Fingerprint Compression Based on Sparse Representation(基于稀疏表示的指纹压缩算法)
G. Shao, Y. Wu, A. Yong, X. Liu and T. Guo, "Fingerprint Compression Based on Sparse Representation," in IEEE Transactions on Image Processing, vol. 23, no. 2, pp. 489-501, Feb. 2014, doi: 10.1109/TIP.2013.2287996.
论文链接:Fingerprint Compression Based on Sparse Representation | IEEE Journals & Magazine | IEEE Xplore
目录
摘要:
1、介绍
4、指纹稀疏表示
A:构建字典
B、压缩指定的指纹
C、量化和编码
D、算法复杂度分析
5、实验
A、数据集
B、基于稀疏表示指纹压缩算法的可行性
C、不同字典的实验结果
D、选择算法的参数
E、与现有指纹压缩算法比较
F、设计训练集
G、鲁棒性
4、结论
摘要:
提出了一种新的基于稀疏表示的指纹压缩算法,从一组指纹补丁中获得一个过完备的字典允许我们将它们表示为字典原子的稀疏线性组合。在该算法中,我们首先为预定义的指纹图像补丁构造一个字典。对新给定的指纹图像,通过计算l0-极小化,根据字典表示其补丁,然后对其表示进行量化和编码。本文考虑了各种因素对压缩结果的影响。测试了三组指纹图像。实验证明我们的算法与几种竞争的压缩技术(JPEG,JPEG 2000和WSQ),特别是在高压缩比的情况下。实验结果表明,该算法对细节的提取具有较好的鲁棒性。
1、介绍
利用生物特征识别人是社会上一项重要的技术,因为生物特征识别不能被共享,它们本质上代表了个人的身体身份。在众多的生物特征识别技术中,指纹识别由于其唯一性、普适性、可收集性和不变性等优点,在个人身份识别中非常受欢迎。
大量的指纹每天被收集和存储在广泛的应用中,包括取证和访问控制。大量的数据消耗大量的内存。指纹图像压缩是解决这一问题的关键技术。
一般来说,压缩技术可以分为无损压缩技术和有损压缩技术。无损压缩允许精确的原始图像从压缩数据重建。在原始数据和解压缩数据必须相同的情况下使用无损压缩技术。避免失真限制了它们的压缩效率。在可接受轻微失真的图像压缩中,无损压缩技术通常用于有耗压缩的输出系数。有损压缩技术通常将图像转换到另一个域,量化并编码其系数。在过去的三十年中,基于变换的图像压缩技术得到了广泛的研究,并出现了一些标准。两个最常见的变换选项是离散余弦变换(DCT)[2]和离散小波变换(DWT)[3]。
基于dct的编码器可以被认为是8 × 8小块图像流的压缩。JPEG[4]中采用了这种转换。JPEG压缩方案具有简单、通用性和可用性等优点。然而,由于底层基于块的DCT方案,它在低比特率时的性能很差。因此,早在1995年,JPEG委员会就开始开发一种新的基于小波的静态图像压缩标准,即JPEG 2000[5],[6]。基于小波变换的算法包括三个步骤:归一化图像的小波变换计算、小波变换系数的量化和量化系数的无损编码。细节可以在[7]和[8]中找到。与JPEG相比,JPEG 2000提供了许多支持对大尺寸图像进行可扩展和交互式访问的特性。它还允许提取不同的分辨率,像素保真度,感兴趣的区域,组件等。还有其他一些基于dwt的算法,例如分层树集分区(SPIHT)算法[9]。
以上算法适用于一般的图像压缩。针对指纹图像,有专门的压缩算法。最常见的是小波标量量化(WSQ)。它成为了FBI压缩500dpi指纹图像[7]的标准。受WSQ算法的启发,一些基于小波包的指纹压缩方案已经被开发出来。除了WSQ,还有其他的指纹压缩算法,如Contourlet Transform (CT)[10]。
这些算法都有一个共同的缺点,即缺乏学习能力。指纹图像现在还不能很好的压缩。它们以后不会被很好地压缩。本文提出了一种基于稀疏表示的新方法。提出的方法具有更新的学习字典。具体过程如下:
- 参照列为原子的矩阵字典,构造列表示指纹图像特征的基矩阵;对于一个给定的完整指纹,将其分成小块,称为小块,这些小块的像素数与原子的尺寸相等;采用稀疏表示的方法求得系数;
- 然后,量化系数;
- 最后,采用无损编码方法对系数和其他相关信息进行编码。
在大多数情况下,算法的压缩性能评价仅限于峰值信噪比比率(PSNR)计算。对实际指纹匹配或识别的影响没有进行研究。在本文中,我们将考虑到这一点。在大多数自动指纹识别系统(AFIS)中,用于匹配两张指纹图像的主要特征是细节(脊、尾和分叉)。因此,本文考虑了压缩前后细节的差异。
4、指纹稀疏表示
该部分包括字典的构建、给定指纹的压缩、量化编码和算法复杂度分析。当字典中包含尽可能多的信息时,它的大小可能会太大。要获得一个中等大小的字典,预处理是必不可少的。受变换、旋转和噪声的影响,同一根手指的指纹可能看起来非常不同。我们首先想到的是每个指纹图像都是预先对齐的,最常用的预对准技术是根据核心点的位置对指纹进行平移和旋转。不幸的是,在质量较差的指纹图像中,可靠的核检测是非常困难的。即使正确地检测到了核心,由于整个指纹图像的大小太大,字典的大小也可能过大。
与一般自然图像相比,指纹图像具有更简单的结构。它们仅包含脊和谷。因此,为了解决这两个问题,我们将整个图像切成正方形且不重叠的小块。对于这些小的补丁,变换和旋转是没有问题的。字典的大小不会太大,因为小块相对较小。
A:构建字典
- 构建一个训练集
- 字典从集合中获得
- 选择完整的指纹图像,将其切割成固定大小的方形小块。针对这些经过初步筛选的小块,利用贪心算法构造训练样本。
第一个补丁被添加到字典中,字典最初是空的。然后检查下一个补丁是否与字典中的所有补丁足够相似。如果是,则测试下一个补丁;否则,补丁将被添加到字典中。这里通过求解优化问题(5)来计算两个补丁之间的相似性度量。
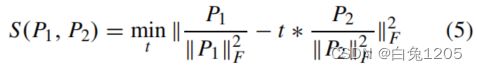
Frobenius范数,P1和P2两个patch的对应矩阵,t是优化问题(5)的一个参数(一个比例因子)
在构造字典之前,先计算每个patch的平均值,并从对应的patch中减去。
三种方法:
- 第一种方法:从训练样本中随机选择指纹补丁,将这些补丁排列为字典矩阵的列。
- 第二种方法:来自指纹前景的斑块有方向,而来自指纹背景的斑块没有方向,如图2所示。 这一事实可以用来构造字典。把间隔[0,…, 180]变成等大小的间隔。每个区间用一个方向表示(选择每个区间的中间值)。为每个间隔选择相同数量的补丁,并将它们排列到字典中。
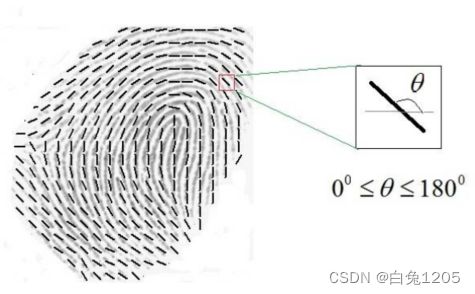 图2所示:在正方形网格上计算的指纹图像及其相应的方向图像。每个元素表示当地指纹脊的取向。
图2所示:在正方形网格上计算的指纹图像及其相应的方向图像。每个元素表示当地指纹脊的取向。
- 第三种方法:K-SVD,字典是通过迭代求解优化问题(6)得到的。Y由训练补丁构成,A为字典,X为稀疏系数,使用MP方法计算系数矩阵X,这保证了系数向量Xi不超过T个非零元素。然后,基于奇异值分解(SVD)更新每个字典元素。
B、压缩指定的指纹
给定一个新的指纹,将其切成与训练补丁大小相同的方形补丁。切片的大小直接影响着压缩效率。随着大小的增加,算法的效率会提高。然而,字典的计算复杂度和容量也在迅速增加。应该选择合适的尺寸。如何选择这个尺寸将在第五节给出。此外,为了使补丁更适合字典,需要计算每个补丁的平均值,并从补丁中减去。通过求解l0的问题来计算每个patch的稀疏表示。绝对值小于给定阈值的系数视为零。对于每个补丁,需要记录四种信息,它们是平均值,关于使用多少原子的数字,系数和它们的位置。试验表明,许多图像补丁所需的系数很少。因此,与使用固定数量的系数相比,该方法降低了编码复杂度,提高了压缩比。
