TensorFlow 2.9的零零碎碎(二)-读取MNIST数据集
目录
MNIST是什么?
tf.keras.datasets.mnist
tf.keras.datasets.mnist.load_data()读取的是什么?
load_data()函数的大体原理
将读取的mnist数据集中的数据转为浮点数并归一化
TensorFlow 2.9的零零碎碎(二)-TensorFlow 2.9的零零碎碎(六)都是围绕使用TensorFlow 2.9在MNIST数据集上训练和评价模型来展开。
Python环境3.8。
代码调试都用的PyCharm。
MNIST是什么?
MNIST是手写数字数据集,由6万张训练图片和1万张测试图片构成的,每张图片都是28*28大小(如下图),这些图片是采集的不同的人手写从0到9的数字。

tf.keras.datasets.mnist
tf.keras.datasets.mnist的定义在keras.datasets.mnist模块中。
代码很简单
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0tf.keras.datasets.mnist.load_data()读取的是什么?
我们已经知道了mnist的实现是在keras.datasets.mnist,主要就是load_data()函数,用于读取mnist数据集,load_data()函数的源码如下
@keras_export('keras.datasets.mnist.load_data')
def load_data(path='mnist.npz'):
"""Loads the MNIST dataset.
This is a dataset of 60,000 28x28 grayscale images of the 10 digits,
along with a test set of 10,000 images.
More info can be found at the
[MNIST homepage](http://yann.lecun.com/exdb/mnist/).
Args:
path: path where to cache the dataset locally
(relative to `~/.keras/datasets`).
Returns:
Tuple of NumPy arrays: `(x_train, y_train), (x_test, y_test)`.
**x_train**: uint8 NumPy array of grayscale image data with shapes
`(60000, 28, 28)`, containing the training data. Pixel values range
from 0 to 255.
**y_train**: uint8 NumPy array of digit labels (integers in range 0-9)
with shape `(60000,)` for the training data.
**x_test**: uint8 NumPy array of grayscale image data with shapes
(10000, 28, 28), containing the test data. Pixel values range
from 0 to 255.
**y_test**: uint8 NumPy array of digit labels (integers in range 0-9)
with shape `(10000,)` for the test data.
Example:
```python
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
assert x_train.shape == (60000, 28, 28)
assert x_test.shape == (10000, 28, 28)
assert y_train.shape == (60000,)
assert y_test.shape == (10000,)
```
License:
Yann LeCun and Corinna Cortes hold the copyright of MNIST dataset,
which is a derivative work from original NIST datasets.
MNIST dataset is made available under the terms of the
[Creative Commons Attribution-Share Alike 3.0 license.](
https://creativecommons.org/licenses/by-sa/3.0/)
"""
origin_folder = 'https://storage.googleapis.com/tensorflow/tf-keras-datasets/'
path = get_file(
path,
origin=origin_folder + 'mnist.npz',
file_hash=
'731c5ac602752760c8e48fbffcf8c3b850d9dc2a2aedcf2cc48468fc17b673d1')
with np.load(path, allow_pickle=True) as f: # pylint: disable=unexpected-keyword-arg
x_train, y_train = f['x_train'], f['y_train']
x_test, y_test = f['x_test'], f['y_test']
return (x_train, y_train), (x_test, y_test)TensorFlow和Keras其实在代码注释上做得都非常好,看代码注释就能看出一个函数是什么以及怎么用
load_data()函数的大体原理
mnist.load_data()函数访问上面的网址,下载mnist数据集的文件,保存为mnist.npz,路径在xxx\.keras\datasets\mnist.npz
npy
The .npy format is the standard binary file format in NumPy for persisting a single arbitrary NumPy array on disk. The format stores all of the shape and dtype information necessary to reconstruct the array correctly even on another machine with a different architecture. The format is designed to be as simple as possible while achieving its limited goals.
也就是将numpy生成的数组保存为二进制格式数据。
npz
The .npz format is the standard format for persisting multiple NumPy arrays on disk. A .npz file is a zip file containing multiple .npy files, one for each array.
也就是将多个数组保存到一个文件,且保存为二进制格式。
1个npz中可以有多个npy
用np.load读取这个文件,np就是numpy,这个文件里包含4个数组:
x_train、y_train、x_test、y_test
读取之后将这4个数组返回(x_train, y_train), (x_test, y_test)
所以这也就是为什么我写代码的时候总是要写(x_train, y_train), (x_test, y_test) = mnist.load_data()
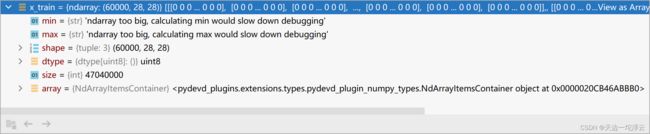
x_train数据一览
y_train数据一览

x_test数据一览

y_test数据一览

将读取的mnist数据集中的数据转为浮点数并归一化
读取的mnist数据集中的数据的取值范围都是0-255

归一化的目的就是使得预处理的数据被限定在一定的范围内(比如[0,1]或者[-1,1]),从而消除奇异样本数据导致的不良影响。归一化的目的就是使得预处理的数据被限定在一定的范围内(比如[0,1]或者[-1,1]),从而消除奇异样本数据的存在会引起训练时间增大,同时也可能导致无法收敛,因此,当存在奇异样本数据时,在进行训练之前需要对预处理数据进行归一化;反之,不存在奇异样本数据时,则可以不进行归一化。奇异样本数据导致的不良影响。
x_train和y_train都是numpy数组,且为整形,直接用“/=”会报错:“numpy.core._exceptions.UFuncTypeError: Cannot cast ufunc 'divide' output from dtype('float64') to dtype('uint8') with casting rule 'same_kind'”
这是Numpy内部机制导致的
x_train /= 255.0
y_train /= 255.0正确写法
x_train = x_train.astype(np.float)
x_train /= 255.0
y_train = y_train.astype(np.float)
y_train /= 255.0或者
x_train, y_train = x_train / 255.0, y_train / 255.0得到的结果如下
