【论文简述及翻译】A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and SceneFlow
一、论文简述
1. 第一作者:Nikolaus Mayer等
2. 发表年份:2016
3. 发表期刊:CVPR
4. 关键词:数据集、视差估计、场景流估计、光流估计、端到端训练
5. 探索动机:因为缺乏具有足够真实性的并且充分标注的真实值的大型数据集,所以不能有效地训练和评估用于视差、光流和场景流估计的卷积神经网络。
6. 工作目标:光流估计可以在一个大型合成数据集上训练,是否可以将光流估计模型扩展到视差估计和场景流估计中,在大型合成数据集上使用卷积神经网络来解决视差估计与场景流估计问题?
7. 核心思想:提出了SceneFlow数据集,能够训练和评估光流、视差、场景流估计;提出了一个用于实时视差估计的卷积神经网络;提出了第一个使用卷积网络的场景流估计。
8. 实现方法:
- SceneFlow数据集由三个具有足够真实性、变化和大小的合成立体视频数据集,包含超过35000个立体图像对的综合数据集,其中包含视差,光流和场景流的真实值,适合于训练卷积网络也可以用于其他方法的评估。
- DispNet用于实时视差估计,是基于FlowNet的结构进行微调的网络,与FlowNet的结构基本一致。是第一个使用端到端网络解决视差估计问题的方法。
- 通过结合光流和视差估计网络并联合训练,实现了第一个使用卷积网络的场景流估计。
9. 实验结果:表明了使用大型数据集可以用于训练大型卷积网络,实现端到端的视差估计,性能与最先进的网络相当,并且运行速度提高了1000倍。 第一次使用标准网络结构来训练网络以进行场景流估计的方法也显示出有希望的结果。该数据集将有助于提高深度学习研究例如立体匹配、光流和场景流估计这样的具有挑战性的视觉任务。
10.论文下载:
https://openaccess.thecvf.com/content_cvpr_2016/papers/Mayer_A_Large_Dataset_CVPR_2016_paper.pdf
二、论文翻译
A Large Dataset to Train Convolutional Networks for Disparity, Optical Flow, and Scene Flow Estimation
摘要
最近的工作表明,光流估计可以被作为一种有监督的学习任务,并且可以通过卷积网络成功解决。所谓的FlowNet的训练是由一个大型的综合生成的数据集实现的。本文通过卷积网络将光流估计的概念扩展到视差和场景流估计。为此,我们提出了三个具有足够真实性、变化和大小的合成立体视频数据集,用于成功训练大型网络。我们的数据集是第一个能够训练和评估场景流方法的大规模数据集。除了数据集,我们还提出了一个用于实时视差估计的卷积网络,它提供了最先进的结果。通过结合光流和视差估计网络并联合训练,我们展示了第一个使用卷积网络的场景流估计。
1. 介绍
估计场景流意味着提供立体视频中所有可见点的深度和3D运动矢量。在重建和运动估算方面,这是“皇家联盟”的任务,并为高级驾驶员的辅助和自主系统等众多更高级别的挑战提供了重要依据。近几十年来的研究集中在它的子任务上,即视差估计和光流估计上,取得了相当大的成功。全场景流的问题还没有探索到同样的程度。尽管可以从子任务结果中简单地组合获得部分场景流,但是人们预期所有组件的联合估计将对效率和精度更有利。场景流的研究的比其子任务少的一个原因似乎是缺乏充分标注真实值的数据。
在卷积网络时代,此类数据的可用性变得更加重要。Dosovitskiy等人发现光流估计可以作为一个有监督的学习问题,并且可以用一个大型网络来解决。为了训练他们的网络,他们创建了一个简单的合成2D Flying chairs数据集,事实证明这足以预测一般视频中的准确光流。这些结果表明,视差和场景流也可以理想地通过卷积网络进行联合、高效和实时地估计。实现这一想法所缺少的是具有足够真实性和可变性的大型数据集来训练这样的网络并评估其性能。
