pandas用众数填充缺失值_Python数据分析之pandas学习(三)
有关pandas模块的学习与应用主要介绍以下8个部分:
1、数据结构简介:DataFrame和Series
2、数据索引index
3、利用pandas查询数据
4、利用pandas的DataFrames进行统计分析
5、利用pandas实现SQL操作
6、利用pandas进行缺失值的处理
7、利用pandas实现Excel的数据透视表功能
8、多层索引的使用
我们在Python数据分析之pandas学习(二)中已经介绍到了第五部分的利用pandas实现SQL操作,我们接着往下讲pandas模块中的其他的知识点。
六、缺失值处理
现实生活中的数据是非常杂乱的,其中缺失值也是非常常见的,对于缺失值的存在可能会影响到后期的数据分析或挖掘工作,那么我们该如何处理这些缺失值呢?常用的有三大类方法,即删除法、填补法和插值法。
删除法:当数据中的某个变量大部分值都是缺失值,可以考虑删除改变量;当缺失值是随机分布的,且缺失的数量并不是很多是,也可以删除这些缺失的观测。
替补法:对于连续型变量,如果变量的分布近似或就是正态分布的话,可以用均值替代那些缺失值;如果变量是有偏的,可以使用中位数来代替那些缺失值;对于离散型变量,我们一般用众数去替换那些存在缺失的观测。
插补法:插补法是基于蒙特卡洛模拟法,结合线性模型、广义线性模型、决策树等方法计算出来的预测值替换缺失值。
我们这里就介绍简单的删除法和替补法:

这是一组含有缺失值的序列,我们可以结合sum函数和isnull函数来检测数据中含有多少缺失值:
1.In [130]: sum(pd.isnull(s))
2.Out[130]: 9
直接删除缺失值

默认情况下,dropna会删除任何含有缺失值的行,我们再构造一个数据框试试:

返回结果表明,数据中只要含有缺失值NaN,该数据行就会被删除,如果使用参数how=’all’,则表明只删除所有行为缺失值的观测。

使用一个常量来填补缺失值,可以使用fillna函数实现简单的填补工作:
1)用0填补所有缺失值

2)采用前项填充或后向填充

3)使用常量填充不同的列

4)用均值或中位数填充各自的列
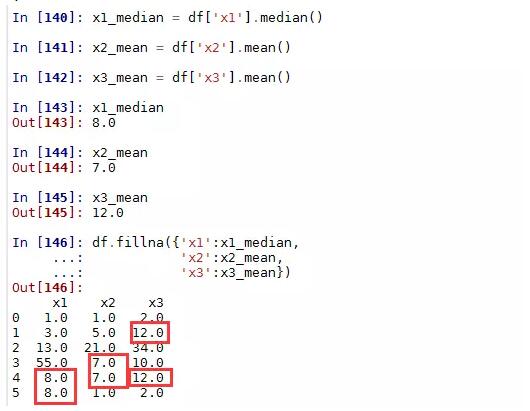
很显然,在使用填充法时,相对于常数填充或前项、后项填充,使用各列的众数、均值或中位数填充要更加合理一点,这也是工作中常用的一个快捷手段。
七、数据透视表
在Excel中有一个非常强大的功能就是数据透视表,通过托拉拽的方式可以迅速的查看数据的聚合情况,这里的聚合可以是计数、求和、均值、标准差等。
pandas为我们提供了非常强大的函数pivot_table(),该函数就是实现数据透视表功能的。对于上面所说的一些聚合函数,可以通过参数aggfunc设定。我们先看看这个函数的语法和参数吧:
1.pivot_table(data,values=None,
2.index=None,
3.columns=None,
4.aggfunc='mean',
5.fill_value=None,
6.margins=False,
7.dropna=True,
8.margins_name='All')
9.data:需要进行数据透视表操作的数据框
10.values:指定需要聚合的字段
11.index:指定某些原始变量作为行索引
12.columns:指定哪些离散的分组变量
13.aggfunc:指定相应的聚合函数
14.fill_value:使用一个常数替代缺失值,默认不替换
15.margins:是否进行行或列的汇总,默认不汇总
16.dropna:默认所有观测为缺失的列
17.margins_name:默认行汇总或列汇总的名称为'All'
我们仍然以student表为例,来认识一下数据透视表pivot_table函数的用法:
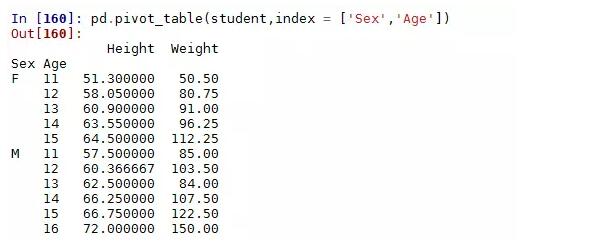
对一个分组变量(Sex),一个数值变量(Height)作统计汇总

