决策树分类与回归总结
目录
- 概念
- 决策树
-
- 决策算法
-
- ID3算法
- C4.5算法
- CART算法
- 决策树的优缺点
- 决策树的剪枝策略
- 关于建模过程中的一点补充
- 参考
- 关于作者
概念
决策树就是一个类似于流程图的树形结构,树内部的每一个节点代表的是对一个特征的测试,属的分支代表特征的每一个测试结果,树的叶子节点代表一种分类结果。
决策树模型既可以做分类也可以做回归。
分类就是树模型的每个叶子节点代表一个类别;
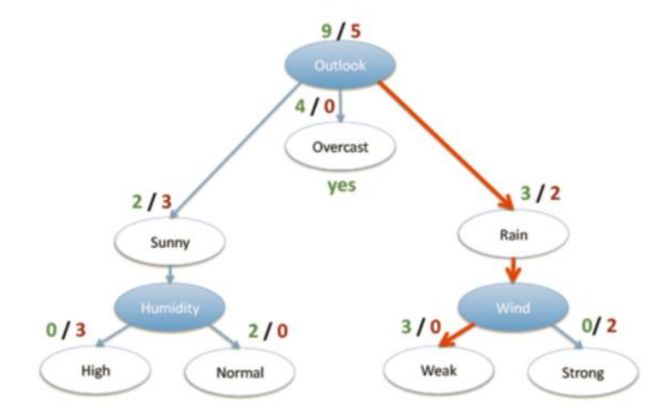
回归就是根据特征向量来决定对应的输出值。回归树就是将特征空间划分成若干单元,每一个划分单元有一个特定的输出。对于测试数据,只要按照特征将其归到某个单元,便得到对应的输出值。

决策树
决策树的构建过程:
- 特征选择:特征选择是指从训练数据中众多的特征中选择一个特征 作为当前节点的分裂标准,如何选择特征有着很多不同量化评估标准,从而衍生出不同的决策算法
- 决策树生成:根据选择的特征评估标准,从上至下递归的生成子节点,直到数据集不可分则停止决策树停止生长。在决策树中,所有的特征均为离散值,如果某个特征是连续得,需要先离散化。
- 剪纸:决策树容易过拟合,一般来需要剪枝,缩小树结构规模,缓解过拟合。剪纸技术有预剪枝和后剪枝两种。
决策算法
ID3算法
算法:在决策树各个节点上应用信息增益准则选择特征,每一次都选择是的信息增益最大的特征进行分裂,递归的构建决策树。
信息衡量标准–熵:表示随机变量不确定性的度量
H ( x ) = − ∑ p i ∗ l o g ( p i ) H(x) = -\sum p_i*log(p_i) H(x)=−∑pi∗log(pi)
熵形容的是物体内部得混乱程度。我们希望分类完之后,结果得不确定越小越好.信息增益就是表示特征X使类Y的不确定减少得程度。

按照如此,计算其他特征得信息增益。信息增益最大的特征最为分类依据。
不足:
- 信息增益作为划分训练数据集的特征,如此,选择取值比较多的特征往往会具有较大的信息增益,所以ID3偏向于选择取值较多得特征。
- 只能处理分类型变量
- 不能处理缺失值
C4.5算法
C4.5算法对ID3算法的不足进行了改进。用信息增益率来选择特征。信息增益率等于信息增益除以该属性本身得熵。

悲观剪枝:ID3构造决策树的时候,容易产生过拟合。在C4.5中,会在决策树构造之后采用悲观剪枝,以提升决策树的泛化能力。
悲观剪枝时候剪纸技术中的一种,通过递归估算每个内部结点的分类错误率,比较剪纸前后这个几点的分类错误率来决定是否对其进行剪枝。
离散化处理连续属性:连续值划分的阈值,根据信息增益比来划分,将连续值离散化
处理缺失值:
如果样本总量n,特征a缺失m个数据,去除缺失值后,计算 g a i n 0 gain_0 gain0。最终, g a i n = n − m n g a i n 0 gain = \frac{n-m}{n}gain_0 gain=nn−mgain0。在计算gain_ratio。
总结:
- 由于C4.5需要对数据集进行多次扫描,算法效率较低
- 可以处理连续变量和缺失值
- 在树的构造过程中可以进行剪纸,避免过拟合
CART算法
既可以做分类,也可以做回归。只能形成二叉树。
分类树
CART用Gini指数来决定如何分裂,表示总体内包含的类别杂乱程度。越乱Gini指数越大。
gini的计算
g i n i = 1 − ∑ ( p i ) 2 gini = 1 - \sum(p_i)^2 gini=1−∑(pi)2

损失函数:同一层所有分支假设函数得基尼系数得平均
连续特征离散化
将特征值排序,选取基尼系数最小的点作为分类点,一分为二。当前节点为连续属性时,该属性后面还可以参与子节点的产生选择过程。CART分类树采用的是不停的二分,形成二叉树。
回归树
回归树采用最小方差作为分裂规则。
对于任意划分特征A,对应的任意划分点s两边划分成得数据集D1和D2,求出是D1和D2各自集合得均方差最小,同时D1和D2得均方差之和最小所对应的特征和特征值划分点。

其中,c1为D1数据集得样本输出均值,c2为D2数据集得样本输出均值
输出结果:最终叶子得均值或者中位数来预测输出结果
剪枝策略:后剪枝
决策树的优缺点
优点
- 简单直观
- 基本不需要预处理,不需要提前归一化,处理缺失值
- 使用决策树预测的代价是 O l o g 2 m Olog_2m Olog2m,m是样本数
- 及可以处理离散值也可以处理连续值
- 可以处理多维度输出的分类问题
- 相比于神经网络之类的黑盒分类模型,决策树在逻辑上可以得到很好的解释
- 可以交叉验证的剪枝来选择模型,从而提高泛化能力
- 对于异常点的容错能力好,健壮性高
缺点
- 决策树算法非常容易过拟合,导致泛化能力不强。可以设置节点最少样本数量和限制决策树深度来改进
- 决策树会因为样本发生一点点改动(特别是节点末梢),导致树结构剧烈改变。这个可以通过集成学习之类的方法解决
- 寻找最优的决策树是一个NP难问题,我们一般是通过启发方式,容易陷入局部最优。可以通过集成学习之类的方法来改善
- 有些比较复杂的关系,决策树很难学习。比如异或。一般这种关系换成神经网络分类方法可以解决。
- 如果某些特征的样本比例过大,生成决策树容易偏向于这些特征。这个可以通过调节样本权重来改善。
决策树的剪枝策略
- 预剪枝
在决策树生成过程中,对每个结点在华分钱先进行估计,若当前结点的划分不能带来决策树泛化性能提升,则停止划分即结束树的构建并将当前节点标记为叶节点。
- 限制树的深度
- 最小节点样本数
- 最大叶子节点数
- 限制信息增益的大小
- 后剪枝
先从训练集生成一棵完整的决策树,然后自底向上地对叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化为性能提升,则将该子树替换为叶结点。泛化性能的提升可以使用交叉验证数据来检查修剪的效果,通过使用交叉验证数据,测试扩展节点是否会带来改进。如果显示会带来改进,那么我们可以继续扩展该节点。但是,如果精度降低,则不应该扩展,节点应该转换为叶节点。
后剪枝比预剪枝保留了更多分支。一般情况下,后剪枝决策树的欠拟合风险很小,泛化性能能往往优于预剪枝决策树。但后剪枝过程在生成完全决策树之后才能进行,并且要自底向上对数中的所有非叶子节点逐一计算,因此训练时间开销比未剪纸开销大。
关于建模过程中的一点补充
1. 决策树为什么容易过拟合?
决策树的生成过程中,通过不断分支,将样本实例划分到合适的单元,当样本中存在噪声,即可能是特征值观测误差或者标签值观测误差,使在分支归节点的时候产生矛盾,这时决策树选择继续生成新的分支,来产生更加“完美”的叶子节点,这便是由于噪音数据带来的误生成的分支,使得训练变得更加优越,而泛化能力下降
2.决策树的深浅和对应的条件概率模型有何关系
每条路径后的叶子节点对应着特征空间的一个划分区域,而此区域内估计各类的概率,便是此路径下的条件概率,当决策树模型较浅时,对应的路径上的节点数也较少,从而概率路径上的特征也较少,这表示,通过较少的特征估计了所有特征组合里的众多可能的条件概率,因此,较浅的决策树对应着舍弃某些特征组合下的泛条件概率模型(参数复杂度低)
3.信息增益倾向于选择取值较多的特征,为何?
信息增益在计算的过程中,存在对某个特征的某取值时的数据集合内的各类概率估计,当该特征的取值较多时,分到每个值小面的样本数也会少一些,而这使得概率的估计的稳定性变差(或者说离大数定律的要求越远),使得估计出的概率容易出现非均匀的情况,从而造成条件熵下降,即信息增益变大的倾向,但不是所有情况下都是这样的,当数据集非常大,或者说那些取值多的特征并没有多到很夸张时,信息增益并没有多大偏向性。
4.信息增益比如何消除信息增益的倾向性?
通过将信息增益值与特征的内部熵值比较,消除因为特征取值较多带来的概率估计偏差的影响。其本质是在信息增益的基础之上乘上一个惩罚参数。特征个数较多时,惩罚参数较小;特征个数较少时,惩罚参数较大。这带来一个新的问题是,倾向于选择特征取值少的。
5.CART中的回归树在生成过程中,特征会重复出现吗?树生成的停止条件是啥?
特征会复用,停止的条件是基尼指数低于阈值,或者样本数太少没有分支的意义,再或者是没有特征可供选择。补充:ID3和C4.5的特征不会复用,且是多分叉的树。
6.决策树出现过拟合的原因
- 决策树构建过程中,对决策树生长没有进行合理的限制
- 在建模过程中使用了较多的输出变量
- 样本中有一些噪声数据,噪声数据对决策树的构建干扰很多
参考
https://blog.csdn.net/qq_20412595/article/details/82048795
https://www.jianshu.com/p/444b19104e4e
关于作者
