python爬取去哪儿网酒店信息
python爬取去哪儿网酒店信息
利用selenium+python爬取去哪儿网酒店信息,获取酒店名称、酒店地址、第一条评论、评论数、最低价格等信息,写入excel表。
1、观察网页结构
浏览器地址栏输入https://hotel.qunar.com/city/xiamen/#fromDate=2020-01-01&cityurl=xiamen&toDate=2020-01-02&from=qunarHotel进入去哪儿网主页面,如下图:
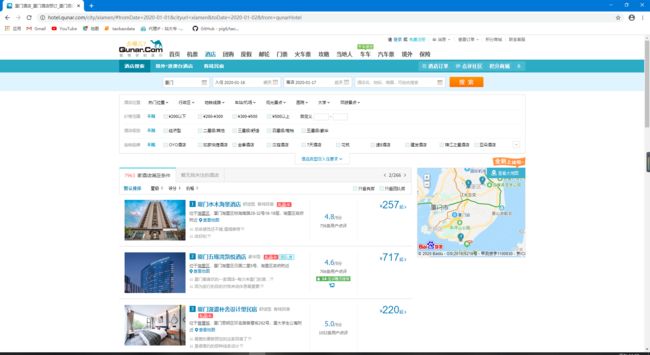
右键点击网页查看源代码,观察结构,发现所要获取信息并未直接写在网页源码中,而是以Json的形式进行动态交互的,所需要信息封装在class='b_hlistPanel~之中。

2、爬取信息
# -*- coding:utf-8 -*-
import time
import pandas as pd
from selenium import webdriver
from bs4 import BeautifulSoup
# 创建EXCEL文件地址
EXCEL_PATH = '酒店信息.xlsx'
all_lists = []
number = 1
path = r'C:\chromedriver'
driver = webdriver.Chrome(executable_path=path)
url = "https://hotel.qunar.com/city/xiamen/#fromDate=2020-01-01&cityurl=xiamen&toDate=2020-01-02&from=qunarHotel"
driver.get(url)
time.sleep(5)
for z in range(0, 10): # 爬取页数设置
for i in range(5):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 自动下拉网页
time.sleep(3)
page = driver.page_source
html = BeautifulSoup(page, 'html.parser') # 从网页提取数据
lists = html.find('div', class_='b_hlistPanel')
for list in lists:
name = list.find('a', class_='e_title js_list_name').get_text()
address = list.find('span', class_='area_contair').get_text()
comment = list.find('p', class_='review first_review').get_text()
grade = list.find('p', class_='score').find('b').get_text()
amount = list.find('p', class_='user_comment').find('cite').get_text()
lowestprice = list.find('p', class_='item_price js_hasprice').find('b').get_text()
goods = {'序号': number,
'酒店名称':name,
'地址':address,
'评价':comment,
'点评数':amount,
'价格':lowestprice}
number += 1
all_lists.append(goods)
df = pd.DataFrame(all_lists)
writer = pd.ExcelWriter(EXCEL_PATH)
df.to_excel(excel_writer=writer, columns=['序号', '酒店名称', '地址', '评价', '点评数', '价格'], index=False,
encoding='utf-8', sheet_name='Sheet')
writer.save()
writer.close()
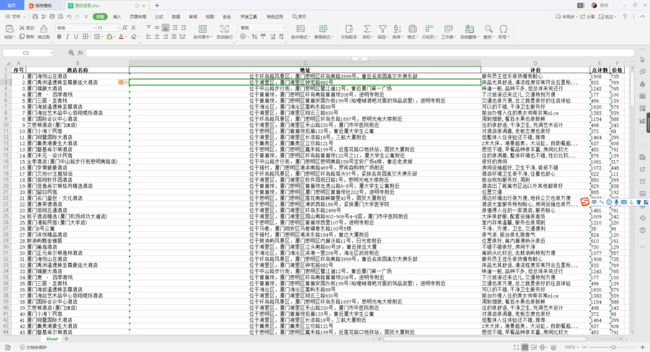
~3、结果如下图
欢迎查看我的其他博客点击这里