一文速览医学多模态进展
每天给你送来NLP技术干货!
© 作者|杨锦霞
机构|中国人民大学高瓴人工智能学院
来自 | RUC AI Box
引言:目前,自然图像-文本的多模态预训练模型已经在各种各样的下游任务上取得了非常好的效果,但是由于域之间的差异很难直接迁移到医学领域。同时,获取有标注的医学图像领域的数据集通常需要大量的专业知识和较高的成本,所以从对应的放射学报告中得到有效监督从而提高性能成为一种可能。本文主要介绍医学的多模态模型的进展,这些模型方法在下游的分类、分割、检索、图像生成等任务上均取得了性能的提升。
点击这里进群—>加入NLP交流群
Contrastive Learning of Medical Visual Representations from Paired Images and Text
http://arxiv.org/abs/2010.00747
这篇文章提出了ConVIRT框架,核心思想其实就是多模态的对比学习,是CLIP之前的工作,CLIP文中也有说受到ConVIRT的启发,其使用其实的是ConVIRT的简化版本。ConVIRT的整体架构如下:
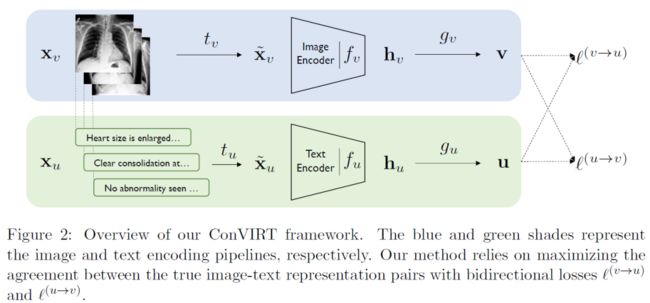
主要流程比较直观:一张图片先做随机变换得到不同的视图,然后进入Image Encoder,最后接一个非线性变化 得到512维的特征表示;对与该图片配对的放射学报告,首先进行随机采样得到其中的某句话,然后进入TextEncoder,最后通过 得到512维的特征表示;最后分别对图片和文本计算infoNCE loss。
GLoRIA: A Multimodal Global-Local Representation Learning Framework for Label-efficient Medical Image Recognition【ICCV2021】
https://ieeexplore.ieee.org/document/9710099/
本文主要从全局和局部进行医学图像的表示学习,提出GLoRIA模型,主要使用注意机制,通过匹配放射学报告中的单词和图像子区域来学习图像的全局-局部表示。其中创建上下文感知的局部图像表示是通过学习基于特定单词的重要图像子区域的注意力权重。如下图中基于单词“effusion”(积液)得到的图像区域积液的权重就比较大。

下图是进行全局和局部学习的方法图。给定一对医学图像和报告,首先使用图像编码器和文本编码器分别提取图像和文本特征。

全局图像-文本表示是通过全局对比损失进行学习的。为了学习局部表征,首先基于图像子区域特征和词级特征计算相似性矩阵,以生成注意力加权图像表示(Attention weighted image representation)。首先计算文本和图像特征的所有组合之间的点积相似性:

上式得到的 表示的是 个单词和 个图像子区域的相似性矩阵, 表示的就是第 个单词和第 个图像子区域之间的相似性。之后通过下面的softmax得到注意力权重 :
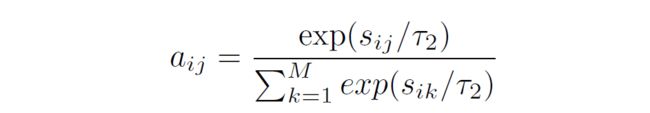
对于报告中的每个单词,我们根据其与所有图像子区域的相似性计算注意力加权图像表示 :
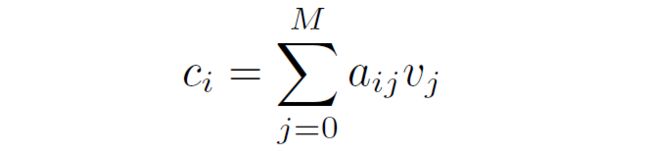
之后通过局部的对比损失来实现这一目标:使用函数 计算单词 与其相应的注意力加权图像特征 之间的相似性。