在本文中,我们提供了三个这样的数据集的集合,使用开源3D创建套件Blender的定制版本。我们的成果在思想上与Sintel基准相似。与Sintel相比,我们的数据集足够大有助于卷积网络的训练,并且为场景流提供了真实值。特别地,它包括用于双相视差、双向光流、视差变化、运动边界和目标分割的立体彩色图像和真实值。此外,还提供完整的相机校准和3D点位置,即我们的数据集还涵盖RGBD数据。
我们无法在一篇论文中充分开发该数据集的潜力,但我们已经展示了与卷积网络训练相结合的各种使用实例。我们训练了一个用于视差估计的网络,该网络在以前的基准测试中也产生了具有竞争力的性能,特别是在那些实时运行的方法中。最后,我们还提出了一个用于场景流估计的网络,并在足够大的测试集上提供了全场景流的第一个定量数。
2. 相关工作
数据集。创建标准数据集的第一个重要的结果是用于立体视差估计和光流估计的Middlebury数据集。虽然立体数据集由真实场景组成,但光流数据集是真实场景和渲染场景的混合。就今天而言,这两个数据集都非常小。特别是,小的测试集会导致严重的人工过拟合。立体数据集的一个优势是相关真实场景的可用性,尤其是在2014年最新的高分辨率版本中。
MPI Sintel是一个完全合成的数据集,源自一部简短的开源动画3D电影。它为光流提供了密集的真实值。从最近开始,具有视差的beta测试版本可以用来训练。Sintel数据集有1064个训练帧,是目前可用的最大数据集。它包含足够真实的场景,包括自然图像退化,例如雾和运动模糊。作者为所有帧和像素的真实值的正确性付出了很多努力。这使得数据集成为用于方法比较的非常可靠的测试集。然而,对于训练卷积网络,数据集仍然太小。
KITTI数据集制作于2012年,并在2015年进行了扩充。它包含安装在汽车上的一对校准摄像机拍摄的道路场景的立体视频。通过3D激光扫描仪结合汽车的运动数据可以获得光流和视差的真实值。虽然数据集包含真实数据,但采集方法将真实值限制在场景的静态部分。而且,激光只能提供一定距离和高度的稀疏数据。对于最新版本,汽车的3D模型被拟合在点云中以获得更密集的标签,还包括移动的物体。但是,这些区域的真实值依然是一个近似值。
Dosovitskiy等人在叠加了自然背景图像的移动的2D椅子图像的合成数据集上训练卷积网络进行光流估计。这个数据集很大,但仅限于单视图光流,不包含任何3D运动。
最新的Sintel数据集和KITTI数据集都可以用于估计场景流,但有一些限制。在遮挡区域(在一帧中可见但在另一帧中不可见),场景流的真实值是不可用的。在KITTI中,场景流最有吸引力的部分,就是前景点的三维运动,通过拟合的汽车CAD模型是近似或缺失的。表1给出了最重要的可对比的数据集及其特征的综合概述。
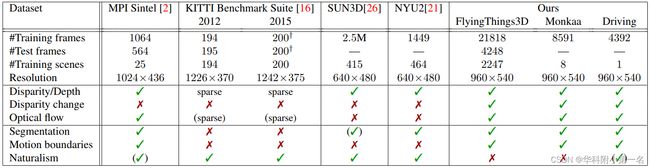
表1.可用数据集的比较:我们的新系列比现有数据集提供了更多的注释数据和更多的数据类型。我们所有的数据具有完全连续、密集、准确的真实值。请注意,在KITTI2015 中,一个场景是由21个立体对组成的序列,但真实值仅由单帧提供。
卷积网络:卷积网络已被证明在各种识别任务中非常成功,如图像分类。卷积网络的最新应用还包括基于单个图像的深度估计,立体匹配和光流估计。
Dosovitskiy等人的FlowNet与我们的工作最相关。它使用编码-解码架构,在收缩和扩展网络部分之间增加了额外的交叉连接,其中编码器从尺寸不断增加的感受野计算抽取的特征,而解码器通过扩展的上卷积结构重新建立原始分辨率。我们采用这种方法进行视差估计。
Zbontar等人的视差估计方法使用Siamese网络来计算图像块之间的匹配距离。为了最终估计视差,作者进行了基于交叉的代价聚合和半全局匹配(SGM)。与我们的工作相反,Zbontar等人在视差估计任务上没有端到端的地训练卷积网络,对计算效率和简洁性有相应的影响。
场景流:虽然有数百篇关于视差估计和光流估计的论文,但关于场景流的很少。他们也没有使用学习方法。