C、量化和编码
用静态算术编码器[35]对各小块的原子数、各小块的平均值、系数和指标进行熵编码。每个补丁的原子编号是单独编码的。每个补丁的平均值也分别编码。系数的量化使用Lloyd算法[36]执行,离线学习从MP算法在字典上的训练集获得的系数。每个块的第一个系数用比其他系数更大的比特数量化,并使用单独的算术编码器进行熵编码。使用离线从训练集中获得的源统计信息估计指标的模型。第一索引和其他索引由相同的算术编码器编码。在接下来的实验中,第一个系数用6位量化,其他系数用4位量化。
D、算法复杂度分析
该算法包括两个部分,即训练过程和压缩过程。由于训练过程是离线的,所以只分析了压缩过程的复杂性。假设patch的大小为m × n,字典中的patch数量为n。每个block用L系数编码。L是的平均值系数向量中的非零元素。为了表示一个相对于字典的补丁,MP算法的每次迭代都包含mnN个标量积。每个patch的标量乘法总数为LmnN。给定一个M1 × N1像素的完整指纹图像。
算法1总结了完整的压缩过程。压缩流不包括字典和关于模型的信息。它只包括每个补丁的原子数编码、每个补丁的平均值、系数加上索引。实际上,只需要传输压缩流就可以恢复指纹。在编码器和解码器中,都需要存储字典、系数量化表和用于算术编码的统计表。在我们的实验中,这导致小于6 Mbytes。压缩率等于原始图像的大小与压缩流的大小之比。

5、实验
介绍了用于指纹压缩的指纹数据库的实验,目的是证明所提出的压缩算法的可行性,并验证前几节的声明。
- 首先介绍使用的数据集
- 验证了该方法的可行性,并给出了在三种不同字典上的实验结果
- 研究如何选择合适的参数
- 将我们的方法与现有的指纹压缩算法(如WSQ、JPEG和JPEG 2000)进行比较。
- 研究稀疏表示中的一个重要问题,即如何设计训练集。
- 实验结果表明,该算法对提取细节信息具有较好的鲁棒性
A、数据集
为了构造一个指纹补丁字典,我们使用了一组包含主要模式类型的训练指纹。这个集合中不同模式的分布不一定与另一个数据库中的分布相似。有5组指纹图像(称数据库1、数据库2、数据库3、数据库4、数据库5)。
- DATABASE 1: 18个指纹作为训练集
- DATABASE 2: 30个用于选择适当参数的指纹。
- DATABASE 3:50个指纹用于比较我们的方法与现有的指纹压缩算法,并测试我们的算法提取细节的鲁棒性。然后,根据奇异值分解(SVD)更新每个字典元素。
-
DATABASE 4:FVC2002_DB3_B公共指纹库,包含80个大小为300 × 300的指纹,用来与现有的指纹压缩算法进行比较
-
DATABASE 5:FVC2004_DB2_B,包括大小为328 × 364的80个指纹,也用于将我们的方法与现有的指纹压缩算法进行比较。
在以上五组指纹图像中,前三组来自同一数据库。数据库中的指纹大小为640 × 640。数据库中指纹的质量较好。三组指纹图像可从[37]下载。为了显示从DATABASE 1训练出来的字典对于指纹图像是通用的,我们还测试了DATABASE 4和DATABASE 5。
B、基于稀疏表示指纹压缩算法的可行性
证明指纹块确实具有稀疏表示:如图4(a)、4(b)、4(c)所示,只有少数系数较大,其他系数近似等于零。
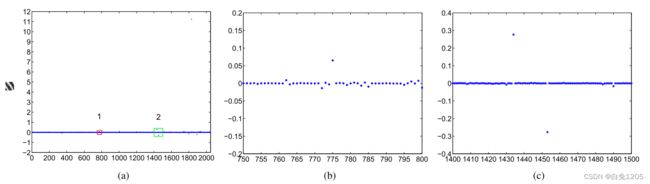 图4:一个20 × 20大小的补丁的表示。4(a)字典下的补丁及其l1-minimization表示。图4(b)块1的放大图像如图4(a)所示。4(c)块2的放大图像如图4(a)所示。
图4:一个20 × 20大小的补丁的表示。4(a)字典下的补丁及其l1-minimization表示。图4(b)块1的放大图像如图4(a)所示。4(c)块2的放大图像如图4(a)所示。
更令人惊讶的是,许多补丁只有一个大系数,如图3.
