NLP实战——TextCNN实现新闻文本分类
本文介绍一个NLP中的常用模型——TextCNN。数据集来自天池新闻文本分类比赛数据,这里的文本已经经过匿名处理,可以到天池比赛地址下载数据集和查看模型在测试集上最终表现。
import tensorflow as tf
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras import layers
from sklearn.model_selection import train_test_split
from collections import Counter
from gensim.models import Word2Vec
import numpy as np
from sklearn import preprocessing
from sklearn.metrics import precision_score, accuracy_score,recall_score, f1_score,roc_auc_score, precision_recall_fscore_support, roc_curve, classification_report
train_data=pd.read_csv("train_set.csv",sep='\t')
test_data=pd.read_csv("test_a.csv",sep='\t')
x=train_data['text']
y=train_data['label']
y=y.values.reshape(y.shape[0],1)
One-Hot编码
#y=pd.get_dummies(y)
enc = preprocessing.OneHotEncoder(categories='auto')
enc.fit(y)
y=enc.transform(y).toarray()
enc.categories_
[array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13])]
分词
因为是匿名处理过的数据,所以这里的分词做的很简单,直接按空格进行拆分。
x=x.apply(lambda a:a.split())
训练word2vec词嵌入模型
w2v = Word2Vec(sentences=x,size=300,window=5,min_count=5,sample=1e-3,sg=1)
#window 句子中当前单词与预测词之间的最大距离。
#size 词向量的维数
#min_count 忽略总频率低于此的所有单词。
#sg 训练算法:1为skip-gram,否则为CBOW.
#hs 如果是1,则使用层次化的Softmax进行模型训练。如果为0或负数,则采用负采样.
#cbow_mean 如果为0,则使用上下文单词向量的和。如果是1,使用平均数,只有在使用CBOW时才适用。
#alpha 初始学习率。
#sample 配置高频词随机下采样的阈值,有效范围是(0, 1e-5)。
w2v.save("bag") #训练完成后保持模型到本地,一次训练多次使用;
# w2v = Word2Vec.load("bag") 第一次训练完成后,后续只需使用加载本地模型即可
def average(text,size=300):
if len(text) < 1:
return np.zeros(size)
a = [w2v.wv[w] if w in w2v.wv else np.zeros(size) for w in text]
length = len(a)
summed = np.sum(a,axis=0)
ave = np.divide(summed,length)
return ave
x = x.apply(average)
list_corpus = x.tolist()
x_train,x_test,y_train,y_test = train_test_split(list_corpus,y,test_size=0.05,random_state=1)
x_train=pd.DataFrame(x_train)
x_test=pd.DataFrame(x_test)
x_train=x_train.values.reshape(x_train.shape[0],x_train.shape[1],1)
x_test=x_test.values.reshape(x_test.shape[0],x_test.shape[1],1)
y_train=np.array(y_train)
y_test=np.array(y_test)
x_train.shape,y_train.shape,x_test.shape,y_test.shape
((190000, 300, 1), (190000, 14), (10000, 300, 1), (10000, 14))
num_classes=14 # label中总共14个类
cnn=tf.keras.Sequential([tf.keras.layers.Conv1D(input_shape=x_train.shape[1:],filters=32,kernel_size=5,strides=1,
padding='same',activation='relu',name='conv1'),
tf.keras.layers.MaxPool1D(pool_size=5,strides=2,name='pool1'),
tf.keras.layers.Conv1D(filters=64,kernel_size=5,strides=1,
padding='same',activation='relu',name='conv2'),
tf.keras.layers.MaxPool1D(pool_size=5,strides=2,name='pool2'),
tf.keras.layers.Conv1D(filters=128,kernel_size=5,strides=1,
padding='same',activation='relu',name='conv3'),
tf.keras.layers.MaxPool1D(pool_size=5,strides=2,name='pool3'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128,activation='relu',name='fc1'),
tf.keras.layers.Dense(64,activation='relu',name='fc2'),
tf.keras.layers.Dropout(0.5),
tf.keras.layers.Dense(32,activation='relu',name='fc3'),
tf.keras.layers.Dense(num_classes,activation='softmax',name='output')])
nadam = tf.keras.optimizers.Nadam(lr=1e-3)
cnn.compile(optimizer=nadam,loss='categorical_crossentropy',metrics=['categorical_accuracy']) #设置优化器和损失函数
cnn.summary()#查看模型基本信息
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv1 (Conv1D) (None, 300, 32) 192
_________________________________________________________________
pool1 (MaxPooling1D) (None, 148, 32) 0
_________________________________________________________________
conv2 (Conv1D) (None, 148, 64) 10304
_________________________________________________________________
pool2 (MaxPooling1D) (None, 72, 64) 0
_________________________________________________________________
conv3 (Conv1D) (None, 72, 128) 41088
_________________________________________________________________
pool3 (MaxPooling1D) (None, 34, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 4352) 0
_________________________________________________________________
fc1 (Dense) (None, 128) 557184
_________________________________________________________________
fc2 (Dense) (None, 64) 8256
_________________________________________________________________
dropout (Dropout) (None, 64) 0
_________________________________________________________________
fc3 (Dense) (None, 32) 2080
_________________________________________________________________
output (Dense) (None, 14) 462
=================================================================
Total params: 619,566
Trainable params: 619,566
Non-trainable params: 0
_________________________________________________________________
history=cnn.fit(x_train,y_train,epochs=100,verbose=1)