Vedula等人的工作首次推广了场景流估计,并分析了不同的可能问题设置。后来的工作主要是变分方法为主。Huguet和Devernay用联合变分方法解决场景流估计。 Wedel等人遵循变分框架,但将视差估计解耦以提高效率和精度。Vogel等人使用分段刚性模型把场景流估计的任务与超像素分割结合,进行正则化。Quiroga等人将正规化项进一步扩展到刚性运动的平滑域。Wedel等人他们将视差估计解耦,并用RGBD视频的深度值代替。
KITTI场景流中最快的方法由Cech等人提出,运行时间为2.4秒。该方法采用种子生长算法同时进行视差和光流估计。
3. 场景流的定义
光流是世界上的三维运动在图像平面上的投影。通常,场景流被认为是可以从立体视频或RGBD视频计算的底层3D运动场。假定立体图像对的两个连续的时间帧t和t+1,产生四个图像(ItL,ItR,It+1L,It+1R)。场景流为这四个图像中的每个可见点提供点的三维位置和三维运动矢量。
这些3D数量只能在已知相机内参和外参的情况下计算。场景流独立于相机的定义是通过单独的组件如光流、视差和视差变化来获得的。参见图2。如果相机参数已知,则可以从组件计算可见3D点及其3D运动矢量,从这个意义上说这种表示是完整的。

图2. 给定时间t-1,t和t+1的立体图像,箭头表示它们之间的视差和光流关系。红色部分通常用于估计场景流。在我们的数据集中,我们提供所有的关系,包括蓝色箭头。
鉴于t和t+1处的视差,视差变化几乎是多余的。因此,在 KITTI 2015 场景流基准中,仅评估了光流和视差。在这种情况下,只能在左右帧中都可见的表面点重建场景流。特别是在卷积网络的背景下,估计部分遮挡区域的深度和运动特别有吸引力。此外,从光流和视差重建3D运动对噪声更敏感,因为光流中的小误差会导致3D运动矢量中的大误差。
4. 三个渲染的数据集
我们创建了一个由三个子集组成的合成数据集组,提供了前后方向上完整的真实的场景流(包括视差变化)。为此,我们使用了开源的3D创建组Blender为具有大量复杂运动的物体设置动画,并将结果渲染成数万帧。我们修改了Blender内部渲染引擎的管道机制,除了立体RGB图像之外,还为每帧和每个视图产生了三个额外的数据传递。这些提供了所有可见表面点的3D位置,以及它们的未来和过去的3D位置。对于给定的相机视图,两个此类数据传递之间的像素差异会产生3D运动矢量的“图像”——如这台相机所看到的完整场景流的真实值。值得注意的是,即使在被遮挡的区域中,信息也是完整的,因为渲染引擎始终对所有(可见和不可见)场景点都有完整的了解。
所有透光材料-特别是大多数车窗-都被渲染为完全透明的,以避免3D数据中的一致性问题。为了防止图层混合人工物品,我们在没有抗混叠的情况下渲染了所有非RGB数据。
给定相机内在参数(焦距,主点)和渲染设置(图像大小,虚拟传感器大小和格式),我们将每个像素的3D运动矢量投影成与成像平面共面的2D像素运动矢量:光流。直接从像素的3D位置检索深度,并使用虚拟立体装置的已知配置将其转换为视差。我们根据3D运动矢量的深度部分计算视差变化。示例如图1、3、8所示。

图1.我们的数据集为光流、视差和视差变化以及其他数据(例如目标分割)提供了超过35000个具有密集真实值的立体帧。

图3.FlyingThings3D数据集中的场景示例。第3行:光流图像,第4行:视差图像,第5行:视差变化图像。在高分辨率的彩色屏幕上的最佳视图(规范化的数据图像显示)。

图8.从预训练的FlowNet和DispNets创建的SceneFlowNet的结果。添加了视差变化,并在FlyingThings3D上对网络反复微调了50万次。
此外,我们渲染了目标分割掩码,其中每个像素的值对应于其目标的唯一索引。目标可以由多个子部分组成,每个子部分都可以具有单独的材质(具有自己的外观属性,例如纹理)。我们利用这一点并渲染额外的分割掩码,其中每个像素都对其材质的索引进行编码。近期可用的 Sintel的beta版也包含此数据。