 图3:只有一个大系数的小块的表示。左边的小图像是一个20 × 20大小的补丁。右边的图是在400 × 2048的字典下用l1-minimization表示的patch。
图3:只有一个大系数的小块的表示。左边的小图像是一个20 × 20大小的补丁。右边的图是在400 × 2048的字典下用l1-minimization表示的patch。
在某些特殊情况下,一些补丁没有系数,例如来自背景的大部分补丁数据库1、数据库2和
数据库3。用它们的平均值来表示这些补丁已经足够好了。这些实验表明,斑块可以表示为少数列的线性组合。这使得所提出的指纹压缩方法具有可行性。
C、不同字典的实验结果
本节研究了不同字典对指纹压缩的影响。正如我们在前一节中所说的,有三种不同的方法来构造字典。这里,第一个是随机选择4096个补丁,并将它们排列为字典的列(简称Random-SR)。二是根据朝向(Orientation-SR)选择补丁。在实验中,有8个方向。如图5所示,共100个patch,朝向450,尺寸20×20。三是采用K-SVD方法(简称K-SVD- sr)训练字典。
 图5:100补丁,方向45,尺寸20 × 20
图5:100补丁,方向45,尺寸20 × 20
在实验中,测试集为DATABASE 2,训练集为DATABASE 1。字典的大小是144 × 4096。对于每像素8位的灰度图像,PSNR计算为:

MSE:

M’和N是指纹的长度I和I‘是原始图像和重建图像的强度。
表一和图6显示了在不同字典下所提算法的性能。
 表1:三种方法在数据库3上建立字典的PSNR (db)的平均值
表1:三种方法在数据库3上建立字典的PSNR (db)的平均值
 图6:所提算法在不同字典下的平均性能,对于所选系数的不同百分比。
图6:所提算法在不同字典下的平均性能,对于所选系数的不同百分比。
图6中的横轴表示每个patch所选系数的百分比,纵轴表示PSNR的平均值。如果与给定百分比对应的所选系数的数量不是整数,则将其四舍五入到最接近的整数。接下来的实验采用同样的处理方法。这些结果表明K-SVD-SR优于其他两种方法。另外一个实验表明,在144 × 4096的字典下,K-SVD-SR的性能仍然优于直接排列所有patch获得的字典(26843块)。在系数为1、4、7和10%时,144 × 26843字典下的PSNR均值分别为21.25dB、27.75dB、29.71dB和30.95dB。结论是,适当的训练方法是必要的,如何构建词典是重要的。从图6中也可以看出,Orientation-SR与Random-SR的性能几乎相同。在没有训练过程的情况下,补丁是否精心选择并没有什么区别。在接下来的实验中,字典是用第三种方法构造的。
D、选择算法的参数
在实验中,训练集为DATABASE 1,测试集为DATABASE 2。
对于基于稀疏表示的压缩,最重要的参数是补丁的大小和字典的大小。补丁的大小直接影响着压缩效率。尺寸越大,效率越高。然而,要很好地表示任意补丁,字典的大小需要足够大。这导致了更多的计算复杂性。到目前为止,还没有很好的方法来估计这个参数。补丁的大小通过实验进行选择。考虑12×12、16×16和20×20的大小。没有测试8 × 8的大小有两个原因。一方面,这种尺寸的补丁太小,无法包含指纹的结构。另一方面,在高压缩下压缩如此小的补丁是很困难的。图7可以看到,当字典中的原子数为4096时,大小为12 ×12的效果最好。
