet 由 LeCuN 在 1998 年提出。它以其历史重要性而闻名,因为它是第一个 CNN,显示了手写体识别的最佳性能。
- 基于深度的 CNN。深度 CNN 架构基于以下假设:随着深度的增加,网络可以通过许多非线性映射和改进的特征表示来更好地近似目标函数。理论研究表明,与浅层架构相比,深层网络可以更有效地表示某些功能类别。
- Highway Networks。基于直觉,可以通过增加网络深度来提高学习能力。2015年,Srivastava 等人提出了一个名为 Highway Networks 的深层CNN。
- 通过引入新的跨层连接(在多路径章节中详细讨论),利用深度来学习丰富的特征表示。
- 也被归类为基于多路径的 CNN 体系结构
- 具有 50 层的 Highway Networks 的收敛速度要好于薄而深的架构
- 即使深度为 900 层,Highway Networks 的收敛速度也比普通网络快得多
- ResNet。ResNet由 He 等人提出,被认为是 Deep Nets 的延续。
- ResNet 通过在 CNN 中引入残差学习的概念彻底改变了 CNN 架构,并设计了一种有效的方法来训练深度Nets。
- 也属于多路径的 CNN。
- 使用 152 层的网络,赢得了 2015-ILSVRC 竞赛。
- ResNet 在图像识别和定位任务上的良好性能表明,深度对于许多视觉识别任务至关重要。

- Inception-V3, V4 and Inception-ResNet。
- Inception-V3 的想法是在不影响泛化的情况下降低更深网络的计算成本。
- Szegedy 等用小型非对称滤波器(1x7 和 1x5)替换大型滤波器( 5x5 和 7x7)
- 并在大型过滤器之前使用 1x1 卷积作为瓶颈
- 在 Inception-V3 中,使用了 1x1 卷积运算,该运算将输入数据映射到小于原始输入空间的3或4个独立空间中,然后通过常规 3x3 或 5x5 卷积映射这些较小的3D空间中的所有相关性。
- 在 Inception-ResNet 中,Szegedy 等人结合了残差学习和 Inception 块的作用。这样做时,滤波器的拼接被残差连接所代替。
- 带有残差连接的 Inception-V4(Inception-ResNet)具有与普通 Inception-V4 相同的泛化能力,但深度和宽度增加了。但是 Inception-ResNet 的收敛速度比 Inception-V4 更快,这清楚地说明了使用残差连接进行训练会显著加快对 Inception 网络的训练。
- Inception-V3 的想法是在不影响泛化的情况下降低更深网络的计算成本。
- Highway Networks。基于直觉,可以通过增加网络深度来提高学习能力。2015年,Srivastava 等人提出了一个名为 Highway Networks 的深层CNN。
- 基于多路径的CNN。为了训练更深的网络,研究人员提出了多路径或跨层连接的概念。多个路径或快捷方式连接可以通过跳过某些中间层来系统地将一层与另一层连接,以允许专门信息流的跨层。跨层连接将网络分为几个块。这些路径还尝试通过使较低的层可访问梯度来解决梯度消失问题。
- Highway Networks
- 基于长期短期记忆(LSTM)的递归神经网络(RNN)的启发