在给定词表示的情况下,Local contrastive loss的目标是使注意加权图像区域表示的后验概率最大化:
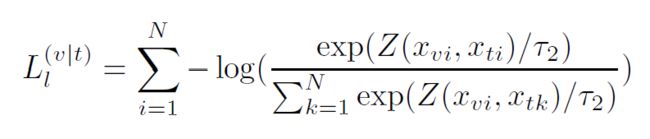
本文主要在图像分类、检索和分割上进行性能评估。其中分类和检索也是结合全局和局部图像文本相似性去实现的。具体来说:通过图像和文本表示提取特征后,基于全局图像和文本表示计算全局相似度;利用基于词的注意加权图像表示和对应的词表示计算局部相似度。通过全局相似度和局部相似度的平均得到最终的图像文本相似度。

但对于分类来说,其没有具体的文本表示,GLoRIA的做法是预生成合理的文本,以描述分类类别中每种疾病子类型、严重程度和位置。通过随机组合子类型、严重性和位置的可能单词生成文本提示来作为每个分类类的文本。
MedCLIP: Contrastive Learning from Unpaired Medical Images and Text【EMNLP 2022】
http://arxiv.org/abs/2210.10163
这篇文章提出了MedCLIP模型,出发点一方面是医学图像文本数据集比互联网上的一般图像文本数据集要少几个数量级,另一方面是以前的方法会遇到许多假阴性,即来自不同患者的图像和报告可能具有相同的语义,但被错误地视为负样本。所以MedCLIP通过将图片文本对进行解耦然后进行对比学习,通过引入外部医学知识而减少假阴性。
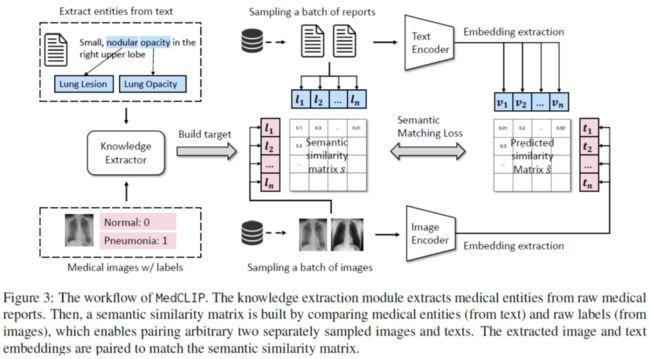
假设有 个成对的图像文本样本、 个标记的图像和 个医学句子。以前的方法只能使用 对样本,但MedCLIP将 个图像文本对分别解耦为 个图像和 个句子。最终能够通过遍历所有可能的组合来获得 图像文本对,所以这样就可以得到 倍的监督信号。
为了完成额外的监督,MedCLIP利用外部医学知识来构建知识驱动的语义相似性。这里MedCLIP使用了外部工具MetaMap,MetaMap是可以从原始句子中提取统一医学语言系统(UMLS)中定义的实体。遵循之前工作的做法,主要关注14种主要实体类型。同样,对于带有诊断标签的图像,也是利用MetaMap将原始类映射到UMLS概念,从而与文本中的实体对齐,例如,“Normal”映射到“No Findings”。接下来就可以从提取的图像和文本实体中构建multi-hot向量,分别为 和 。因此,通过这种方式统一了图像和文本的语义。对于任何图像和文本,MedCLIP就可以通过比较相应的 和 来衡量它们的语义相似性。
MedCLIP通过构建的语义标签 和 来连接图像和文本,首先可以得到soft targets:

表示的就是医学语义的相似性。对图片和文本分别进行softmax:

另外我们也可以通过直接将图像和文本特征计算余弦相似性得到logit,同样进行softmax处理:
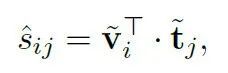
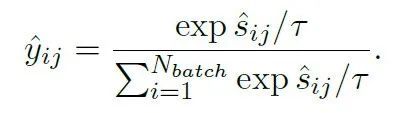
因此,Semantic Matching Loss是logits和soft targets之间的交叉熵:

Multi-Granularity Cross-modal Alignment for Generalized Medical Visual Representation Learning【NIPS 2022】
http://arxiv.org/abs/2210.06044
这篇文章提出MGCA框架,通过多粒度跨模态对齐学习通用医学视觉表示。如下图所示,医学图像和放射学报告会在不同层级自然而然表现出多粒度语义对应关系:疾病层级、实例层级和病理区域层级。
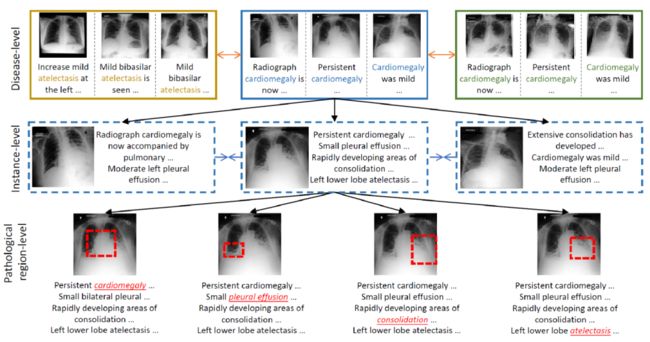
图像和文本首先分别经过图像和文本编码器,得到一系列token表示,然后通过下面三个模块实现三个粒度的对应:

Instance-wise Image-Text Alignment (ITA):进行实例级别的对齐,即图像文本的对比损失。
Cross-attention-based Token-wise Alignment (CTA):基于交叉注意力机制的token级别的对齐。这个模块的出发点对应到前面的病理区域级别,用CTA模块来显式匹配和对齐局部的医学图像和放射学报告。思路是进行token级别的对齐,使用交叉注意计算生成的视觉和文本token之间的一个匹配。形式上,对于第 个图像文本对中的第 个视觉token ,我们让 去和对应的文本中 的所有token 计算其对应的跨模态文本嵌入 ,看作得到了和图片token相似的文本信息。

之后采用local image-to-text alignment 损失来将图片token 接近其交叉模态文本嵌入 ,但将 推离其他跨模态文本嵌入,同时考虑到不同的视觉标记具有不同的重要性(例如,包含病理的视觉标记显然比具有不相关信息的视觉标记更重要),我们在计算LIA损失时为视觉token分配权重 。因此, 如下:
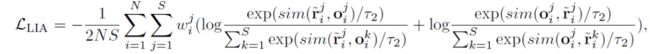
Cross-modal Prototype Alignment (CPA):ITA 和 CTA 都将来自不同实例的样本视为负对,所以可能会把有许多类似的语义的样本在嵌入空间推开,例如相同的疾病的对。因此,CPA模块是为了进行疾病级别的对齐。首先使用迭代的聚类算法Sinkhorn-Knopp,文本和图像分别被聚类算法预测结果是 和 ,同时有 个可学习的原型聚类中心, ,可以直接计算得到图像/文本和每个类中心的softmax概率:

跨模态疾病水平(即原型)对齐是通过进行跨模态预测和优化以下两个交叉熵损失来实现的。使用 作为“伪标签”来训练图像表示 , 作为“伪标签”来训练文本表示 :
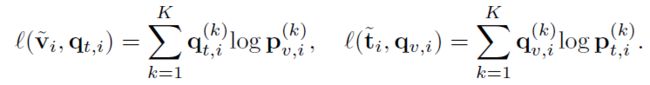
最后,CPA损失是所有图像报告对中两个预测损失的平均值:

MGCA总的目标是三个模块目标的加权和。
LViT: Language meets Vision Transformer in Medical Image Segmentation
http://arxiv.org/abs/2206.14718
LViT 模型主要用于医学图像分割,是一个双 U 结构,由一个 U 形 CNN 分支和一个 U 形 Transformer 分支组成。CNN 分支负责图片输入和预测输出,ViT 分支用于合并图像和文本信息,利用 Transformer 处理跨模态信息。
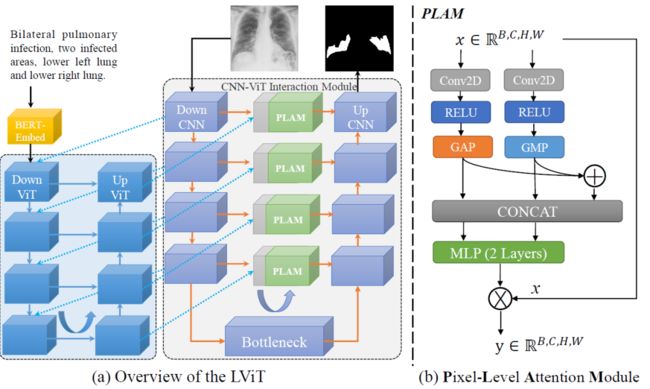
U 形 ViT 分支设计用于合并图像特征和文本特征。第一层DownViT模块接收文本特征输入和来自第一层DownCNN模块的图像特征输入。特定的跨模态特征合并操作由以下等式表示:
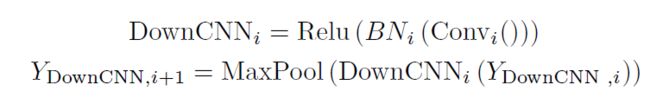
后续 DownViT 模块既接收来自上层 DownViT 模块的特征,又接收来自相应层的 DownCNN 模块的特征。
然后,对应尺寸的特征通过 UpViT 模块传输回 CNN-ViT 交互模块。并且该特征与相应层的 DownCNN 模块中的特征合并。这将最大限度地提取图像全局特征,并避免由于文本注释的不准确性而导致的模型性能振荡。
PLAM模块的设计如上图b所示,旨在保留图像的局部特征,并进一步合并文本中的语义特征;

为了扩展 LViT 的半监督版本,LViT使用指数伪标签迭代机制(EPI)。其中 表示模型 的预测,通过不简单地使用一代模型预测的伪标签作为下一代模型的目标从而避免伪标签质量下降。因此,EPI可以逐步优化模型对每个未标记像素的分割预测结果,并对噪声标签具有鲁棒性。
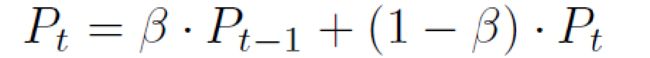
为了进一步利用文本信息来指导伪标签的生成,设计了Languane-Vision Loss函数。首先计算对应于伪标签的文本特征向量和用于对比标签的文本特征向量之间的余弦相似性TextSim。之后根据TextSim,选择相似度最高的对比文本,并找到与该文本对应的图像mask。然后再计算图片的伪标签和对比标签之间的相似性:
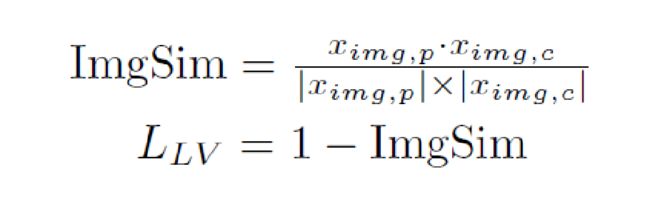
对比标签主要提供近似位置的标签信息,而不是边界的细化。因此 的主要目的是避免差异显著的分割错误或错误标记病例。因此只在未标记的情况下使用LV损失,在没有标签的情况下, 可以避免伪标签质量的急剧恶化。
Adapting Pretrained Vision-Language Foundational Models to Medical Imaging Domains
http://arxiv.org/abs/2210.04133
目前许多生成模型虽然表现出了出色的生成能力,但它们通常不能很好地推广到特定领域,例如医学图像领域。但是,利用生成模型生成一些医学图像出来可能有助于缓解医疗数据集的匮乏。因此,这项工作主要是研究将大型预训练基础模型的表示能力扩展到医学概念,具体来说,本文是利用扩散模型stable diffusion生成医学图像。
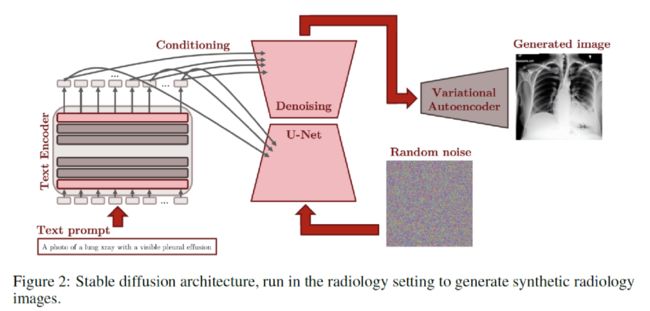
主要是利用了稳定扩散模型的架构,将整个设定转化为了放射学的图像和文本。具体流程如上图二所示,给定随机噪声进行去噪,在这个过程中会有文本作为条件去影响去噪的过程,最后使用VAE的解码器进行图像的生成。整个工作是比较偏实验和验证性的。主要从stable diffusion的各个模块进行训练,包括VAE、Text Encoder、Textual Projection、Textual Embeddings Fine-tuning、U-Net Fine-tuning。