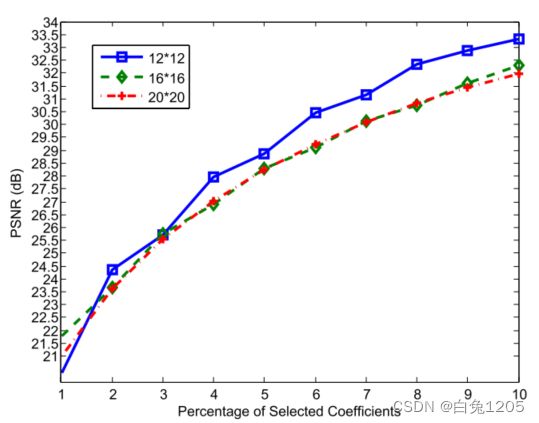 图7所示:在不同尺寸的patch下,对于不同百分比的选定系数,所提算法的平均性能。
图7所示:在不同尺寸的patch下,对于不同百分比的选定系数,所提算法的平均性能。
在已知补丁大小的情况下,可以通过实验估计字典的大小。我们训练6个大小分别为144×256, 144×512, 144×1024, 144×2048, 144×4096,144×8192。测试了1、4、7和10%的系数。结果如图8所示。
 图8所示:在1、4、7和10%的系数下,用不同大小的字典重建图像的PSNR。
图8所示:在1、4、7和10%的系数下,用不同大小的字典重建图像的PSNR。
如图所示,一开始,重构的指纹图像的质量随着的大小而提高字典在增加。这种增长是次线性的。在8192点,曲线的趋势发生了变化。4096点的PSNR大于该点的PSNR值7和10%的系数是8192。这是因为例数有限导致字典过度拟合。
在接下来的实验中,patch的大小为12 ×12,字典的大小为144 × 4096。
E、与现有指纹压缩算法比较
在本节中,我们将提出的方法与现有的指纹压缩算法进行比较。我们的算法和所有其他算法都是在同一个数据库上实现和测试的。我们的压缩算法是在Matlab中实现的。我们使用三种不同的图像压缩算法,JPEG, jpeg2000和WSQ,这些算法在之前已经被广泛描述过。标准JPEG是几乎所有图像处理工具的一部分,我们不再进一步参考它。我们使用的基于小波的jpeg2000是由Matlab提供的。WSQ算法是由互联网上免费下载的软件[38]提供的。
实际上,有些指纹图像的大小不是补丁大小的数倍。如果出现这种情况,则将指纹图像的左侧按照给定的顺序排列到与补丁大小相同的列向量中。我们采用的顺序是第一行和第二列。这些列向量可以用MP算法在同一个字典下表示。
在实验中,很难在给定的压缩比下准确地压缩每个指纹图像。我们从不小于给定值的数中选择最接近的一个压缩比减去2.5作为最终压缩比。表II给出了数据库3、数据库4和数据库5上的真实压缩比与给定压缩比之间的差异的平均值和方差。
 表二:实际压缩比与给定压缩比之差的平均值和方差压缩比。对于每个网格,左边是平均值,右边是方差
表二:实际压缩比与给定压缩比之差的平均值和方差压缩比。对于每个网格,左边是平均值,右边是方差
1)在数据库3上的实验结果:图9和表三展示我们算法、JPEG、JPEG2000、WSQ的平均性能
 图9所示:提出的算法的平均性能以及JPEG, jpeg2000和WSQ算法,在不同的压缩比上数据库3。
图9所示:提出的算法的平均性能以及JPEG, jpeg2000和WSQ算法,在不同的压缩比上数据库3。
 表三:不同算法在数据库3上得到的PSNR (db)的平均值和方差。对于每个网格,左边是均值,右边是方差
表三:不同算法在数据库3上得到的PSNR (db)的平均值和方差。对于每个网格,左边是均值,右边是方差