- 其中 H 是隐含层的输出,T 是转换门,控制输出与输入的比例
- Resnet(参考上一节)
- 始终传递残差信息,并且永远不会关闭快捷连接。
- DenseNet
- ResNet 存在的问题:它通过附加信息转换显式地保留信息,因此许多层可能贡献很少或根本没有信息。
- 为了解决此问题,DenseNet 使用了一种修改后的跨层连接。
- DenseNet 以前馈的方式将每一层连接到其他每一层,将所有先前层的特征图用作所有后续层的输入。
- 特点
- 由于 DenseNet 是将先前的特征拼接起来,因此,网络可以具有显式区分添加到网络的信息和保留的信息的能力。
- 随之带来的缺点:随着特征图数量的增加,参数量很大。
- 通过损失函数使每一层直接进入梯度,可以改善整个网络中的信息流。这具有正则化效果,
- Highway Networks
- 基于宽度的多连接CNNs
- WideResNet
- 值得关注的是,深度残差网络相关的主要缺点是特征重用问题,其中某些特征转换或块可能对学习的贡献很小
- 深层残差网络的学习潜力主要是由于残差单元,而深度具有补充作用。
- WideResNet 通过使 ResNet 变宽而不是变深来利用残差块的功能
- 引入附加因子k,该因子控制网络的宽度。
- 参数数量是 ResNet 的两倍,但可以比深度网络更好地进行训练
- 更宽的残差网络是基于以下观察结果:与 ResNet 相比,残差网络之前的几乎所有体系结构(包括最成功的 Inception 和 VGG )都更宽。在 WideResNet 中,通过在卷积层之间而不是在残差块内部添加 dropout 来使学习有效。
- Pyramidal Net
- 与 ResNet 随深度的增加而导致的空间宽度的急剧减小相反,金字塔形网络逐渐增加了每个残差单位的宽度。
- 这种策略使金字塔网络能够覆盖所有可能的位置,而不是在每个残差块内保持相同的空间尺寸,直到下采样为止。
- 由于特征图的深度以自上而下的方式逐渐增加,因此被命名为金字塔网。

- 其中,
D_l表示第l个残差单元的维数,n是残差单元的总数,而γ是阶跃因子,并且γ/n调节深度的增加。深度调节因子试图分配特征图增加的负担。 - 金字塔形网络使用两种不同的方法来扩展网络,包括基于加法和乘法的扩宽。两种类型的拓宽之间的区别在于,加法的的金字塔结构线性增加,乘法的金字塔结构在几何上增加。
- 金字塔形网的主要问题在于,随着宽度的增加,空间和时间都发生二次方的增加。
- Xception
- Xception 可以被认为是一种极端的 Inception 架构,它利用了AlexNet 引入的深度可分离卷积的思想。
- Xception修改了原始的 inception 块,使其更宽,并用一个单一的维度(3x3)紧跟 1x1 替换了不同的空间维度(1x1、5x5、3x3),以调节计算复杂度。
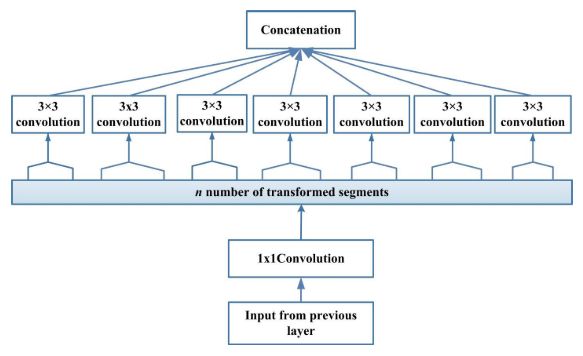
- Xception 通过解耦空间和特征图(通道)相关性来提高网络的计算效率。
- 它先使用 1x1 卷积将卷积输出映射到低维嵌入,然后将其空间变换
k次,其中k为cardinality 的宽度,它确定变换的次数。 - 在传统的 CNN 架构中,传统的卷积运算仅使用一个变换的分段,Inception 使用三个变换的分段,而在 Xception 中,变换分段的数量等于特征图的数量。尽管 Xception 采用的转换策略不会减少参数的数量,但是它使学习更加有效并提高了性能。
- ResNext,Aggregated Residual Transform Network,聚合残差变换网络,是对 Inception 网络的改进。
- Inception 网络存在的缺陷:由于在转换分支中使用了多种空间嵌入(例如使用3x3、5x5和1x1滤波器),因此需要分别自定义每一层。
- 主要思想:通过多个并行的通路增加网络的宽度。
- ResNext 通过将 split,transform 和 merge 块中的空间分辨率固定为 3x3 滤波器,利用了 VGG 的深度同质拓扑和简化的 GoogleNet 架构。它还使用残差学习。ResNext 的构建块如下图所示。ResNext 在 split,transform 和 merge 块中使用了多个转换,并根据 cardinality 定义了这些转换。

- WideResNet