Elasticsearch - 倒排索引
在上一篇笔记Elasticsearch基础和原理中介绍了Elasticsearch的一些基本概念和原理,我们知道Elasticsearch是基于Json格式存储,每一个文档可以理解成一个json对象。这看起来和MySQL(InnoDB)完全不同的存储方式,是如何做到近乎实时检索的呢?这篇笔记就来学习一下倒排索引
简单的倒排索引示例
假如我们在ES中存在这样三条记录:
{
"_id": 1,
"log": "Oscar is fourteen years old",
}
{
"_id": 2,
"log": "Tom likes fourteen kinds of flowers.",
}
{
"_id": 2,
"log": "Oscar eats fourteen apples yestoday.",
}
那么在ES中会构建类似如下的倒排索引:
| Term | Posting list |
|---|---|
| oscar | [1, 3] |
| fourteen | [1, 2, 3] |
| flower | [2] |
| apple | [3] |
ES对每个文档的内容做分词处理,并记录每个分词结果对应的稳定id列表,这样假如我们在搜索关键词fourteen,通过倒排索引,可以快速知道文档[1, 2, 3]都包含此关键词,随即返回文档1, 2, 3的内容即可;同理,搜索flower将返回文档2, 搜索oscar将返回文档1, 3
倒排索引的基本概念
term
term本身的含义为:
a word or expression that has an exact meaning in some uses
在某些方面有特定意义的一个单次或者表达式
在Elasticsearch中,文档内容经过分词器解析后得到的一系列关键字,就成为term。如在上面的简单示例中,oscar, eighteen, flower, apple都是关键词
posting list
在Elasticsearch的倒排索引中,每个关键词term都有对应包含该关键词的文档列表,列表项一般为文档id;如上述示例中:
关键词oscar对应的posting list为[1, 3]
表示id为1, 3的文档包含关键词oscar
term dictionary
term dictionary存放所有term和posting list对应关系,Elasticsearch使用如下的方案快速找到一个term对应的文档id列表:
term是排序的,那么ES就可以通过二分查找,快速定位某个term对应的posting list- 【伪】将
term dictionary加载到内存,避免二分查找时频繁从磁盘中加载对应段的数据
然而由于ES一般文档数较多,term和posting list的数据量都很大,全部加载到内存不太现实,因此,ES在term dictionary存储在磁盘的前提下,使用term index加速term的定位
term index
term index使用前缀树trie tree记录某个term在磁盘中的哪个block,同时term index在内存中以FST(finite state transducers)的形式保存,可以节约大量内存空间
这样,当要查找某个term时,先从内存前缀树中获取该term所在的term dictionary在哪个磁盘块,然后加载该磁盘块,并查找该term获取posting list
注:对于前缀树和FST的细节,这里暂时不做深入探究,先做定性了解
倒排索引的整体结构如下:
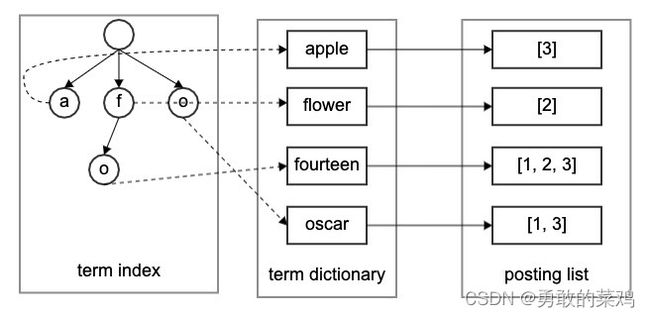
构建倒排索引
构建倒排索引主要分为以下几步:
- 确认需要构建索引的文档。一般情况下,一个索引下的所有文档都需要进行倒排索引构建
- 分词。通过特定的分词器将文档内容划分为一个个独立的关键字
term- ES支持指定不同的分词器,这里不做深入探讨。分词器附带一些额外功能,比如
- 关键字归一化,如
flowers=>flower - 忽略无意义的词条,如
is,of等
- 关键字归一化,如
- ES支持指定不同的分词器,这里不做深入探讨。分词器附带一些额外功能,比如
- ES给每个
field建立独立的倒排索引,包含几个关键步骤:- 关键词对应
posting list统计,一个文档中出现多次的关键词,posting list去重 - 关键词
term排序,构建term dictionary - 构建关键词前缀树
- 关键词对应
倒排索引的查找
单次条查找
单个词条查找的过程比较简单,已示例中的查找log: oscar为例:
- 在**内存中的
term index**找到termoscar对应的磁盘块 - 加载该磁盘块,从
term dictionary中找到oscar对应的posting list为[1, 3] - 拿到文档id后,在对应分片所在节点上查询文档内容并返回
多词条查找
比如我们要查询log: oscar apple,即包含这两个关键字的文档结果。
多词条查询会在单词条查询的基础上,做一次合并操作。即先找到oscar的文档列表,再找apple的文档列表,取其交集即为要查询的结果。ES处理合并有自己的做法,如使用skip list或者bitset,这里暂时就不深入了。感兴趣可以网上再找资料看看。
倒排索引和B+树索引
在学习ES和倒排索引的过程中,一直有这样的思考和疑惑。为什么ES可以做到大量数据文本的模糊搜索,但是MySQL(或者说关系型数据库)不行?倒排索引和MySQL的B+数索引又有什么区别?
为什么倒排索引大量数据模糊查询,MySQL不行?
MySQL作为关系型数据库的代表,它的字段和索引不具有灵活性;一个MySQL数据表在创建时其字段和索引基本已经确定,如示例中的场景,在MySQL中大概率log是独立一列,且不会加索引,那么在模糊查询时,我们要使用like "%oscar%这样的语句,显然这会导致全表扫描,所以大量数据时性能极低,基本不可用
Elasticsearch的索引机制基于分词,它是灵活的;一个新插入的文档出现的新的term,那针对这个term就会产生一个新的索引项,查询固然更加高效了
当然,我们忽略了一个最重要的区别,使用场景
关系型数据库使用正向索引,根据id查内容,且重点在于数据之间的关联;ES使用反向索引(倒排索引),使用关键词查id,当然最终也要根据id获取内容,重点在灵活多变的文档
倒排索引和B+数索引的区别
- B+树索引和倒排索引中
term dictionary相似,都是使用类二分算法定位索引项,前者利用数据页减少和磁盘的交互,后者使用term index减少和磁盘交互