ElasticSearch 核心概念(倒排索引的压缩算法)
ElasticSearch 核心概念
- 搜索引擎
-
- 什么是搜索引擎?
- 搜索引擎应该具备哪些要求?
- 面向海量数据,如何达到“搜索引擎”级别的查询效率?
-
- 数据库的组成结构
- MySQL的索引结构
- MySQL索引能解决大数据检索的问题吗?
- ElasticSearch引擎
-
- Lucene
- 全文检索
- 倒排索引核心算法
-
- 原理
- 倒排表的压缩算法
-
- FOR压缩算法(稠密)
- RBM压缩算法(稀疏)
搜索引擎
什么是搜索引擎?
全文搜索引擎
自然语言处理(NLP)、爬虫、网页处理、大数据处理
如谷歌、百度、搜狗、必应等等
垂直搜索引擎
有明确搜索目的的搜索行为
各大电商网站、OA、站内搜索、视频网站等
搜索引擎应该具备哪些要求?
查询速度快
1.高效的压缩算法
2.快速的编码和解码速度
结果准确
1.BM25
2.TF-IDF
检索结果丰富
召回率
面向海量数据,如何达到“搜索引擎”级别的查询效率?
索引
- 帮助快速检索
- 以数据结构为载体
- 以文件的形式落地
数据库的组成结构
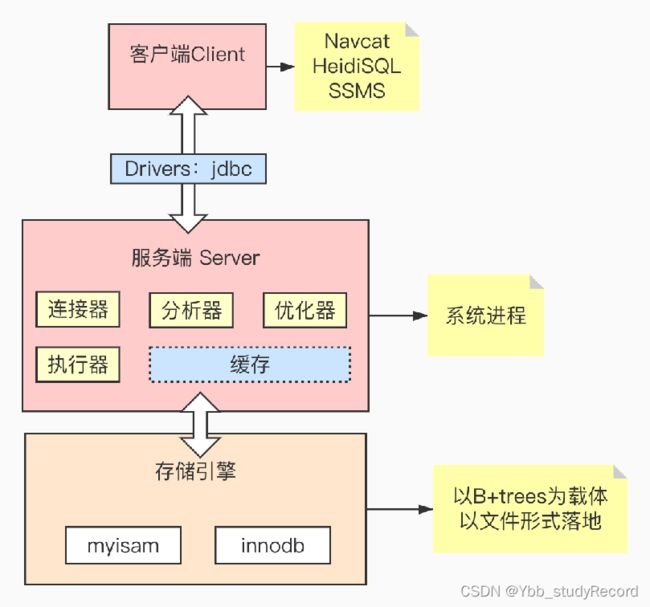
- MySQL、Oracle、SQL Server、PostgreSQL
- Redis、Memcached、MongoDB
- Elasticsearch、Solr、Splunk
MySQL的索引结构
B-Trees
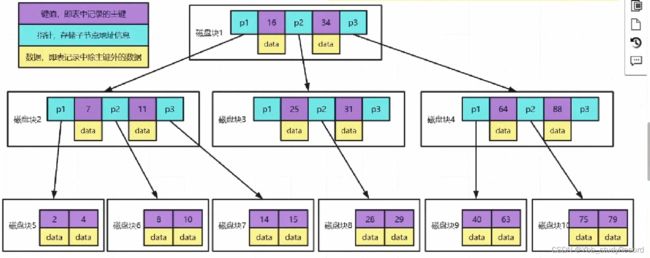
B+Trees
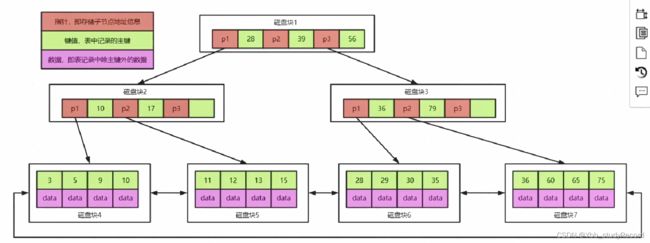
MySQL索引能解决大数据检索的问题吗?
1、索引往往字段很长,如果使用B+trees,树可能很深,IO很可怕
2、索引可能会失效
3、精准度差
ElasticSearch引擎
Lucene
Lucene是一个成熟的全文检索库,由Java语言编写,具有高性能、可伸缩的特点,并且开源、免费。
Lucene的作者Doug Cutting是资深的的全文检索专家,Lucene最开始发布在他本人的主页上,2001年10月贡献给Apache,成为Apache基金会的一个子项目。
Lucene是一个IR库(Information Retrieval library)。后来才由Shay Banon在其基础上开发了Elasticsearch
全文检索
全文检索:索引系统通过扫描文章中的每一个词,对其创建索引,指明在文章中出现的次数和位置,当用户查询时,索引系统过就会根据事先简历的索引进行查找,并将查找的结果反馈给用户的检索方式

先经过一个buffer缓冲区,每过一段时间会refresh,此时会产生一个segment文件
倒排索引核心算法
原理

每个词拆分成一个一个词项字典,建立词项到词项id的映射关系。就是倒排索引的构建过程
term index:快速检索词项字典
term dictionary:词项字典
Posting List:哪些id包含了这个词项
倒排表的压缩算法