与Sintel数据集类似,我们还提供目标和材料的分割,以及突显了至少两个移动目标之间的像素的运动边界,如果以下情况成立:目标之间的运动差异至少为1.5个像素,并且边界分割覆盖至少10个像素的区域。阈值的选择匹配Sintel的分割结果。
对于所有帧和视图,我们提供完整的相机内参和外参矩阵。这些可用于运动结构或其他需要相机跟踪的任务。我们在32mm宽的模拟传感器上使用35mm的虚拟焦距渲染所有图像数据。对于驾驶数据集,我们添加了一个使用15mm焦距的广角版本,在视觉上更接近现有的KITTI数据集。
像Sintel数据集一样,我们的数据集也包括每个图像的两个不同的版本:clean pass显示颜色、纹理和场景亮度,但没有图像退化,而final pass还增加了包括后处理效果,如模拟景深模糊,运动模糊,阳光眩光和伽玛曲线操作。
为了处理海量数据(2.5TB),我们将所有RGB图像数据压缩为有损但高质量的WebP5格式(我们提供WebP和无损PNG版本)。非RGB数据进行无损压缩。
4.1 FlyingThings3D
新数据收集的主要部分包括沿着随机3D轨迹飞行的日常物体。我们用真实值数据生成了约25000个立体帧。我们没有专注于某个特定的任务(如KITTI),也没有执行严格的自然主义(如Sintel),而是依靠随机性和大量的渲染条件来产生比现有选项更多数量的数据,并且没有重复或饱和的风险。数据生成速度快,完全自动化,并为完整的场景流任务提供密集且准确的真实值。创建这个数据集的动机是促进大型卷积网络的训练,这将受益于很大的多样性。
每个场景的基础是一个大的有纹理的地平面。我们生成了200个静态背景物体,其形状是从长方体和变形的圆柱体中随机选取。每个物体随机缩放、旋转、纹理,然后放置在地平面上。
为了迁移场景,我们从斯坦福的ShapeNet数据库下载了35927个精细的3D模型。 从这些模型中我们组建了具有32872个模型的训练集和3055个模型的测试集。(模型类型也被拆分)。
我们从这个物体集合中随机抽取了5到20个物体,并随机地构造每个物体的材质。相机和所有的ShapeNet物体都沿着连续的3D轨迹进行平移和旋转,这样相机就可以看到物体,但具有随机的位移。
纹理集合是使用ImageMagick创建的程序图像的结合,乡村风景和城市风景照片来自Flickr,纹理风格的照片来自Image*After。像3D模型一样,纹理图片也被分割成不相交的训练和测试部分。
对于final pass图像,场景的呈现和运动模糊及离焦模糊的强度各不相同。
4.2. Monkaa
我们的数据集的第二部分是由动画短片Monkaa的开源Blender资源制作的。在这方面,它类似于MPI Sintel数据集。Monkaa包含非刚性和柔和的链式运动,以及视觉上具有挑战性的皮毛。除此之外,与Sintel几乎没有视觉上的相似之处; Monkaa电影并不追求同等的自然主义。
我们选择了许多合适的电影场景,并额外使用来自Monkaa的部分和片段创建了全新的场景。为了增加数据量,我们将自制场景渲染为多个版本,每个版本的相机的旋转和运动轨迹都进行了随机增量的改变。
4.3. Driving
从驾驶汽车的角度来看,驾驶场景是一个极其自然的、动态的街景,与KITTI数据集相似。它使用了来自FlyingThings3D数据集中相同的汽车模型,并额外使用3D Warehouse高度精细的树模型和简单的街灯。在图4中,我们展示了从Driving中挑选的画面和来自KITTI 2015相似的画面。

图4. 2015版KITTI基准测试组和我们新的驾驶数据集的示例帧。两者都显示了从各种现实的视角下许多静态和动态汽车,薄物体,复杂的阴影,起伏不平的地面和具有挑战性的镜面反射。
我们的立体基线设置为1个Blender单元,加上典型的车型宽度约为2个单位,与KITTI的设置相似(54厘米的基线,186厘米的车宽度)。
5. 网络
