SQL优化-优化器
1.优化器
定义:优化器(optimizer)是oracle数据库内置的一个核心子系统。优化器的目的是按照一定的判断原则来得到它认为的目标SQL在当前的情形下的最高效的执行路径,也就是为了得到目标SQL的最佳执行计划。依据所选择执行计划时所用的判断原则,oracle数据库里的优化器又分为RBO(基于原则的优化器)和CBO(基于成本的优化器,SQL的成本根据统计信息算出)两种。
ORACLE数据库SQL语句的执行过程:
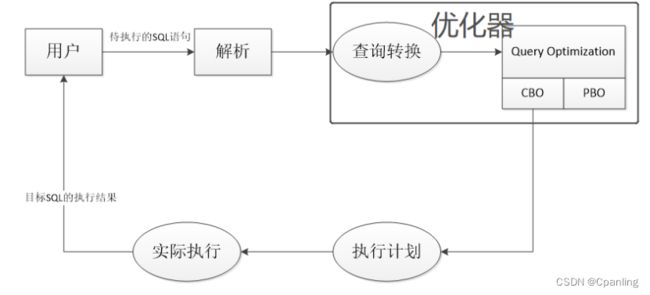
分类:Oracle数据库中的优化器分为RBO和CBO
RBO:基于规则的优化器
RBO是一种适合于OLTP类型SQL语句的优化器。相对于CBO而言,RBO有着先天的缺陷,一旦SQL语句的执行计划出现问题,将很难调整。RBO最大的缺点是以oracle内置代码的规则作为判断标准,而并没有考虑到实际目标表的数据量以及数据分布情况。
CBO:基于成本的优化器
CBO优化器根据SQL语句生成一组可能被使用的执行计划,估算出每个执行计划的代价,并调用计划生成器(Plan Generator)生成执行计划,比较执行计划的代价,最终选择选择一个代价最小的执行计划。查询优化器由查询转换器(Query Transform)、代价估算器(Estimator)和计划生成器(Plan Generator)组成。
oracle在未引入系统统计信息之前,CBO所计算的成本值实际全是基于IO计算的。
比较:CBO优于RBO是因为RBO是一种呆板、过时的优化器,它只认规则,对数据不敏感。毕竟规则是死的,数据是变化的,这样生成的执行计划往往是不可靠的,不是最优的。
2.CBO优化器的基本概念
2.1 集的势(cardinality)
Cardinality是CBO特有的概念,指集合所包含的记录数,即结果集行数。Cardinality实际上表示对目标SQL某个具体执行步骤的执行结果所包含的记录数的估算,当然,如果针对整个目标SQL,那么此时的cardinality就表示对该SQL最终执行结果所包含的记录数的估算。Cardinality和成本值得估算息息相关,因为oracle得到的制定结果集所需要消耗的IO资源可以近似的看成随着结果集所包含的记录数递增而递增。所以,SQL编写的一个原则就是“尽早的过滤更多的数据”。
2.2 可选择率(Selectivity)
Selectivity也是CBO特有的概念,它是指“施加指定谓语条件后返回的结果集的记录数占未施加任何谓语条件的原始结果集的记录数的比率”,取值范围为0~1,其值越小,代表可选择性越好。Selectivity也可成本值得估算息息相关,可选择率越大,意味着所返回的结果集的cardinality越大,所以估算的成本就越大。实际上CBO就是利用selectivity来计算对应结果集的cardinality的,即:
Computed cardinality=original*selectivity
Cardinility和selectivity的值会直接影响CBO对于相关执行步骤成本的估算,进而影响CBO对于目标SQL的执行计划的选择。
可用以下公式老表示:
Selectivity=施加指定谓语条件后返回的结果集的记录数/未施加任何谓语条件的原始结果集的记录数
Selectivity = 1/num_distinct
2.3 可传递性
可传递性也是CBO的特有属性,它是查询转换中所做的第一件事情,其含义是CBO会对目标SQL做等价改写,进而提供更多的执行路径给目标CBO,增加得到最佳执行计划的可能性。RBO不会对目标SQL做等价改写。Oracle里可传递性分为以下3种情况:
1)简单谓语传递
比如原目标SQL中的谓语条件是“t1.c1=t2.c1 and t1.c1=10”,则CBO可能会给谓语条件额外加上“t2.c1=10”。
2)连接谓语传递
比如原目标SQL中的谓语条件是“t1.c1=t2.c1 and t2.c1=t3.c1”,则CBO可能会给谓语条件额外加上“t1.c1=t3.c1”。
3)外链接谓语传递
比如原目标SQL中的谓语条件是“t1.c1=t2.c1(+) and t1.c1=10”,则CBO可能会给谓语条件额外加上“t2.c1(+)=10”。
2.4 CBO的局限性
1)CBO会默认目标SQL语句where条件中出现的各个列之间出现是独立的,没有任何关联。并且CBO会根据这个前提条件来计算selectivity和cardinality,进而估算成本并选择执行计划。