通过两个简单的prompt:“肺部射线照片”和“带有可见胸腔积液的射线照片”来测试不同设置下的生成能力。并通过定量的FID指标进行评估。
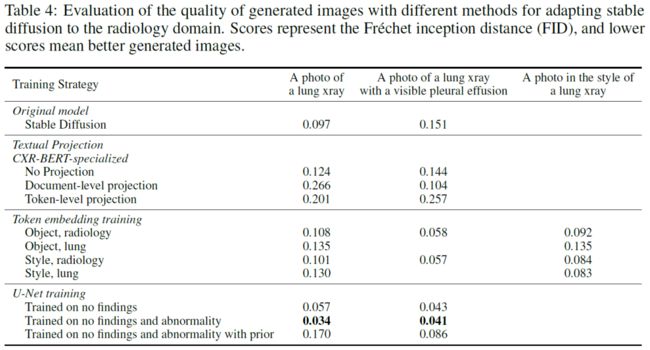
从定性和定量的结果来看,表现最好的是U-Net训练的第二种设定,能够生成较好的图片的同时还能匹配文本的语义,能够理解有无“胸腔积液”的区别。
Generalized radiograph representation learning via cross-supervision between images and free-text radiology reports【Natural Machine Intelligence 2022】
https://arxiv.org/abs/2111.03452
本文提出REFERS模型,主要通过在图像和文本对上进行交叉监督学习去得到放射学表征。
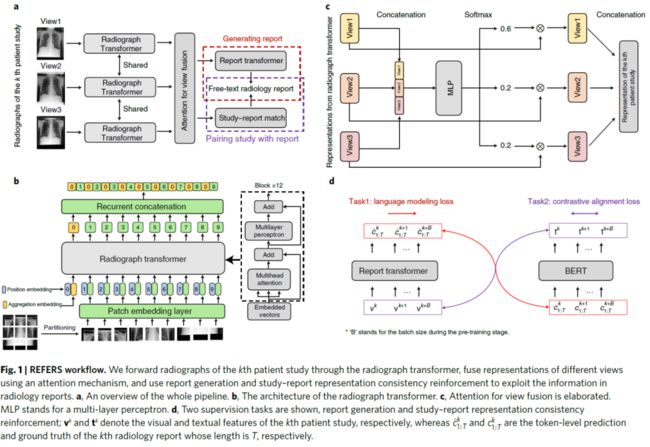
主要考虑到每项患者研究通常都有一份自由文本报告但是通常涉及不止一张 X 光片。首先通过radiograph transformer来提取不同视图的相关特征表示。为了充分利用每份报告的信息,设计了一个基于注意力机制的视图融合模块,以同时处理患者研究中的所有射线照片并融合多个特征。
接下来进行交叉监督学习,从自由文本放射学报告中获取监督信号。主要通过两个任务:reportgeneration和study–report representation consistency reinforcement实现监督。第一项任务采用原始放射学报告中的自由文本来监督radiograph transformer的训练过程。第二项任务加强了患者研究的视觉表示与其相应报告的文本表示之间的一致性。第一项任务主要通过report transformer在给定图像和前面的token的条件下进行token的生成:
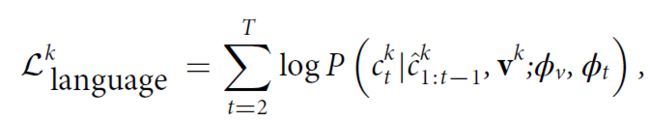