在图中,横轴上的20表示20:1的压缩比。与JPEG和WSQ相比,jpeg2000的PSNR和我们方法的PSNR始终较高。从图中可以看出,当压缩比较高时,该算法的性能优于jpeg2000算法。然而,在10:1的压缩比下,jpeg2000比我们的更好。我们认为,其原因是基于稀疏表示的方法不能很好地反映细节。这就是这种方法的缺点。当压缩比较高且细节不重要时,基于稀疏表示的方法具有明显的优势。这一点也可以在对比图中找到。
图12展示了使用不同算法在压缩比30:1下获得的重建图像的质量。从这些重建图像可以看出,我们的算法取得了良好的视觉恢复效果。在高压缩比下,我们算法的块效应比JPEG算法要轻。
 图12所示:(a)原始图像,奇点处的面积,大小为300 × 300, (b) JPEG, (c) JPEG 2000, (d)WSQ, (e)压缩比为30:1的建议方法。
图12所示:(a)原始图像,奇点处的面积,大小为300 × 300, (b) JPEG, (c) JPEG 2000, (d)WSQ, (e)压缩比为30:1的建议方法。
2)在数据库4下的实验结果:
图10、表IV显示了所提算法JPEG、jpeg2000和WSQ的平均性能。
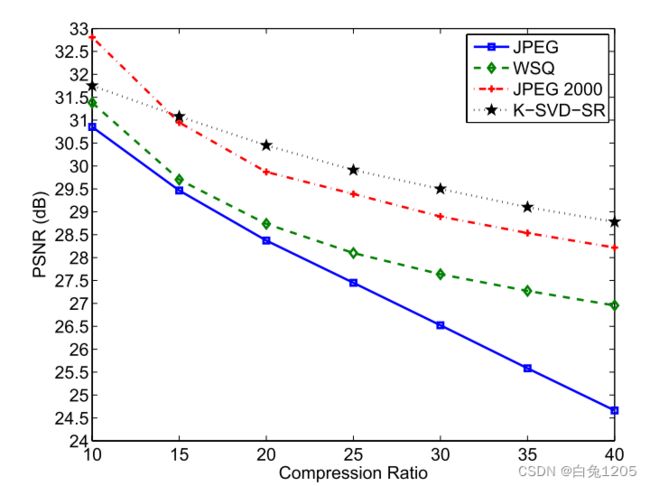 图10所示:提出的算法的平均性能以及JPEG, jpeg2000和WSQ算法,在不同的压缩比上数据库4。
图10所示:提出的算法的平均性能以及JPEG, jpeg2000和WSQ算法,在不同的压缩比上数据库4。
 表5:不同算法在数据库4上得到的PSNR (db)的平均值和方差。对于每个网格,左边是均值,右边是方差
表5:不同算法在数据库4上得到的PSNR (db)的平均值和方差。对于每个网格,左边是均值,右边是方差
DATABASE 4上的结果与DATABASE 3上的结果大致一致。
与JPEG和WSQ相比,本文算法的PSNR和jpeg2000的PSNR始终较高。在10:1的压缩比下,JPEG2000的性能也比我们的好。当压缩比为15:1时,该方法的性能与jpeg2000相当。在较高的压缩比下,我们的算法优于JPEG 2000。从图中可以看出,我们算法的曲线是最平坦的。这意味着随着压缩比的增加,我们算法的PSNR的衰减速率是最慢的。从趋势上看,在较高的压缩比下,我们的算法优于其他算法。
图13显示了一个压缩比为40:1的数据库3的例子。
 图13所示:(a)大小为300 × 300的原始图像,(b) JPEG, (c) JPEG 2000, (d) WSQ, (e)压缩比为40:1的建议方法
图13所示:(a)大小为300 × 300的原始图像,(b) JPEG, (c) JPEG 2000, (d) WSQ, (e)压缩比为40:1的建议方法
3)在数据集5上的实验结果:图11和表5展示JPEG、jpeg2000和WSQ算法的平均性能。
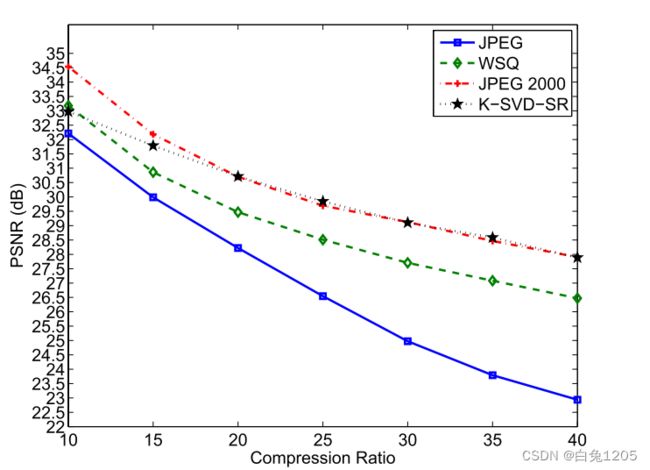 图11所示。提出的算法的平均性能以及JPEG, jpeg2000和WSQ算法,在不同的压缩比上数据库5。
图11所示。提出的算法的平均性能以及JPEG, jpeg2000和WSQ算法,在不同的压缩比上数据库5。
 表5:不同算法在数据库5上得到的PSNR (db)的平均值和方差。对于每个网格,左边是均值,右边是方差