2)CBO会假设所有的目标SQL都是独立运行的,并且互不干扰,但实际情况却不完全是这样。
3)CBO在解析多表关联的目标SQL时,可能会漏选正确的执行计划。
3.优化器基础知识
3.1 优化器的模式
优化器模式用于决定oracle在解析目标SQL时所选择的优化器类型,以及选择使用CBO时计算成本的侧重点。在oracle数据库中,优化器模式由参数OPTIMIZER_MODE的值决定,通常OPTIMIZER_MODE的值为RULE,CHOOSE,FIRST_ROWS_n(N=1、10、100、1000),FIRST_ROWS或ALL_ROWS。OPTIMIZER_MODE的值得各个含义如下:
1)RULE:RULE表示优化器使用RBO来解析目标SQL,此时目标SQL所涉及的各个对象的统计信息对于RBO来说将毫无意义。
2)CHOOSE:CHOOSE是oracle 9i中OPTIMIZER_MODE的默认值,他表示oracle在解析目标SQL时到底使用CBO还是RBO取决于目标SQL所涉及对象是否有统计信息。
3)FIRST_ROWS_n(N=1、10、100、1000)
4)FIRST_ROWS:FIRST_ROWS是一个在oracle 9i中就过时的一个参数,他表示oracle在解析目标SQL时会联合使用CBO和RBO。在大部分情况下,oracle还是会选用CBO作为解析目标SQL,此时oracle的侧重点是以最快的相应速度返回前n行。在一些特俗情况下,oracle会选用RBO来解析目标SQL而不考虑成本。
5)ALL_ROWS:ALL_ROWS是oracle 10g及以后oracle的版本中OPTIMIZER_MODE的默认值,它表示oracle会使用CBO来解析目标SQL,此时CBO计算目标SQL的各个执行路径的成本的侧重点是最佳吞吐量。当OPTIMIZER_MODE为FIRST_ROWS时,CBO计算成本侧重于最快响应时间;当OPTIMIZER_MODE为ALL_ROWS时,CBO计算成本侧重于最佳吞吐量。
3.2 结果集(row source)
结果集是指包含指定执行结果的集合。对于优化器而言,结果集对应SQL执行计划的执行步骤。执行计划的各个步骤的输出结果集和输入结果集可以通过执行计划分析出。
3.3 访问数据的方法
优化器访问数据的方法有3种,一种是直接访问表;一种是访问索引,直接从索引中取值;另一种是先访问索引,再回表。
3.3.1 访问表的方法
访问表的方法2种:全表扫描;rowid扫描。
(1)全表扫描
全表扫面会从表所占用的第一个extent的第一个块开始扫描,一直到该表的最高水位线为止,这个范围的所有的数据块,oracle都会读到。
(2)rowid访问
Rowid访问是指oracle在访问目标表的数据时,直接通过数据所在的rowid去定位并访问这些数据。Oracle中rowid访问有两层含义:一是根据用户SQL输入的rowid值直接去读取数据记录;另一种是先去访问相关索引,然后根据访问索引所返回的rowid回表去读取具体的记录数。
对于oracle数据库中的堆表,可以通过oracle内置的rowid伪列得到对应的rowid值,然后我们可以通过dbms_rowid包中的相关方法(dbms_rowid.rowid_relative_fno:文件号;dbms_rowid.rowid_block_number:数据块号;dbms_rowid.rowid_row_number:数据块中行号)通过上述取得的rowid值取得数据行的实际物理位置。例:
SQL> select empno,ename,rowid, dbms_rowid.rowid_relative_fno(rowid)
||'_'||dbms_rowid.rowid_block_number(rowid)||'_'||dbms_rowid.rowid_row_number(rowid) localtion
from emp;
EMPNO ENAME ROWID LOCALTION
---------- ------------------------------ -------------------------------------------------- ----------------------------
########## SMITH AAAMfMAAEAAAAAgAAA 4_32_0
..............
########## MILLER AAAMfMAAEAAAAAgAAN 4_32_13
14 rows selected.
3.3.2 访问索引的方法
使用B-TREE索引的优势有以下几点:
a、所有的叶子快都在同一层,即所有的叶子块距离根节点的距离是相同的。
b、Oracle保证所有的B-tree索引都是自平衡的,即不可能出现不同的索引叶子块不处于同一层的情况。
c、通过B-tree索引访问数据不会因为表数据量的增加效率明显降低,这也是走索引与全表扫描最大的区别。
(1)索引唯一性扫描:
索引唯一性扫描(index unique scan)是针对唯一性索引(unique index)的扫描。它仅仅适用于where条件是等值查询的目标SQL。
(2)索引范围扫描:
索引范围扫描(index range scan)适用于所有的B-tree索引,当扫描的对象是唯一性索引时,此时目标SQL的where条件一定是范围条件,当扫描的对象是非唯一性索引时,此时目标SQL的where条件没有限制。
(3)索引全扫描:
索引全扫描(index full scan)适用于所有类型的B-tree索引(唯一性索引和非唯一性索引),所谓索引全扫描是指要扫描索引的所有叶子块的所有行。
(4)索引快速扫描:
索引快速扫描(index fast full scan)适用于所有类型的B-tree索引(唯一性索引和非唯一性索引),索引快速扫描要扫描索引的所有叶子块的所有行。索引快速扫描与索引全扫描有以下区别:
#索引快速扫描仅仅适用于CBO。
#索引快速扫描可以使用多块读,同时也可以并行执行。
#索引快速扫描的结果不一定是有序的。
(5)索引跳跃式扫描
索引跳跃式扫描(index skip scan)适用于所有复合类型的B-tree索引(包括唯一性索引与非唯一性索引)。
3.3.3 表连接
通常情况下,我们可以人为Oracle的表连接分为内连接和外连接两种连接方式。
3.3.3.1 表连接类型
(a)内连接(inner join)
内连接是指表连接的连接结果只包含那些完全满足连接条件的记录。对于SQL而言,只要其where条件中没有定义那些外连接关键字(如left outer join、right outer join、full outer join)外的所有连接类型定义为内连接。
(b)外连接(outer join)
外连接是对内连接的一种扩展,它是指表连接的结果除了包括那些满足条件的连接结果外还包含驱动表中不满足连接条件的结果。标准SQL的外连接分为左连接(left outer join)、右连接(righr outer join)、全连接(full outer join)三种。全连接可以近似看成是先做左连接union再做右连接,这里所说的近似是因为oracle实际的处理并不是这样做的,因为union要对结果集进行排序,而全连接并不需要排序。
3.3.3.2 表连接方法
优化器在解析含有表连接的目标SQL时,当根据目标SQL的SQL文本决定了表的连接类型后,接下来还要决定表的连接方法。Oracle中两表的连接方法有“排序合并”,“嵌套循环”,“哈希连接”,“笛卡尔连接”四种。
(a)排序合并连接(sort merge join)
排序合并连接是一种两表做表连接时用排序操作(sort)和合并操作(merge)来得到表连接结果的方法。
排序合并连接的适用场景总结入下:
b.1)通常情况下,排序合并连接的执行效率不如哈希连接,但是前者使用范围广,因为hash连接只适用于等值连接,而排序合并还适用于其他连接(比如<、>、<=、>=)。
b.2)通常情况下,排序合并不适合OLTP类型连接,本质是排序对于OLTP类型来说成本是昂贵的。但是,如果能避免排序,也是可以适合于OLTP系统的。
(b)嵌套循环连接(nested loops join)
嵌套循环连接是两个表在做连接时采用两层嵌套循环(外层循环和内层循环)的方式来得到表连接结果的方法。
嵌套循环连接的适用场景总结入下:
b.1)如果驱动表所对应的驱动结果集的记录较少,同时被驱动表的连接列上又存在唯一性索引(或者被驱动表的连接列上存在选择性较好的非唯一性索引),那么此时使用嵌套循环的执行效率会非常高。如果驱动表所对应的驱动结果集数量较多,那么即使被驱动表的连接列上存在唯一性索引,那么执行效率也不会很高。
b.2)只要驱动结果集的记录较少,那么就具备了做嵌套循环的前提条件,而驱动表所对应的驱动结果集是在对驱动表应用了目标SQL之后所得到的结果集,所以大表也会可以作为驱动表的。
b.3)嵌套循环可以实现快速响应。
嵌套循环在访问被驱动表时,如果被驱动表有索引,将会采用单块读的方式访问索引,同时,如果返回结果集列不在索引中取得,嵌套循环连接也要采用单块读的方式回表。
(c)hash连接(hash join)
Hash连接是指两表在做连接时主要依靠哈希算法来取得结果集的方法
hash连接的适用场景总结入下:
b.1)哈希连接不一定需要排序,大部分情况下。
b.2)哈希连接的驱动表所对应的选择列可选择性应尽可能好,因为这个可选择性会影响到hash bucket的记录数,而hash bucket的记录数又会直接影响从该hash backet中查找匹配记录数的效率。
b.3)哈希连接只适用于CBO,同时哈希连接也只适用于等值连接。
b.4)哈希连接适合于小表和大表做表连接且连接结果集记录数较多的情形,特别是在小表的连接列可选择性特别好的情况下,这时hash连接的执行时间近似于对大表的执行时间。
b.5)当两表做hash连接时,如果在施加了目标SQL指定的谓语条件后所得到的数量较小的那个结果集所对应的hash table能够完全被容纳在内存中(pga),此时hash连接执行效率会非常高。
(d)笛卡尔连接(cross join)
笛卡尔连接又称笛卡尔积(cartesian product),它是一种两表在做连接时没有任何连接条件的表连接方法。
笛卡尔连接总结如下:
b.1)笛卡尔连接出现一般都是目标SQL中漏写了连接条件,所以笛卡尔连接一般都是不好的,除非刻意这样做(比如有时利用笛卡尔积来减少对目标SQL中大表的全表扫描次数)。
b.2)有时候笛卡尔连接的出现时因为目标SQL中使用了ordered hint,同时该SQL中文本委会相邻的两个表又没有直接的连接条件。
b.3)有时候笛卡尔连接出现时因为统计信息不准。