ROS图像的Deeplab v3+实时语义分割(ROS+Pytorch)
目录
- 写在前面
- 测试环境
- 主要思路
- 正式开始
-
- 代码获取
- 代码编译
- 代码使用
- 结果展示
写在前面
做机器人的同学们应该都知道,ROS是最常用的系统。一般搭载在机器人上的传感器也通过ROS话题消息机制进行发布,从而可以被其他结点所用。
最近要做一个机器人图像的实时语义分割任务,但是没有找到相关的教程。
其中的难点在于一般的语义分割网络都是离线的,对某个文件夹的图像进行分割并保存结果,而且一般需要用到深度学习环境(如Pytorch)。如何为其配置ROS接口是个难题。
这一篇文章就是旨在实现实时的ROS图像的实时语义分割,用的是Deeplab v3 plus在cityspaces数据集上训练好的网络。
测试环境
- Ubuntu18.04
- ROS1
- Anaconda3+带有pytorch和其他网络所需库的一个环境
主要思路
其实思路很简单,就是写一个ros消息的订阅程序,每次接收到图像都进行网络分割得到结果。
主要难点还是如何融合pytorch和ros环境。
正式开始
代码获取
我已经在官方代码的基础上进行了调整,可以适用于ROS的图像实时语义分割,为了简单期间,代码我直接放在网盘中,可以直接下载。
链接: https://pan.baidu.com/s/1FGAQr3VXW5_Fip0X2vvYug
密码: 2wij
大家也可以直接取github看使用教程,其实是一样的
github地址
代码编译
将压缩包直接解压到主目录即可,得到的文件架构已经是一个工作空间的架构。这里的Img_seg_ros是主要的文件,vision_opencv是适用于python3的opencv包,后续需要用到。
-- DeepLabV3Plus_ws
-- src
-- Img_seg_ros
-- ...
-- vision_opencv
-- ...
进入DeepLabV3Plus_ws目录,并激活带有pytorch等相关库的深度学习环境,后续所有操作均不退出该环境。(如我的环境名是panoptic-deeplab)
dyn@dyn-Lenovo-Legion-R7000P2021H:~$ cd DeepLabV3Plus_ws/
dyn@dyn-Lenovo-Legion-R7000P2021H:~/DeepLabV3Plus_ws$ source activate panoptic-deeplab
(panoptic-deeplab) dyn@dyn-Lenovo-Legion-R7000P2021H:~/DeepLabV3Plus_ws$
我们使用catkin build的方式编译,首先在终端初始化,输入
catkin init
接着,配置环境要求,使用python3编译,在终端输入
catkin config -DPYTHON_EXECUTABLE=/home/user_name/anaconda3/envs/your_env/bin/python -DPYTHON_INCLUDE_DIR=/home/user_name/anaconda3/envs/your_env/include/python3.7m -DPYTHON_LIBRARY=/home/user_name/anaconda3/envs/your_env/lib/libpython3.7m.so -DCMAKE_BUILD_TYPE=Release -DSETUPTOOLS_DEB_LAYOUT=OFF
注意,其中dyn是我ubuntu的用户名,python3.6也是我这个环境中所安装的python版本,大家使用时注意修改。
接着就可以尝试进行编译了,在终端输入
catkin build
编译一般没有什么问题。
代码使用
在使用之前需要修改一些代码,现在这个代码写的不是很人性化,修改所有内容位于src/Img_seg_ros目录下面的predict.py文件。
- 第29行
sys.path.append('/home/dyn/DeepLabV3Plus_ws/devel/lib/python3.6/site-packages')
这里我为了让cv_bridge的版本寻找的是我们包中自带的这个,所以使用了绝对路径,大家需要把dyn和python版本改成自己的。
- 第50行
ckpt = "/home/dyn/DeepLabV3Plus_ws/src/Img_seg_ros/best_deeplabv3plus_mobilenet_cityscapes_os16.pth"
这里的.pth文件就是模型的参数文件,加载的时候我也是使用的绝对路径,大家注意修改。
- 第101行
img_top = "/miivii_gmsl_ros/camera0/image_raw"
img_top是需要订阅的图像消息的名称,改成自己的即可。
修改完之后,就可以开始正常使用了。
在终端启动程序。
source devel/setup.bash
roslaunch img_seg run.launch
终端会显示每个包寻找的来源,我的如下:
*****************************************
[test libraries]:
- cv2.__file__ = /home/dyn/anaconda3/envs/panoptic-deeplab/lib/python3.6/site-packages/cv2/__init__.py
- sensor_msgs.__file__ = /opt/ros/melodic/lib/python2.7/dist-packages/sensor_msgs/__init__.py
- cv_bridge.__file__ = /home/dyn/DeepLabV3Plus_ws/devel/lib/python3.6/site-packages/cv_bridge/__init__.py
*****************************************
[finish test]
只要包找对了位置,就没什么太大问题了。
在另一个终端终端rosbag play录制好的数据,就可以实现实时的语义分割。
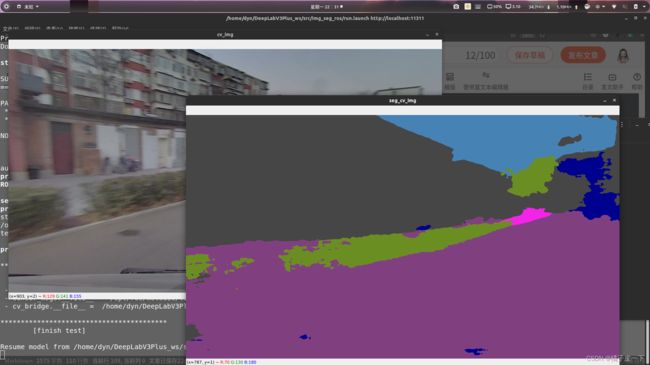
结果展示
原图像和结果都会通过opencv的窗口展示出来,如果有需要,可以将分割后的图像重新发送回ros。