TinyPerson数据集json文件改写为xml文件
TinyPerson(NWPU VHR-10或其他同理)数据集文件改写为VOC类型的xml文件
代码转python实现
创作不易,点个赞吧
文章目录
- TinyPerson(NWPU VHR-10或其他同理)数据集文件改写为VOC类型的xml文件
-
- XML文件读写
-
- 相关模块
- 读取xml文件
- 析xml文件为dict
- 写入xml文件
- 修改xml文件
-
- 修改已有节点的值
- 添加节点
- TinyPerson数据集实战
-
- TinyPerson数据集annotation示例:
- 获取信息
- python实现
- 效果展示
- 参考文献
为了完成这个目标,需要以下两个事情:
1规范写出xml文件
2根据TinyPerson的Annotation格式,改写为xml文件
(#以上问题是我在试图跑出TinyPerson数据集遇到并解决的,希望更多用此数据集来测试小目标检测的朋友,可以更方便地跑出此数据集#)
XML文件读写
相关模块
from lxml import etree
from lxml.etree import Element,SubElement,tostring
读取xml文件
path_xml='your_xml_path'
with open(path_xml,'r') as file:
xml_str=file.read()
#<class 'str'>
xml=etree.fromstring(xml_str)
#<class 'lxml.etree._Element'>
# 下一步只需把xml文件析成dict
析xml文件为dict
def parse_xml_to_dict(xml):
if len(xml) == 0: # 遍历到底层,直接返回tag对应的信息
return {xml.tag: xml.text}
result = {}
for child in xml:
#print(child.text)
child_result = parse_xml_to_dict(child) # 递归遍历标签信息
if child.tag != 'object':
result[child.tag] = child_result[child.tag]
else:
if child.tag not in result: # 因为object可能有多个,所以需要放入列表里
result[child.tag] = []
result[child.tag].append(child_result[child.tag])
return {xml.tag: result}
写入xml文件
node_root=Element('annotation')#Element用来创建一个lxml.etree._Element类
node_folder=SubElement(node_root,'fold')#创建子类
node_folder.text='your xml file path'
node_object=SubElement(node_root,'object')
node_weight=SubElement(node_object,'weight')
node_wieght.text=256
node_height=SubElement(node_object,'height')
node_height.text=256
#当我们保存为xml文件时,只需要保存node_root即可
xml_byte=tostring(node_root)#虽然函数名为tostring但是得到的格式实际是bytes,可用type查看
with open('path you want to save','wb') as f:#此处需用wb,代表写入bytes,如果是'r'会报错
f.write(xml_byte)
# 至此完成了xml的保存
还有一种写法:
import xml.dom.minidom
dom=minidom.Document()
annotation=dom.createElement('annotation')#创建根节点
dom.appendChild(annotation)#添加根节点
size=dom.createElement('size')
annotation.appendChild('size')
width=dom.createElement('width')
size.appendChild(width)
width_text=dom.createTextNode('256')
width.appendChild(width_text)
height=dom.createElement('height')
size.appendChild(height)
height_text=dom.createTextNode('256')
height.appendChild(height_text)
depth=dom.createElement('depth')
size.appendChild(depth)
depth_text=dom.createTextNode('3')
depth.appendChild(depth_text)
#至此便创建了一个dom文件,以下将其保存为xml并展示效果
with open(path,'w') as f:
dom.writexml(f)#这么保存格式不好看,推荐:
dom.writexml(f,indent='',addindent='\t',newl='\n',encoding='UTF-8')
效果如图:

修改xml文件
通常我们写了一个xml文件,可能需要后续修改
修改已有节点的值
以下代码修改了xml文件中height,width中的值为height,width
import xml.dom.minidom
dom=xml.dom.minidom.parse(path)
root=dom.documentElement
heights=root.getElementsByTagName('height')[0]
heights.firstChild.data=height
#print(height)
widths=root.getElementsByTagName('width')[0]
widths.firstChild.data=width