为了证明我们新合成的数据集适用于场景流估计,我们用它来训练卷积网络。一般来说,我们遵循FlowNet的架构:每个网络由一个收缩部分和一个扩展部分组成,它们之间有长距离连接。收缩部分包含卷积层,部分步幅为2,因此总的下采样因子为64。这使得网络能够估计大的位移。然后网络的扩展部分逐步非线性地对特征图进行上采样,并且也考虑到收缩部分的特征。这是通过一系列上卷积和卷积层完成的。请注意,网络中没有数据瓶颈,因为信息也可以通过收缩层和扩展层之间的长距离连接进行传递。 为了说明整体结构,我们参考了Dosovitskiy等人的图。
对于视差估计,我们提出了表2中描述的基本架构DispNet。我们发现扩展部分的添加的卷积产生了比FlowNet结构更平滑的视差图(见图6)。
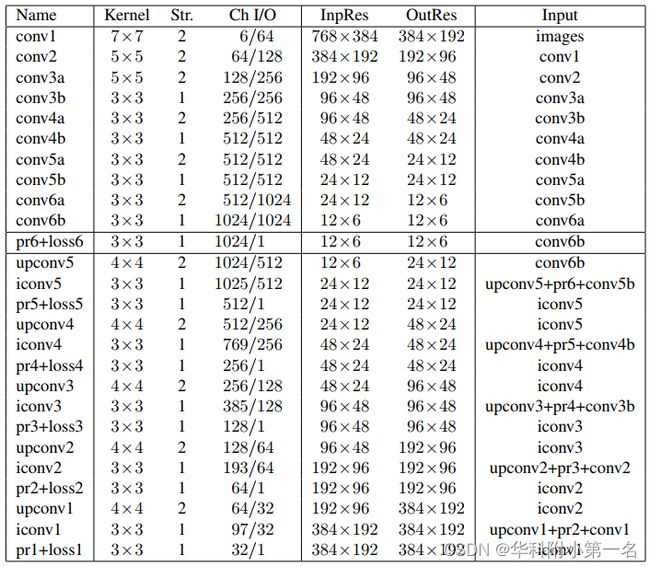
表2. DispNet结构的详述。收缩部分由卷积conv1到conv6b组成。在扩展部分,上卷积(upconvN),卷积(iconvN,prN)和损失层是交替出现。较低层的特征与较高层特征连接。预测的视差图像由pr1输出。

图6.上卷积之间没有(左)和(右)卷积的预测视差图的特写。注意右边的预测更平滑。
我们还测试了一个使用明确的相关层结构,我们称之为DispNetCorr。在这个网络中,两个图像被分别在conv2层处理,然后所得到的特征在水平方向相关。我们考虑了40个像素的最大位移,这相当于输入图像中的160个像素。相比于Dosovitskiy等人的2D相关,1D相关的计算成本要低得多,与FlowNet相比,我们可以用更精细的采样覆盖更大的位移,后者使用步长为2进行相关。
我们通过结合和微调视差和光流的预训练网络来训练FlowNet和联合SceneFlowNet来进行场景流估计。如图5所示。FlowNet预测左右图像的光流,两个DispNets预测t和t+1处的视差。这种情况下的网络在上卷积之间不包含相关层和的卷积。然后我们微调大型组合网络,估计光流、视差和视差变化。

图5. 将FlowNet(绿色)和两个DispNets(红色和蓝色)的权重交错给SceneFlowNet。对于每一层,通过取一个网络的权重(左),并将其他网络的权重分别设置为零来创建过滤器掩码(中)。然后将每个网络的输出连接起来,形成一个大网络,其输入和输出数量是原来的三倍(右)。
训练:所有的网络都是端对端的训练,给定图像作为输入,真实值(光流,视差或场景流)作为输出。我们使用一个自定义版本Caffe并使用Adam优化器。使用Kingma等人设置β1=0.9和β2=0.99。由于我们使用的学习率λ=1e-4,从第400k迭代开始每迭代200k次学习率除以2。
由于网络的深度以及收缩和扩展层之间的直接连接(见表2),如果所有的6个损失都是有效的,则较低层会得到混合梯度。我们发现,使用损失权重方案可能是有好处的:我们开始进行训练,将最低分辨率的损失loss6的权重设置为1,其他所有的损失权重设置为0(即其他所有损失均被关闭)。训练期间,我们逐步提高更高的分辨率的损失权重,并取消低分辨率损失。这让网络首先能够学习一个粗糙的表示,然后继续学习更精细分辨率的表示,而没有因为限制中间部分的特征造成损失。
数据增强:尽管有大量的训练集,我们仍选择进行数据增强,以几乎不增加额外成本的方式将更多的图片多样性加入训练数据(计算的瓶颈在于从磁盘读取训练样本,而增强数据是动态执行的)。我们进行空间变换(旋转,平移,裁剪,缩放)和彩色变换(颜色,对比度,亮度),并对所有2或4个输入图像使用相同的变换。
对于视差,任何旋转或垂直移动将打破极线约束。立体图像间的水平移位还将导致负视差。
6. 实验
现有方法的评估。我们在新的数据集上评估了几种现有的视差估计方法。就视差而言,我们在OpenCV中评估了Zbontar和LeCun的最先进的方法以及具有块匹配实施的流行的半全局匹配方法。在表3中展示了以上方法和DispNets的结果。在大多数情况下,我们使用端点误差(EPE)作为误差度量,唯一的例外是KITTI 2015测试集,其中KITTI评估服务器仅公布了D1-all误差测量(估计误差大于3px且真实视差大于5%的像素的百分比)。

表3.视差误差。所有测量都是端点误差,除了KITTI-2015测试的D1-all度量(解释见文本)。这个结果来自在KITTI 2012上进行训练的微调网络。
DispNet。我们在FlyingThings3D数据集上训练DispNets,然后视需要在KITTI上进行微调。微调的网络在表中由“-K”后缀表示。在提交时,在KITTI 2015上微调的DispNetCorr在KITTI 2015排行中排名第二,略低于MC-CNN-acrt,但速度大约快1000倍。在KITTI分辨率下,它在Nvidia GTX Titan X GPU上以每秒15帧的速度运行。对于前景像素(属于汽车模型),我们的误差大约是[27]的一半。该网络实现的误差比表中报告的最佳实时方法Multi-BlockMatching低30%。同样在其他数据集上,DispNet表现很好,并且胜过SGM和MC-CNN。
虽然在KITTI上的微调改善了在这个数据集上的结果,但是增加了在其他数据集上的误差。我们解释性能显着下降的原因,是由于KITTI 2015只包含相对较小的视差,约150像素,而其他数据集包含500像素或更多的视差。在KITTI上进行微调时,网络似乎失去了预测大位移的能力,因此造成了在其他数据集上巨大的误差。
与FlowNet相比,我们对网络结构进行了一些修改。首先,我们在网络扩展部分的上卷积层之间添加了卷积层。正如预期的那样,网络可以更好地正则化视差图并预测更平滑的结果,如图6所示。结果是,在KITTI 2015上相比较EPE降低了大约15%。
其次,我们用1D相关层训练了一个我们网络的版本。与Dosovitskiy等人提出的网络相比,我们发现在许多情况下,具有相关层的网络表现更好(见表3)。一个可能的合理解释是,视差估计问题的1D特性让我们在比FlowNet更精细的网格上计算相关。
SceneFlowNet。如第5节所述,为了构建一个SceneFlowNet,我们首先训练一个FlowNet和一个DispNet,然后将它们结合起来并训练,如图5所述。表4显示了初始网络和SceneFlowNet的结果。表5展示了我们的数据集的最后结果,图8显示了一个来自FlyingThings3D的定性例子。

表4.在FlyingThings3D上训练和测试的解决单个任务与解决联合场景流任务的性能比较。FlowNet最初训练1.2M次,DispNet迭代1.4M,+500k表示多训练500k。SceneFlowNet使用FlowNet和DispNet进行初始化。解决联合任务会在每个单独的任务中产生更好的结果。

表5.在现有的数据集上评估SceneFlowNet的端点误差。驾驶数据集包含最大的视差,光流和视差变化,导致了较大的误差。FlyingThings3D数据集包含较大的光流,而Monkaa包含较小的光流和较大的视差。
尽管FlyingThings3D数据集比FlyingChairs数据集更复杂,但在该数据集上进行训练并没有产生比在FlyingChairs上进行训练更好的FlowNet。尽管事实是FlyingThings3D与FlyingChairs相比,提供了训练网络的视差和场景流估计的可能性,但我们正在研究如何用3D数据集提高FlowNet的性能。
7. 结论
我们首次提出了一个包含超过35000个立体图像对的综合数据集,其中包含视差,光流和场景流的真实值。虽然我们的动机是创建一个适合于训练卷积网络来估计这些量的足够大的数据集,但是该数据集也可以用于其他方法的评估。对于缺乏具有真实值的数据集的场景流,这是非常有吸引力的。
我们已经证明,数据集确实可以用来成功地训练大型卷积网络:我们训练的用于视差估计的网络与现有技术水平相当,并且运行速度提高了1000倍。 第一次使用标准网络结构来训练网络以进行场景流估计的方法也显示出有希望的结果。我们相信,我们的数据集将有助于提高深度学习研究例如立体匹配、光流和场景流估计这样的具有挑战性的视觉任务。