对一个分组变量(Sex),两个数值变量(Height,Weight)作统计汇总

对两个分组变量(Sex,Age),两个数值变量(Height,Weight)作统计汇总
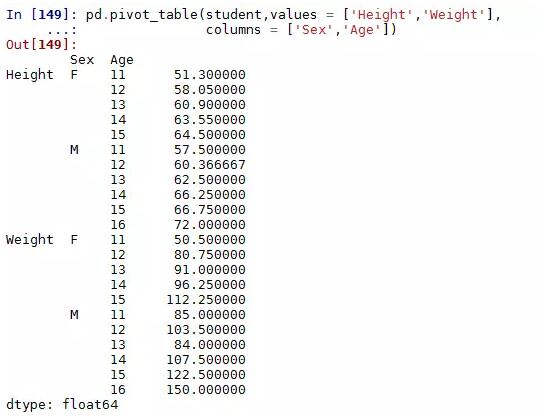
很显然这样的结果并不像Excel中预期的那样,该如何变成列联表的形式的?很简单,只需将结果进行非堆叠操作(unstack)即可:
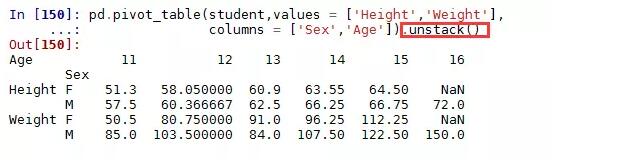
看,这样的结果是不是比上面那种看起来更舒服一点?
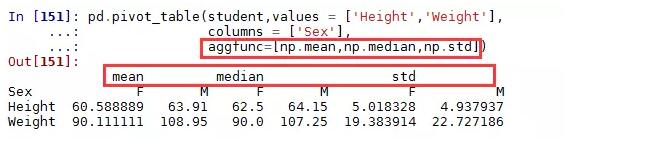
使用多个聚合函数
八、多层索引的使用
最后我们再来讲讲pandas中的一个重要功能,那就是多层索引。在序列中它可以实现在一个轴上拥有多个索引,就类似于Excel中常见的这种形式:
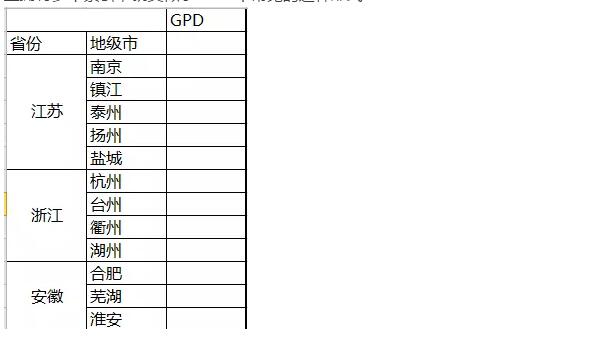
对于这样的数据格式有什么好处呢?pandas可以帮我们实现用低维度形式处理高维数数据,这里举个例子也许你就能明白了:
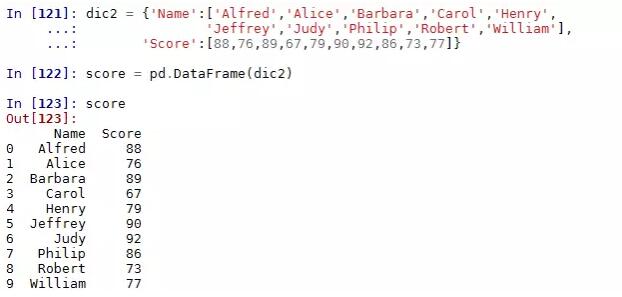
对于这种多层次索引的序列,取数据就显得非常简单了:

对于这种多层次索引的序列,我们还可以非常方便的将其转换为数据框的形式:

以上针对的是序列的多层次索引,数据框也同样有多层次的索引,而且每条轴上都可以有这样的索引,就类似于Excel中常见的这种形式:

我们不妨构造一个类似的高维数据框:
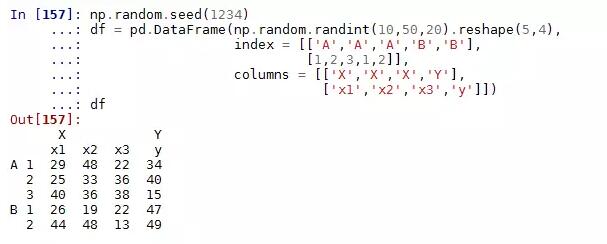
同样,数据框中的多层索引也可以非常便捷的取出大块数据:

在数据框中使用多层索引,可以将整个数据集控制在二维表结构中,这对于数据重塑和基于分组的操作(如数据透视表的生成)比较有帮助。
就拿student二维数据框为例,我们构造一个多层索引数据集:
讲到这里,我们关于pandas模块的学习基本完成,其实在掌握了pandas这8个主要的应用方法就可以灵活的解决很多工作中的数据处理、统计分析等任务。有关更多的pandas介绍,可参考pandas官方文档:http://pandas.pydata.org/pandas-docs/version/0.17.0/whatsnew.html。
强烈推荐《Python数据分析》和《利用Python进行数据分析》两本书,书中详细讲解了如何使用numpy、pandas、scipy、matplotlib等模块进行数据分析,目前我也正在使用这两本参考书,感兴趣的朋友可以一起学习,共同进步。学习任何一门计算机语言都需要你不断的思考和敲击键盘,每天进步一点点,你会感谢一年前努力的自己!
标签:
本站文章除注明转载外,均为本站原创或翻译。欢迎任何形式的转载,但请务必注明出处、不得修改原文相关链接,尊重他人劳动成果
 0
0
好文不易,鼓励一下吧!