#print(width)
with open(path, 'w') as f:
dom.writexml(f)
添加节点
dom=xml.dom.minidom.parse(path)
root=dom.documentElement
node1=dom.createElement('node1')
root.appendChild(node1)#如此便在root下添加了一个子节点
name_text=dom.createTextNode('this is node1 of root')
node1.appendChild(name_text)#如此便在node1中添加了一个文本节点
TinyPerson数据集实战
本节的目的:读取TinyPerson数据集annotation,用以上方法,写入xml文件
TinyPerson数据集annotation示例:
{“type”: “instance”, “annotations”: [{“segmentation”: [[1081.124389319407, 17.45930926910859, 1267.431666947439, 17.45930926910859, 1267.431666947439, 67.73270164492683, 1081.124389319407, 67.73270164492683]], “bbox”: [1081.124389319407, 17.45930926910859, 186.3072776280319, 50.27339237581825], “category_id”: 1, “area”: 9366.298870664552, “iscrowd”: 0, “image_id”: 0, “id”: 0, “ignore”: true, “uncertain”: false, “logo”: true, “in_dense_image”: false},
后面就是下一个{“segmentaion”: #######}
分析以下这个json文件中的内容:
segmentation代表一个实例
bbox即为GT的x,y,width,height
image_id代表第m张图片
id代表第n个物体(累计,不会因为图片切到下一个而归0)
如何去寻找image_id对应的image位置
这需要下一段json文件
“images”: [{“file_name”: “labeled_images/bb_V0032_I0001640.jpg”, “height”: 720, “width”: 1280, “id”: 0}, {“file_name”: “labeled_images/bb_V0014_I0002600.jpg”, “height”: 1080, “width”: 1920, “id”: 1},
从这段json文件,可以分析出来此处的id代表的上文的image_id,OK现在可以着手了
获取信息
写出一个VOC格式的xml文件需要以下信息:
dealpath储存xml文件位置
filename储存xml文件名称
num每个图片里的object数量
xmins,ymins,xmaxs,ymaxs, [4,n]
names [n]代表每个object的名称
height,width为图片的高宽
需要特别注意,以上必须是字符串形式(包括xmins
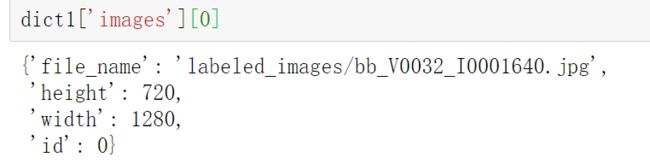
以此图为例,file_name,height,width,dealpath都能唯一确定
但是对于每一个dict1[‘annotations’][0]只能得到一个object
于是我们可以写通过‘images’,先把xml文件写出来,之后根据每次读到的object去修改即可(nice idea)
python实现
import os
import json
from lxml import etree
from lxml.etree import Element,SubElement,tostring
from xml.dom import minidom
json_file=open('D:/CODE/data/tiny_set/tiny_set/annotations/tiny_set_train.json','r')
path1='D:/CODE/data/tiny_set/tiny_set/annotation'#path1代表生成annotations的位置
path2='D:/CODE/data/tiny_set/tiny_set/train/train'
dict1=json.load(json_file)#读取字典
#更改labeled_image文件夹中的图片名称(我个人习惯)
for i in range(746): # 746 = len(dict1['images'])
file1=os.path.join(path2,dict1['images'][i]['file_name'])
#file1=os.path.join(path2,'labeled_images',str(dict1['images'][i]['id'])+'.jpg')
file2=os.path.join(path2,'labeled_images',str(dict1['images'][i]['id']).rjust(3,'0')+'.jpg')
os.rename(file1,file2)
#在path1目录下创建xml文件
for i in range(746):
annotation=Element('annotation')#Element用来创建一个lxml.etree._Element类
folder=SubElement(annotation,'folder')#创建子类
folder.text='tiny_set'
filename=SubElement(annotation,'filename')
filename.text=str(dict1['images'][i]['id'])+'.jpg'
size=SubElement(annotation,'size')
width=SubElement(size,'width')
width.text=str(dict1['images'][i]['width'])
height=SubElement(size,'height')