表5:不同算法在数据库5上得到的PSNR (db)的平均值和方差。对于每个网格,左边是均值,右边是方差
我们的方法在这个数据库上的性能比在database 4和database 5上的性能差。与JPEG结果相比,其他三种方法的PSNR均较高。然而,在压缩比10:1,JPEG 2000和WSQ比我们的工作更好。当压缩比为15:1时,该方法的性能低于jpeg2000。在较高的压缩比下,我们的算法具有与jpeg2000相同的结果,并且优于WSQ。本文提出的方法性能较差的原因有二:一是DATABASE 5中指纹图像的背景比较复杂。二是这些指纹图像的质量相对较差。很难很好地描述一个糟糕的时期。图14显示了一个来自DATABASE 5的压缩比为40:1的例子。
 图14所示:(a)大小为328 × 364的原始图像,(b) JPEG, (C) JPEG 2000, (d) WSQ, (e)压缩比为40:1的建议方法
图14所示:(a)大小为328 × 364的原始图像,(b) JPEG, (C) JPEG 2000, (d) WSQ, (e)压缩比为40:1的建议方法
F、设计训练集
从上面的实验,我们可以看到字典是非常重要的。假设字典和补丁的大小分别为M × N和M × N。字典有两个参数,分别是M和n。实际上,M = m×n是一个与补丁大小有关的变量。N为特征集的个数(在前两种构造字典的方法中,N为所选补丁的个数。第三种方式,N为K-SVD方法训练的特征个数)。理论上,特征集应该足够大,使得小块可以稀疏表示,也就是说,N应该足够大。M越大,压缩效率越高。但是,当M增大时,为了获得较好的压缩效果,N也增大。N越大,计算复杂度越高。毕竟,充分性和效率这两个问题是相辅相成的。文中给出了这些参数的估计方法。此外,针对指纹问题,还有其他几个细节需要考虑。
1)训练样本的数量:对于第三种用K-SVD方法训练字典的方法,我们考虑训练样本的数量对PSNR的影响。这里的测试集是DATABASE 2,字典的大小是144 × 4096。从图15可以看出,PSNR越高,训练样本的数量越多。要获得一本好词典,需要大量的训练样本。当训练样本数约为27000时,该算法具有较好的性能。从图中也可以看出,所提方法具有通过增加训练样本数量进行学习的能力。
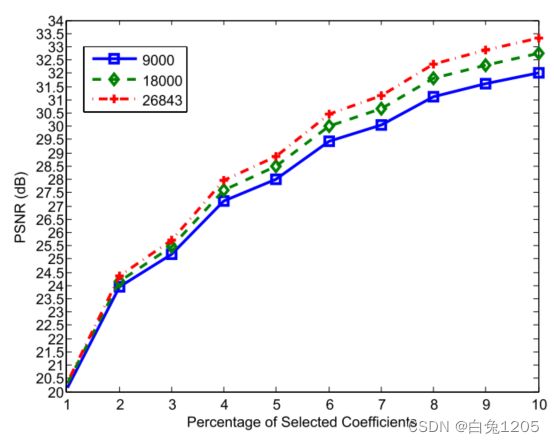 图15所示:训练样本的数量对K-SVD算法的平均性能的影响,对于选择的系数的不同百分比。考虑了9000、18000和26843三个训练样本。
图15所示:训练样本的数量对K-SVD算法的平均性能的影响,对于选择的系数的不同百分比。考虑了9000、18000和26843三个训练样本。
2)训练集的组成部分:一般的图像太复杂,难以处理。指纹图像相对简单。然而,有许多情况需要考虑。在局部特征上,方位、脊频和细节是指纹的主要特征。我们在编词典时应该考虑到这些因素。图16显示了这些补丁。
 图16所示:(a) 64个不同方向的小块,(b) 64个不同脊频的小块,(c) 64个显示指纹细部、边缘等不常见的小块。
图16所示:(a) 64个不同方向的小块,(b) 64个不同脊频的小块,(c) 64个显示指纹细部、边缘等不常见的小块。