第二项任务通过图像和文本的对比来实现。
RoentGen: Vision-Language Foundation Model for Chest X-ray Generation
http://arxiv.org/abs/2211.12737
本文提出了RoentGen,是用于合成高保真的胸片的生成模型,能够通过自由形式的医学语言文本prompt进行插入、组合和修改各种胸片的成像,同时能够具有相应医学概念的高度的图像相关性。
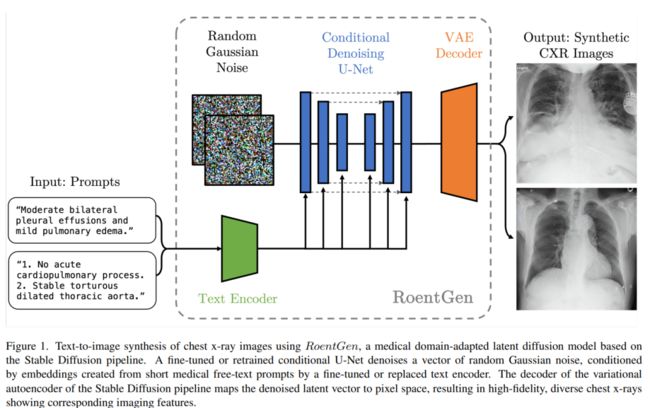
使用RoentGen对胸部X射线图像进行文本到图像合成流程如上图所示。使用微调或重新训练的U-Net 对随机高斯噪声进行降噪,同时此过程中会有文本编码器从医疗文本提示得到的编码。最后VAE的解码器将去噪的向量映射到像素空间,从而产生高保真、多样化的胸部射线图像。
其中,微调或重新训练的具体方式是这样的:使用文本编码器和VAE,对提示 和相应的图像 进行编码,并将采样噪声 添加到后者的潜在表示中,之后U-Net进行预测原始采样噪声 :

计算真实噪声 和预测噪声 之间的MSE loss,由此提高生成能力:

总结:目前医学多模态通过不同的模型设计从而学习局部语义、获取更多相关知识信息、尽可能利用现有数据集、生成图像以尽可能弥补数据量少的问题,在下游的多种任务上得到了性能提升。如何进一步学习更加通用的医学模型、如何将其应用到实际中是仍然值得思考和探索的。
论文解读投稿,让你的文章被更多不同背景、不同方向的人看到,不被石沉大海,或许还能增加不少引用的呦~ 投稿加下面微信备注“投稿”即可。
最近文章
COLING'22 | SelfMix:针对带噪数据集的半监督学习方法
ACMMM 2022 | 首个针对跨语言跨模态检索的噪声鲁棒研究工作
ACM MM 2022 Oral | PRVR: 新的文本到视频跨模态检索子任务
统计机器学习方法 for NLP:基于CRF的词性标注
统计机器学习方法 for NLP:基于HMM的词性标注
点击这里进群—>加入NLP交流群