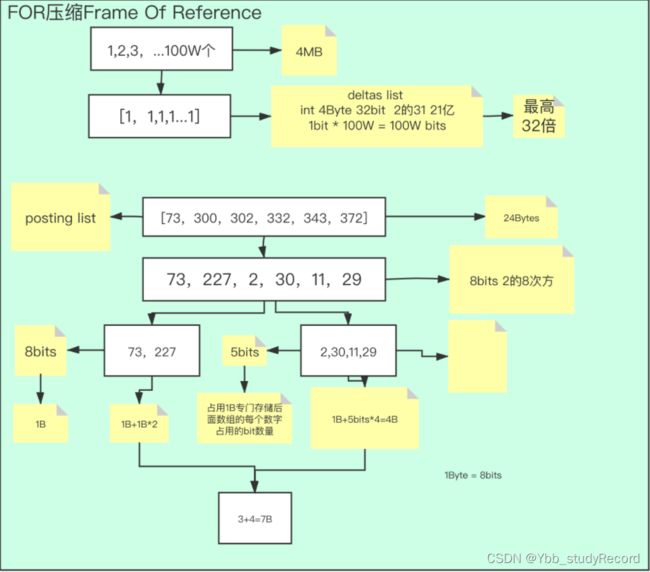
FOR压缩算法(稠密)
1,2,3,4,5…100W个
如果Posting List里每个id都用int存储
1int=4Byte
400W Byte≈4MB
如果有10亿条数据,每条数据会拆分成多个词项,每个词项4MB,那么可能倒排索引存储的大小会大于实际存储的数据,那怎么进行压缩呢?
用bit存储,1Byte=8bit
0 0 0 0 0 0 0 0
存储的数字大小就是2的多少比特数。
一个int=4个Byte=32个bit=2的31次方 大概21亿
存储的时候使用差值列表
例子一
1,2,3,4,5…100W
1,1,1,1,1…1
本来是48100W=3200W个bit
现在只需要 100W个bit即可 压缩了32倍
例子二
73,300,302,332,343,372
73,227,2,30,11,29
4Byte*6=24Byte
8bit 73和227
5bit 2,30,11,29
会有一个问题:为何不继续往下压缩,每个bit分?
当前是在编码,但是高效的压缩算法,是需要解码(可逆的)。当前的8bit和5bit是一个数组,需要占用存储空间的,是一个字节1Byte,如果压缩太多,数组会很多,反而会占用压缩空间。
这是一个动态值,根据每个数组中存储的量的稠密度来。
RBM压缩算法(稀疏)
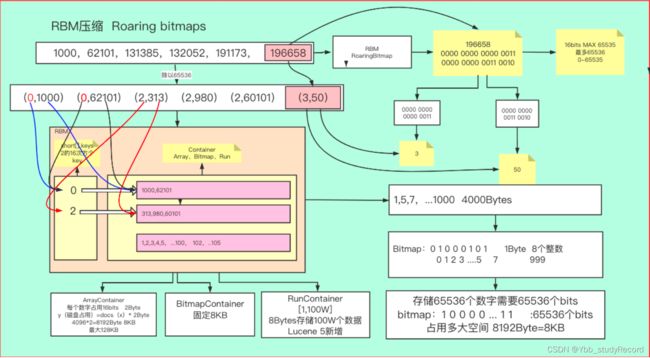
如果数组中的差值比较大(稀疏数据),会使用到RBM压缩算法。
使用除法,一个int类型,拆分成两个short类型相乘 2的16次方 ✖️ 2的16次方
196658/65535 0000 0000 0000 0011
196658%65535 0000 0000 0011 0010
得到两个值,3和50,也就是高16位和低16位
高16位用一个short数组存储
低16位用Container存储
- Array Container,short类型,2个字节 4096个文档数,40962/1024=8KB 65536个id的话 655362/1024=128KM
- BitMap Container,0 0 0 0 0 0 0 0 ,1用来作为标记是否存在 比如0 0 0 0 1 0 0 0 也就是3。那么就需要存储65535个bit来存储一个值,65535/8/1024=8KB
- Run Container,数组有序的情况下压缩比率会很高。 1,2,3,4,5…100W个 数组只需要存储[1,100W]即可,本来400W个字节,现在只需要8个字节。取决于连续有序数组个数。
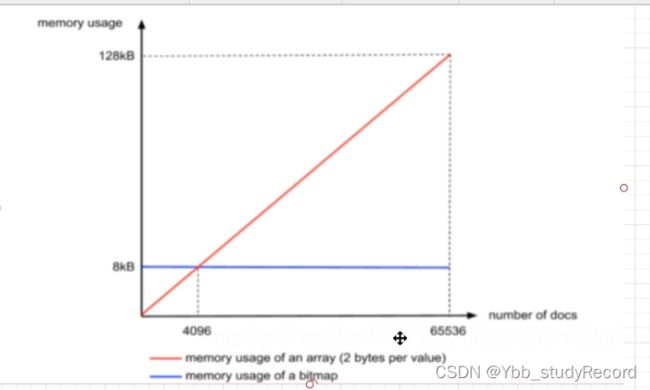
如果个数小于4096个 用ArrayContainer
大于4096用BitMapContainer合适