3)如何修改字典:正如我们之前提到的,我们的算法可以利用经验信息。换句话说,它有学习的能力。经过一段时间的应用,会有很多补丁不能很好地表现出来。我们可以使用这些新的补丁和原来的补丁来更新字典。假设原字典为D0,原训练集为Y0。不能很好地表示的新补丁集合为Y1。我们将原始训练集和新训练集放在一起,生成一个更大的训练集(称为Y = [Y0, Y1])。我们可以解决以下优化问题来获得新的字典。在更新时,我们将旧字典作为字典的初始矩阵,即D0。
G、鲁棒性
虽然有成功的方法[39]基于Gabor滤波,它不依赖于细节。然而,在大多数自动指纹识别系统(AFIS)中,用于匹配两个指纹图像的主要特征是细节。因此,我们通过比较压缩前和压缩后的细节差异来说明我们的算法的鲁棒性。衡量鲁棒性的重要标准有三个,分别是正确率(AR)、召回率(RR)及其和。
我们在DATABASE 3中测试了鲁棒性。结果如图17所示。
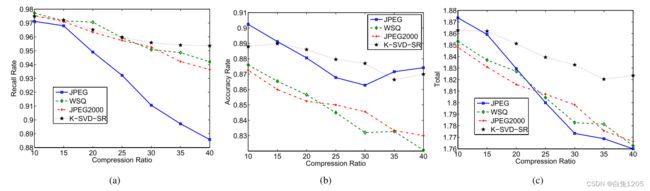 图17:(a)查全率,(b)准确率,(c)不同算法在不同压缩比下查全率和准确率的总和。
图17:(a)查全率,(b)准确率,(c)不同算法在不同压缩比下查全率和准确率的总和。
从图17中我们可以看到,即使在压缩比为40:1的情况下,我们的算法也达到了87%的精度和95%的召回率。从图17可以看出,我们算法的召回率很高。从图17可以看出,JPEG算法和我们算法的准确率始终优于其他算法。同时,从图17可以看出,除了压缩比10:1外,我们算法的Total Rate是最好的。准确率表明我们的算法可以减少虚假的细节点,召回率表明我们的算法可以在压缩和重构过程中稳健地保留大部分的细节点。从以上的实验中,我们发现JPEG算法在PSNR方面的性能很差。但从召回率和准确率来看,该算法具有较好的性能。这表明,仅靠PSNR不足以衡量压缩算法的性能。至少,指纹压缩是这样的。根据不同的目的和不同种类的图像,需要更多的评价指标,如指纹图像的准确率、召回率。
4、结论
介绍了一种新的适用于指纹图像的压缩算法。尽管我们提出的算法简单,但与现有的更复杂的算法相比,它们更具有优势,特别是在高压缩比时。但由于该算法采用逐块处理机制,复杂度较高。
实验表明,该算法的块效应没有JPEG算法严重。我们考虑了三种不同字典对指纹压缩的影响。实验结果表明,用K-SVD算法得到的字典效果最好。用于识别的细节。实验表明,该算法在压缩和重构过程中能够稳健性地保留大部分细节信息。未来的工作应该考虑许多有趣的问题。首先,应该仔细考虑字典的特点和构造方法。其次,训练样本中应包含不同质量(“好”、“坏”、“丑”)的指纹。第三,需要研究求解稀疏表示的优化算法。第四,优化代码,降低方法的复杂度。最后,应该探索基于稀疏表示的指纹图像的其他应用。
稀疏表示是利用字典,将信号表示成少数原子的线性组合的过程。稀疏变送使信号能量只集中于少数原子,对应于非零系数的少量原子揭示了信号的主要特征与内在结构。
稀疏表示采用过完备的函数集代替传统的正交基函数,过完备集定义为字典,其中每个列向量定义为原子。当字典中原子个数K大于信号维数n并且字典中包含n个线性无关的向量能够表示整个信号空间时,字典称为过完备的或者冗余的。稀疏表示算法目标是将信号分解成少数原子的线性组合。