height.text=str(dict1['images'][i]['height'])
depth=SubElement(size,'depth')
depth.text='3'
xml_byte=tostring(annotation)#虽然函数名为tostring但是得到的格式实际是bytes,可用type查看
file_path=os.path.join(path1,str(dict1['images'][i]['id']).rjust(3,'0')+'.xml')
with open(file_path,'wb') as f:#此处需用wb,代表写入bytes,如果是'r'会报错
f.write(xml_byte)
#根据每个object信息去修改xml文件
for i in range(len(dict1['annotations'])):
img_id=str(dict1['annotations'][i]['image_id']).rjust(3,'0')
xml_path=os.path.join(path1,img_id+'.xml')
dom=minidom.parse(xml_path)
annotation=dom.documentElement
object_node=dom.createElement('object')
annotation.appendChild(object_node)
#为了省事,创建节点的代码写在一起
name=dom.createElement('name')
pose=dom.createElement('pose')
truncated=dom.createElement('truncated')
difficult=dom.createElement('difficule')
bndbox=dom.createElement('bndbox')
xmin=dom.createElement('xmin')
ymin=dom.createElement('ymin')
xmax=dom.createElement('xmax')
ymax=dom.createElement('ymax')
object_node.appendChild(name)
object_node.appendChild(pose)
object_node.appendChild(truncated)
object_node.appendChild(difficult)
object_node.appendChild(bndbox)
bndbox.appendChild(xmin)
bndbox.appendChild(ymin)
bndbox.appendChild(xmax)
bndbox.appendChild(ymax)
obj_name=dict1['annotations'][i]['category_id']
if obj_name==1:
obj_name='sea_person'
else:
obj_name='earth_person'
text=dom.createTextNode(obj_name)
name.appendChild(text)
text=dom.createTextNode('unspecified')
pose.appendChild(text)
text=dom.createTextNode('0')
truncated.appendChild(text)
obj_dif=dict1['annotations'][i]['ignore']
if obj_dif:
obj_dif='1'
else:
obj_dif='0'
text=dom.createTextNode(obj_dif)
difficult.appendChild(text)
#x,y,weight,height
bbox=dict1['annotations'][i]['bbox']
half_w=bbox[2]
half_h=bbox[3]
text=dom.createTextNode(str(bbox[0]))
xmin.appendChild(text)
text=dom.createTextNode(str(bbox[1]))
ymin.appendChild(text)
text=dom.createTextNode(str(bbox[0]+half_w))
xmax.appendChild(text)
text=dom.createTextNode(str(bbox[1]+half_h))
ymax.appendChild(text)
#这几句代码的是为了打出来的格式好看。可以用一句dom.writexml(f)代替with:里面所有内容
with open(xml_path, 'w') as f:
if i==25287 :
dom.writexml(f,indent='',addindent='\t',newl='\n',encoding='UTF-8')
elif dict1['annotations'][i+1]['image_id'] != dict1['annotations'][i]['image_id'] :
dom.writexml(f,indent='',addindent='\t',newl='\n',encoding='UTF-8')
else:
dom.writexml(f)
效果展示
xml文件展示:

标注效果展示图:

参考文献
https://blog.csdn.net/summer2day/article/details/83064727?utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-4.control&dist_request_id=1619533822770_16111&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromMachineLearnPai2%7Edefault-4.control
https://www.cnblogs.com/wcwnina/p/7222180.html
https://blog.csdn.net/mingyang_wang/article/details/82912636
点赞是一件有意义的事情,不仅是对作者,也对读者。
如果时光可以重来,我一定会给那些指引过我的文章点赞