【目标检测】25、Sparse R-CNN: End-to-End Object Detection with Learnable Proposals
文章目录
-
- 一、背景
- 二、动机
- 三、方法
-
- 3.1 Backbone
- 3.2 Learnable proposal box
- 3.3 Learnable proposal feature
- 3.4 Dynamic instance interactive head
- 3.5 Set prediction loss
- 四、效果
- 五、代码
出处:CVPR2021

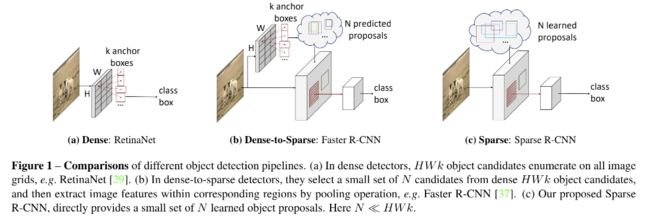

一、背景
目前的目标检测方法很大程度上依赖于密集的候选框,如在特征图 H × W H \times W H×W 上的每个 grid 预设 k k k 个 anchors,且取得了较好的效果。
但这些方法有以下问题:
- 这些方法通常会生成冗余且近似重复的结果,所以必须使用 NMS
- many-to-one label assignment 的方法对规则很敏感
- 最终的性能和 anchor box 的尺寸、宽高比、个数、生成规则等有很大的关系
二、动机
作者认为 sparse property 来源于两个方面:sparse box & sparse features
- sparse box:候选框很少
- 每个box中的特征不需要和全图中的所有目标进行交互
所以作者提出看 Sparse R-CNN,如图1©所示,目标候选框是
本文中,作者使用了学习得到的 N N N 个 anchor,来进行后续的分类的回归。把成百上千的手工设计的 anchor 缩减为了学习得到的大约 100 个 proposals。避免了手工设计和 many-to-one 的 label 分配,且最后不需要 NMS 。
三、方法
Sparse R-CNN 的中心思想:使用少的 proposal boxes(100)来代替 RPN 生成的大量 candidate,如图3所示。
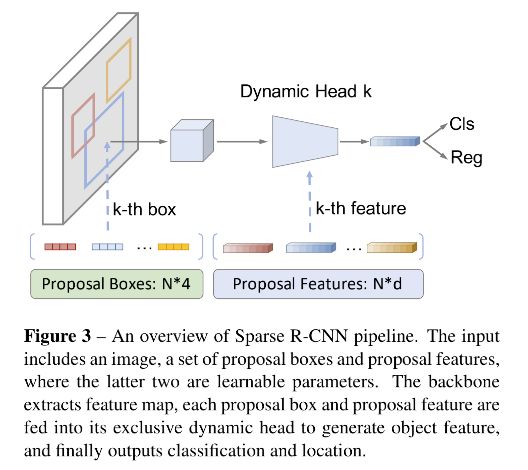
- backbone:
- dynamic instance interactive head
- cls head
- reg head
3.1 Backbone
FPN based ResNet(using p2→p5)
channel:256
其余设置:和 Faster RCNN 基本相同
3.2 Learnable proposal box
维度: N × 4 N \times 4 N×4
初始化: ranging from 0 to 1
优化:在训练的过程中使用反向传播来优化
从概念上来讲,Sparse R-CNN 学习到的统计特征,是训练集中最可能出现目标的位置。RPN中,是和当前图像有很强关联 proposal,并且提供的是一个粗糙的图像位置。
所以,Sparse R-CNN 可以被认为是目标检测器的扩展,从 完全 dense→dense-to-sparse→ 完全 sparse。
3.3 Learnable proposal feature
由于上面 4-d 的proposal box是对目标的简单直接的描述,提供了粗糙的位置,但丢失了如目标的姿态和形状等信息。
此处作者提出了另外一个概念——proposal feature(N x d),它是一个高维(例如256)潜在向量,预计用于编码丰富的实例特征。proposal feature 的数量和 box一样。
3.4 Dynamic instance interactive head
给定 N 个proposal boxes:
- Sparse R-CNN 首先使用 RoIAlign 来对每个box抽取特征
- 然后每个 box 的特征会使用 prediction head 来生成最终的预测
dynamic interactive head:

- 对于 N 个proposal box,使用 N 个 proposal feature
- 每个 RoI feature 将会和对应的 proposal feature进行交互,过滤掉无用的bin,输出最终的目标特征
- 模块的简单形式:1x1 conv + 1x1 conv + relu
3.5 Set prediction loss
Sparse R-CNN 在固定尺寸的分类和回归预测上使用 set prediction loss。
![]()
- 分类:focal loss
- L1:中心点 loss
- giou:宽和高 loss
- 权重:2:5:2
四、效果
作者提出了两种版本的 Sparse R-CNN:
- 第一种:使用 100 个学习的 proposal boxes,不使用随机 crop 的数据增强
- 第二种*:使用 300 个学习的 proposal boxes,使用随机 crop 的数据增强
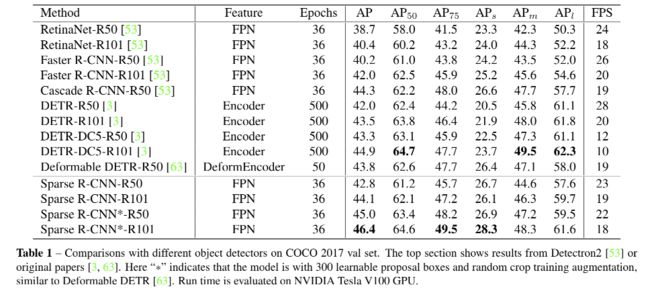
Sparse R-CNN:
- 速度是 DETR 的10x(图2)
- AP: 45.0 AP vs. 43.8 AP
- 速度:22FPS vs. 19FPS
- 迭代周期:36 epochs vs. 50 epochs
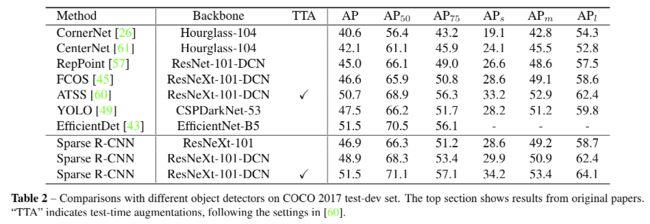
Proposal boxes 的性能:
- 学习到的 proposal boxes 通常会覆盖整个图片,来保证recall
- 每个 stage 会逐步 refine 每个 box 的位置,并且去除掉重复的
- 图5同事也体现了box对目标稀疏场景和目标复杂场景的鲁棒性,对稀疏场景,前几个stage就会把大量重复的框丢掉,对复杂场景,会经过多个stage后实现对每个目标的精准检测
五、代码
代码路径:https://github.com/PeizeSun/SparseR-CNN
# 训练
python projects/SparseRCNN/train_net.py --num-gpus 8 \
--config-file projects/SparseRCNN/configs/sparsercnn.res50.100pro.3x.yaml
# 评测
python projects/SparseRCNN/train_net.py --num-gpus 8 \
--config-file projects/SparseRCNN/configs/sparsercnn.res50.100pro.3x.yaml \
--eval-only MODEL.WEIGHTS path/to/model.pth
# 可视化
python demo/demo.py\
--config-file projects/SparseRCNN/configs/sparsercnn.res50.100pro.3x.yaml \
--input path/to/images --output path/to/save_images --confidence-threshold 0.4 \
--opts MODEL.WEIGHTS path/to/model.pth
Head 结构:
(init_proposal_features): Embedding(100, 256)
(init_proposal_boxes): Embedding(100, 4)
(head): DynamicHead(
(box_pooler): ROIPooler(
(level_poolers): ModuleList(
(0): ROIAlign(output_size=(7, 7), spatial_scale=0.25, sampling_ratio=2, aligned=True)
(1): ROIAlign(output_size=(7, 7), spatial_scale=0.125, sampling_ratio=2, aligned=True)
(2): ROIAlign(output_size=(7, 7), spatial_scale=0.0625, sampling_ratio=2, aligned=True)
(3): ROIAlign(output_size=(7, 7), spatial_scale=0.03125, sampling_ratio=2, aligned=True)
)
)
(head_series): ModuleList(
(0): RCNNHead(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(inst_interact): DynamicConv(
(dynamic_layer): Linear(in_features=256, out_features=32768, bias=True)
(norm1): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(activation): ReLU(inplace=True)
(out_layer): Linear(in_features=12544, out_features=256, bias=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.0, inplace=False)
(dropout2): Dropout(p=0.0, inplace=False)
(dropout3): Dropout(p=0.0, inplace=False)
(cls_module): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=False)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): ReLU(inplace=True)
)
(reg_module): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=False)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): ReLU(inplace=True)
(3): Linear(in_features=256, out_features=256, bias=False)
(4): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=256, out_features=256, bias=False)
(7): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(8): ReLU(inplace=True)
)
(class_logits): Linear(in_features=256, out_features=2, bias=True)
(bboxes_delta): Linear(in_features=256, out_features=4, bias=True)
)
(1): RCNNHead(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(inst_interact): DynamicConv(
(dynamic_layer): Linear(in_features=256, out_features=32768, bias=True)
(norm1): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(activation): ReLU(inplace=True)
(out_layer): Linear(in_features=12544, out_features=256, bias=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.0, inplace=False)
(dropout2): Dropout(p=0.0, inplace=False)
(dropout3): Dropout(p=0.0, inplace=False)
(cls_module): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=False)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): ReLU(inplace=True)
)
(reg_module): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=False)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): ReLU(inplace=True)
(3): Linear(in_features=256, out_features=256, bias=False)
(4): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=256, out_features=256, bias=False)
(7): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(8): ReLU(inplace=True)
)
(class_logits): Linear(in_features=256, out_features=2, bias=True)
(bboxes_delta): Linear(in_features=256, out_features=4, bias=True)
)
(2): RCNNHead(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(inst_interact): DynamicConv(
(dynamic_layer): Linear(in_features=256, out_features=32768, bias=True)
(norm1): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(activation): ReLU(inplace=True)
(out_layer): Linear(in_features=12544, out_features=256, bias=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.0, inplace=False)
(dropout2): Dropout(p=0.0, inplace=False)
(dropout3): Dropout(p=0.0, inplace=False)
(cls_module): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=False)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): ReLU(inplace=True)
)
(reg_module): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=False)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): ReLU(inplace=True)
(3): Linear(in_features=256, out_features=256, bias=False)
(4): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=256, out_features=256, bias=False)
(7): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(8): ReLU(inplace=True)
)
(class_logits): Linear(in_features=256, out_features=2, bias=True)
(bboxes_delta): Linear(in_features=256, out_features=4, bias=True)
)
(3): RCNNHead(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(inst_interact): DynamicConv(
(dynamic_layer): Linear(in_features=256, out_features=32768, bias=True)
(norm1): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(activation): ReLU(inplace=True)
(out_layer): Linear(in_features=12544, out_features=256, bias=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.0, inplace=False)
(dropout2): Dropout(p=0.0, inplace=False)
(dropout3): Dropout(p=0.0, inplace=False)
(cls_module): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=False)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): ReLU(inplace=True)
)
(reg_module): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=False)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): ReLU(inplace=True)
(3): Linear(in_features=256, out_features=256, bias=False)
(4): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=256, out_features=256, bias=False)
(7): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(8): ReLU(inplace=True)
)
(class_logits): Linear(in_features=256, out_features=2, bias=True)
(bboxes_delta): Linear(in_features=256, out_features=4, bias=True)
)
(4): RCNNHead(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(inst_interact): DynamicConv(
(dynamic_layer): Linear(in_features=256, out_features=32768, bias=True)
(norm1): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(activation): ReLU(inplace=True)
(out_layer): Linear(in_features=12544, out_features=256, bias=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.0, inplace=False)
(dropout2): Dropout(p=0.0, inplace=False)
(dropout3): Dropout(p=0.0, inplace=False)
(cls_module): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=False)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): ReLU(inplace=True)
)
(reg_module): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=False)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): ReLU(inplace=True)
(3): Linear(in_features=256, out_features=256, bias=False)
(4): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=256, out_features=256, bias=False)
(7): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(8): ReLU(inplace=True)
)
(class_logits): Linear(in_features=256, out_features=2, bias=True)
(bboxes_delta): Linear(in_features=256, out_features=4, bias=True)
)
(5): RCNNHead(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=256, out_features=256, bias=True)
)
(inst_interact): DynamicConv(
(dynamic_layer): Linear(in_features=256, out_features=32768, bias=True)
(norm1): LayerNorm((64,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(activation): ReLU(inplace=True)
(out_layer): Linear(in_features=12544, out_features=256, bias=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
)
(linear1): Linear(in_features=256, out_features=2048, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
(linear2): Linear(in_features=2048, out_features=256, bias=True)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm3): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.0, inplace=False)
(dropout2): Dropout(p=0.0, inplace=False)
(dropout3): Dropout(p=0.0, inplace=False)
(cls_module): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=False)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): ReLU(inplace=True)
)
(reg_module): ModuleList(
(0): Linear(in_features=256, out_features=256, bias=False)
(1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(2): ReLU(inplace=True)
(3): Linear(in_features=256, out_features=256, bias=False)
(4): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=256, out_features=256, bias=False)
(7): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(8): ReLU(inplace=True)
)
(class_logits): Linear(in_features=256, out_features=80, bias=True)
(bboxes_delta): Linear(in_features=256, out_features=4, bias=True)
)
)
)
(criterion): SetCriterion(
(matcher): HungarianMatcher()
)
)
cfg.MODEL.SparseRCNN:
CfgNode({'NUM_CLASSES': 80, 'NUM_PROPOSALS': 100, 'NHEADS': 8, 'DROPOUT': 0.0, 'DIM_FEEDFORWARD': 2048, 'ACTIVATION': 'relu',
'HIDDEN_DIM': 256, 'NUM_CLS': 1, 'NUM_REG': 3, 'NUM_HEADS': 6, 'NUM_DYNAMIC': 2, 'DIM_DYNAMIC': 64, 'CLASS_WEIGHT': 2.0,
'GIOU_WEIGHT': 2.0, 'L1_WEIGHT': 5.0, 'DEEP_SUPERVISION': True, 'NO_OBJECT_WEIGHT': 0.1, 'USE_FOCAL': True,
'ALPHA': 0.25, 'GAMMA': 2.0, 'PRIOR_PROB': 0.01})
projects/SparseRCNN/sparsercnn/head.py
# line 173
features:
(Pdb) p features[0].shape
torch.Size([1, 256, 152, 232])
(Pdb) p features[1].shape
torch.Size([1, 256, 76, 116])
(Pdb) p features[2].shape
torch.Size([1, 256, 38, 58])
(Pdb) p features[3].shape
torch.Size([1, 256, 19, 29])
bboxes.shape
torch.size([1, 100, 4])
pooler:
ROIPooler(
(level_poolers): ModuleList(
(0): ROIAlign(output_size=(7, 7), spatial_scale=0.25, sampling_ratio=2, aligned=True)
(1): ROIAlign(output_size=(7, 7), spatial_scale=0.125, sampling_ratio=2, aligned=True)
(2): ROIAlign(output_size=(7, 7), spatial_scale=0.0625, sampling_ratio=2, aligned=True)
(3): ROIAlign(output_size=(7, 7), spatial_scale=0.03125, sampling_ratio=2, aligned=True)
)
)
pro_features.shape
torch.Size([1, 100, 256])
roi_features:
100,256,7,7
->
49, 100, 256
weight_dict:
{'loss_ce': 2.0, 'loss_bbox': 5.0, 'loss_giou': 2.0, 'loss_ce_0': 2.0, 'loss_bbox_0': 5.0, 'loss_giou_0': 2.0,
'loss_ce_1': 2.0, 'loss_bbox_1': 5.0, 'loss_giou_1': 2.0, 'loss_ce_2': 2.0, 'loss_bbox_2': 5.0, 'loss_giou_2': 2.0,
'loss_ce_3': 2.0, 'loss_bbox_3': 5.0, 'loss_giou_3': 2.0, 'loss_ce_4': 2.0, 'loss_bbox_4': 5.0, 'loss_giou_4': 2.0}
真值获取:
detector.py
if self.training:
gt_instances = [x["instances"].to(self.device) for x in batched_inputs]
targets = self.prepare_targets(gt_instances)
if self.deep_supervision:
output['aux_outputs'] = [{'pred_logits': a, 'pred_boxes': b}
for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
loss_dict = self.criterion(output, targets)
weight_dict = self.criterion.weight_dict
for k in loss_dict.keys():
if k in weight_dict:
loss_dict[k] *= weight_dict[k]
return loss_dict