Train on 190000 samples
Epoch 1/100
WARNING:tensorflow:Entity .initialize_variables at 0x7ff50660a730> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: No module named 'tensorflow_core.estimator'
WARNING: Entity .initialize_variables at 0x7ff50660a730> could not be transformed and will be executed as-is. Please report this to the AutoGraph team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output. Cause: No module named 'tensorflow_core.estimator'
190000/190000 [==============================] - 107s 563us/sample - loss: 0.7070 - categorical_accuracy: 0.7866
Epoch 2/100
190000/190000 [==============================] - 106s 557us/sample - loss: 0.4536 - categorical_accuracy: 0.8690
Epoch 3/100
190000/190000 [==============================] - 106s 560us/sample - loss: 0.4099 - categorical_accuracy: 0.8806
Epoch 4/100
190000/190000 [==============================] - 106s 559us/sample - loss: 0.3859 - categorical_accuracy: 0.8880
Epoch 5/100
190000/190000 [==============================] - 106s 559us/sample - loss: 0.3692 - categorical_accuracy: 0.8920
Epoch 6/100
190000/190000 [==============================] - 106s 559us/sample - loss: 0.3575 - categorical_accuracy: 0.8947
Epoch 7/100
190000/190000 [==============================] - 106s 559us/sample - loss: 0.3489 - categorical_accuracy: 0.8972
Epoch 8/100
190000/190000 [==============================] - 106s 558us/sample - loss: 0.3406 - categorical_accuracy: 0.8994
Epoch 9/100
190000/190000 [==============================] - 106s 559us/sample - loss: 0.3317 - categorical_accuracy: 0.9015
Epoch 10/100
190000/190000 [==============================] - 106s
Epoch 20/100
190000/190000 [==============================] - 106s 559us/sample - loss: 0.2886 - categorical_accuracy: 0.9137
Epoch 30/100
190000/190000 [==============================] - 106s 558us/sample - loss: 0.2677 - categorical_accuracy: 0.9204
Epoch 40/100
190000/190000 [==============================] - 106s 558us/sample - loss: 0.2514 - categorical_accuracy: 0.9250
Epoch 50/100
190000/190000 [==============================] - 106s 558us/sample - loss: 0.2391 - categorical_accuracy: 0.9290
Epoch 60/100
190000/190000 [==============================] - 106s 559us/sample - loss: 0.2313 - categorical_accuracy: 0.9314
Epoch 70/100
190000/190000 [==============================] - 106s 558us/sample - loss: 0.2273 - categorical_accuracy: 0.9331
Epoch 80/100
190000/190000 [==============================] - 130s 684us/sample - loss: 0.2232 - categorical_accuracy: 0.9344
Epoch 90/100
190000/190000 [==============================] - 130s 685us/sample - loss: 0.2116 - categorical_accuracy: 0.9382
Epoch 100/100
190000/190000 [==============================] - 130s 686us/sample - loss: 0.2072 - categorical_accuracy: 0.9399
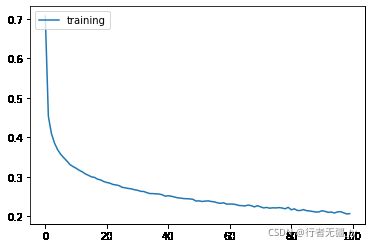
plt.plot(history.history['loss'])
plt.legend(['training'], loc='upper left')
plt.show()
测试集评估
# sortmax 结果转 onehot
def props_to_onehot(props):
if isinstance(props, list):
props = np.array(props)
a = np.argmax(props, axis=1)
b = np.zeros((len(a), props.shape[1]))
b[np.arange(len(a)), a] = 1
return b
# 自定义评估方法
def evalute_ty(predict_prop,predict_y,real_y):
'''自定义模型评估方法
评估不同阈值下模型的性能,将打印acc/precision/recall/f1/auc值
Args:
predict_prop:预测的概率值
predict_y:预测值
real_y :真实标签
'''
acc=round(accuracy_score(real_y,predict_y),3)
precision=round(precision_score(real_y, predict_y,average='weighted'),3)#准确率:预测为正的样本中实际为正的比例
recall=round(recall_score(real_y, predict_y,average='weighted'),3)#召回率:所有正样本中预测为正的比例
f1=round(f1_score(real_y, predict_y,average='weighted'),3)
auc=round(roc_auc_score(y_test, predict_prop,multi_class='ovo'),3)
print('acc {},precision {},recall {},f1 {},auc {}'.format(acc,precision,recall,f1,auc))
predict_prop=cnn.predict(x_test)
predict_prop.shape
(10000, 14)
predict_y=enc.inverse_transform(props_to_onehot(predict_prop))
real_y=enc.inverse_transform(y_test)
evalute_ty(predict_prop,predict_y,real_y)
acc 0.905,precision 0.906,recall 0.905,f1 0.905,auc 0.99
生成最终结果
x_test=test_data['text']
x_test=x_test.apply(lambda a:a.split())
x_test = x_test.apply(average) #注意此处的df["text"] 未分词
test_list_corpus = x_test.tolist()
x_test=pd.DataFrame(test_list_corpus)
x_test=x_test.values.reshape(x_test.shape[0],x_test.shape[1],1)
x_test.shape
(50000, 300, 1)
res=cnn.predict(x_test)
final=enc.inverse_transform(props_to_onehot(res))
final=final.reshape(final.shape[0],)
df=pd.DataFrame()
df['label']=final
df.to_csv('textcnn_submit.csv',index=None)
最终得分: