TextCNN文本分类实现(主要是CNN模型的使用)
前言:项目基于CNN模型,对输入问题进行训练,让机器可以识别出问题的类别从而通过相应类别查询所要寻找的数据
有关于数据部分的链接:https://pan.baidu.com/s/16ZR6LVVLP-_4mXLJG_aD4g?pwd=1111
你需要把它放在所建立的py文件通文件夹下,
原因如是
注:有关浅谈和一些题外话仅仅作为学习过程中的测试用,代码中不加入无关紧要
目录
0.导入包
1.read_data()#读取数据文件
2.built_curpus()#建立语料库
2.1浅谈一下get的作用以及用法:
2.1.1一个例子
2.1.2get() 方法 Vs dict[key] 访问元素区别
2.1.3嵌套字典使用
2.2浅谈一下nn.embedding
3.class TextDataset()#建立数据集处理数据
4.class Block()#一个卷积核(包含卷积层、激励层、池化层)
4.1浅谈conv1d和conv2d的区别
5.class TextCNNModule(nn.Module)#继承自nn.module的CNN模型
6.主函数
0.导入包
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset,DataLoader
from tqdm import tqdm1.read_data()#读取数据文件
def read_data(train_or_test,num=None):
with open(os.path.join(train_or_test + ".txt"),encoding="utf-8") as f:
all_data = f.read().split("\n")
texts = []
labels = []
for data in all_data:
if data:
t,l = data.split("\t")
texts.append(t)
labels.append(l)
if num == None:
return texts,labels
else:
return texts[:num],labels[:num]用path.join方法实现了函数可以提取train数据以及test数据
texts、labels列表分别存储数据文字部分和每句话对应的标签
num表示取前多少行数据
2.built_curpus()#建立语料库
def built_curpus(train_texts,embedding_num):#传入参数:语料
word_2_index = {"":0,"":1}#填充为零,未知为一
for text in train_texts:
for word in text:
word_2_index[word] = word_2_index.get(word,len(word_2_index))
#get方法get(key) 方法在 key(键)不在字典中时,可以返回默认值 None 或者设置的默认值。
return word_2_index,nn.Embedding(len(word_2_index),embedding_num)
#返回键值以及一个tensor类型的张量,这个张量代表了生成字典元素个数个嵌入向量,每个嵌入向量的维度是embedding_num
2.1浅谈一下get的作用以及用法:
2.1.1一个例子
tinydict = {'Name': 'Runoob', 'Age': 27}
print ("Age : %s" % tinydict.get('Age'))
# 没有设置 Sex,也没有设置默认的值,输出 None
print ("Sex : %s" % tinydict.get('Sex'))
# 没有设置 Salary,输出默认的值 0.0
print ('Salary: %s' % tinydict.get('Salary', 0.0))输出结果为
Age : 27 Sex : None Salary: 0.0
2.1.2get() 方法 Vs dict[key] 访问元素区别
get(key) 方法在 key(键)不在字典中时,可以返回默认值 None 或者设置的默认值。
dict[key] 在 key(键)不在字典中时,会触发 KeyError 异常。
2.1.3嵌套字典使用
get() 方法对嵌套字典的使用方法如下:
tinydict = {'RUNOOB' : {'url' : 'www.runoob.com'}}
res = tinydict.get('RUNOOB', {}).get('url')
# 输出结果
print("RUNOOB url 为 : %s" % str(res))
以上实例输出结果为:
RUNOOB url 为 : www.runoob.com
2.2浅谈一下nn.embedding
embedding = nn.Embedding(6, 2)
print(embedding.weight)第1个参数 num_embeddings 就是生成num_embeddings个嵌入向量。第2个参数 embedding_dim 就是嵌入向量的维度,即用embedding_dim值的维数(均为随机数)来表示一个基本单位,在我的例子里面用的是50个随机数表示一个字。如下所示
Parameter containing:
tensor([[-0.7965, -0.2459],
[ 1.1508, -0.7320],
[ 0.0154, -0.2846],
[ 0.2236, -0.0293],
[ 0.5198, -1.1245],
[ 0.7478, 0.3544]], requires_grad=True)而且我们可以通过计算得到均值0.0049,方差0.9697,嵌入向量中的值是服从标准正态分布的。
3.class TextDataset()#建立数据集处理数据
class TextDataset(Dataset):
def __init__(self,all_text,all_label,word_2_index,max_len):
self.all_text = all_text
self.all_label = all_label
self.word_2_index = word_2_index
self.max_len = max_len
def __getitem__(self,index):
text = self.all_text[index][:self.max_len]
label = int(self.all_label[index])
text_idx = [self.word_2_index.get(i,1) for i in text]
text_idx = text_idx + [0] * (self.max_len - len(text_idx))
text_idx = torch.tensor(text_idx).unsqueeze(dim=0)
return text_idx,label
def __len__(self):
return len(self.all_text)4.class Block()#一个卷积核(包含卷积层、激励层、池化层)
class Block(nn.Module):
def __init__(self,kernel_s,embeddin_num,max_len,hidden_num):
super().__init__()#标准写法
#卷积层
self.cnn = nn.Conv2d(in_channels=1,out_channels=hidden_num,kernel_size=(kernel_s,embeddin_num)) # 1 * 1 * 7 * 5 (batch * in_channel * len * emb_num )
#激活层(采用Relu)
self.act = nn.ReLU()
#池化层(取最大值)
self.mxp = nn.MaxPool1d(kernel_size=(max_len-kernel_s+1))
#进行三步自动化运算
def forward(self,batch_emb): # 1 * 1 * 20 * 50 (batch * in_channel * len * emb_num )
c = self.cnn.forward(batch_emb)
a = self.act.forward(c)
a = a.squeeze(dim=-1)
m = self.mxp.forward(a)
m = m.squeeze(dim=-1)
return m
4.1浅谈conv1d和conv2d的区别
这篇博客既详细又好懂PyTorch中的nn.Conv1d与nn.Conv2d - 简书
conv1d简单来说一个句子没有高度,只有宽度,宽度指的是每一个字的维度(在本项目中,将高度设置为句子里的字数,宽度设置为字的维度,当然由于这时候channel没了,默认设置为1)
conv2d指的是一张图片有高度也有宽度,当然通道数还是可以类比RGB
另外插一句,本项目虽是文本的处理,但是然输入了四维数据(原作者不想改了,等我想改的时候再改吧)conv2d也而不是不能用。
nn.Conv2d(in_channels=1,out_channels=hidden_num,kernel_size=(kernel_s,embeddin_num)) 传入的参数为输入channel,输出channel,卷积核大小(每次取字数,字的维度),见下图就明白了
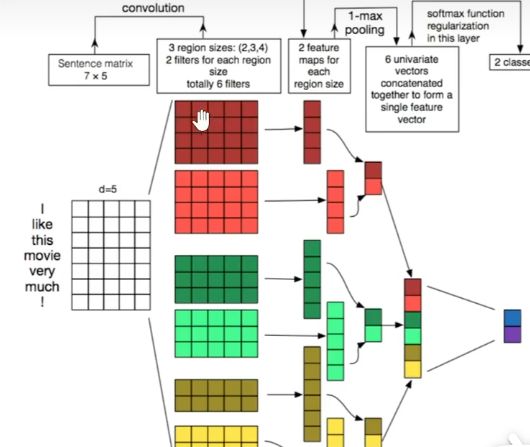
浅谈forward
5.class TextCNNModule(nn.Module)#继承自nn.module的CNN模型
class TextCNNModel(nn.Module):
def __init__(self,emb_matrix,max_len,class_num,hidden_num):
super().__init__()
self.emb_num = emb_matrix.weight.shape[1]
#第二个值为文字维度,一直对应到语料库第二个返回值的第二个元素,承接上文提到的nn.embedding函数的使用与返回结果
self.block1 = Block(2,self.emb_num,max_len,hidden_num)
self.block2 = Block(3,self.emb_num,max_len,hidden_num)
self.block3 = Block(4,self.emb_num,max_len,hidden_num)
self.block4 = Block(5,self.emb_num,max_len,hidden_num)#每次取词,词的维度
#构建每一个block
self.emb_matrix = emb_matrix
self.classifier = nn.Linear(hidden_num*4,class_num) # 2 * 3
self.loss_fun = nn.CrossEntropyLoss()
def forward(self,batch_idx,batch_label=None):#可以选择不传label值,就是训练的情况
batch_emb = self.emb_matrix(batch_idx)#根据id号找到相应生成的embedding
b1_result = self.block1.forward(batch_emb)
b2_result = self.block2.forward(batch_emb)
b3_result = self.block3.forward(batch_emb)
b4_result = self.block4.forward(batch_emb)
feature = torch.cat([b1_result,b2_result,b3_result,b4_result],dim=1) # 1* 6 : [ batch * (3 * 2)]
pre = self.classifier(feature)
if batch_label is not None:#有标签代表是训练
loss = self.loss_fun(pre,batch_label)
return loss
else:#没有标签代表是预测
return torch.argmax(pre,dim=-1)#返回概率最大的那个batch_emb 是一个![]() 这样的矩阵,代表的意思是一个句子,20个字(包括padding),每个字50个维度表示。
这样的矩阵,代表的意思是一个句子,20个字(包括padding),每个字50个维度表示。
b1_result 是经过block1得到的运算,这个block1是一个包含卷积层,激活层,池化层合为一体的运算核,cat将b1、b2、b3、b4合起来得到特征feature,然后用classifier进行分类
6.主函数
if __name__ == "__main__":
train_text,train_label = read_data("book")
dev_text,dev_label = read_data("dev")
embedding = 50
max_len = 20
batch_size = 200
epoch = 200
lr = 0.001
hidden_num = 2#输出通道
class_num = len(set(train_label))
device = "cuda:0" if torch.cuda.is_available() else "cpu"
word_2_index,words_embedding = built_curpus(train_text,embedding)#返回的字的编号和每个字所对应的维度向量
train_dataset = TextDataset(train_text,train_label,word_2_index,max_len)
train_loader = DataLoader(train_dataset,batch_size,shuffle=False)
dev_dataset = TextDataset(dev_text, dev_label, word_2_index, max_len)
dev_loader = DataLoader(dev_dataset, batch_size, shuffle=False)
model = TextCNNModel(words_embedding,max_len,class_num,hidden_num).to(device)进入模型进行forward
opt = torch.optim.AdamW(model.parameters(),lr=lr)#进行优化
for e in range(epoch):
for batch_idx,batch_label in train_loader:
batch_idx = batch_idx.to(device)
batch_label = batch_label.to(device)
loss = model.forward(batch_idx,batch_label)
loss.backward()#反向传播找到合适的参数
opt.step()
opt.zero_grad()
print(f"loss:{loss:.3f}")#损失值
right_num = 0#统计测试集正确的数量
for batch_idx,batch_label in dev_loader:
batch_idx = batch_idx.to(device)
batch_label = batch_label.to(device)
pre = model.forward(batch_idx)
right_num += int(torch.sum(pre==batch_label))#统计测试集正确的数量
MODEL_DIR = '../output/提问训练/'
torch.save(model, MODEL_DIR+f'model_{e}.pth')#将模型存储到pth文件中
print(f"acc = {right_num/len(dev_text)*100:.2f}%")#输出正确率