多卡训练DataParallel和DistributedDataParallel的使用和区别
目录
简介
DP和DDP的区别
DP的使用
DDP的使用
spawn启动一个进程占一张卡
launch启动一个进程占一张卡
单个进程占用多张卡
分布式的参数
注意事项
参考资料
简介
在使用pytorch训练网络时,一般都会使用多GPU进行并行训练,以提高训练速度,一般有单机单卡,单机多卡,多机多卡等训练方式。这就会使用到pytorch提供的DataParallel(DP)和DistributedDataParallel(DDP)这两个函数来实现。
DP和DDP的区别
DP是使用一个进程来计算模型参数,然后在每个批处理的数据将分发到每个GPU,然后每个GPU计算各自的梯度,然后汇总到GPU0中进行求平均,由GPU0进行反向传播更新参数,然后再把模型的参数由GPU0传播给其他的GPU,GPU利用率通常很低。
DDP是数据并行的分布式,是同时使用多个进程,每个GPU上一个进程,数据也是被进程数等分,相当于每个GPU上都跑了一份代码,前向之后再经过allreduce的处理,再经过梯度反向传播,更新参数。大概如下图所示


DDP即可以做单机多卡,也可以多机多卡,但DP只能是单机多卡,DDP即支持一个进程占一张GPU,也支持一个进程上占多张GPU,而DP只支持一个进程占一个或多个GPU。可以说DDP是支持DP的所有功能的。
DP的使用
DataParallel更易于使用,只需简单包装单GPU模型,DP的batchsize是每张GPU上的数目乘GPU数目,这个和DDP是不一样的。
model = MODEL() # 创建模型,需修改
model = model.cuda()
num_gpus = torch.cuda.device_count()
if num_gpus > 1:
logger.info('use {} gpus!'.format(num_gpus))
model = nn.DataParallel(model)通过watch nvidia-smi查看GPU信息,可以看到使用的每张GPU的PID是一样的,如果是4张卡,4个GPU的PID都是一样的。
DDP的使用
DDP的使用,相对来说要复杂一些,启动方式也有多种,包括用torch.multiprocessing.spawn,也可以用launch启动。
spawn启动一个进程占一张卡
实现多机的一个进程占用一张卡的使用,需要注意的位置:
1. dist.init_process_group里面的rank需要根据node以及GPU的数量计算;
2. world_size的大小=节点数 x GPU 数量
3. ddp 里面的device_ids需要指定对应显卡
参考伪代码main.py
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
import argparse
def example(local_rank, node_rank, local_size, world_size):
# 初始化
rank = local_rank + node_rank * local_size
torch.cuda.set_device(local_rank)
dist.init_process_group("nccl",
init_method="tcp://{}:{}".format(args.master_addr, args.master_port),
#init_method="tcp://localhost:22355",
rank=rank,
world_size=world_size)
# 创建模型
model = MODEL() # 创建模型,需修改
model = model.cuda()
num_gpus = torch.cuda.device_count()
if num_gpus > 1:
logger.info('use {} gpus!'.format(num_gpus))
model = nn.parallel.DistributedDataParallel(model, device_ids=[local_rank],
output_device=local_rank)
loss_fn = nn.MSELoss() # loss函数
optimizer = optim.SGD(ddp_model.parameters(), lr=0.0001) # 优化器
# 定义数据集
train_datasets = ... # 自己定义的Dataset子类,需修改
train_sampler = DistributedSampler(train_datasets)
# 使用了sampler,shuffle不能为true,
train_dataloader = DataLoader(train_datasets, sampler=train_sampler, batch_size=args.train_batch_size,
num_workers=args.num_workers, pin_memory=True)
# 进行前向后向计算
for epoch in args.epochs:
# 步骤五:打乱顺序,相当于shuffle=TRUE
train_sampler.set_epoch(epoch)
for batch in train_dataloader:
input, label = batch[:2]
input = input.cuda()
label = label.cuda()
optimizer.zero_grad()
output = model(input)
loss = loss_fn(label, output)
loss.backward()
optimizer.step()
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--world_size", type=int)
parser.add_argument("--node_rank", type=int)
parser.add_argument("--master_addr", default="127.0.0.1", type=str)
parser.add_argument("--master_port", default="12355", type=str)
args = parser.parse_args()
local_size = torch.cuda.device_count()
print("local_size: %s" % local_size)
mp.spawn(example,
args=(args.node_rank, local_size, args.world_size,),
nprocs=local_size,
join=True)
if __name__=="__main__":
main()这里虽然没有定义local_rank这个变量,但不会有错,应该是spawn函数带了这个参数, 单机多卡下,local_rank基本上就是0,1,2,3等等。代码基本上就是被复制了多份,通过watch nvidia-smi查看GPU信息,可以看到使用的每张GPU的PID是不一样的。
启动命令,如果是单机多卡,使用4卡,服务器的IP地址为192.168.0.1 占用的端口22335,命令如下:
CUDA_VISIBLE_DEVICES=0,1,2,3 python main.py --world_size=4 --node_rank=0 --master_addr="192.168.0.1" --master_port=22335如果是多机多卡,2个机器,每个机器8张卡,命令如下(我只使用过单机多卡,没使用过多机多卡,命令没有经过验证 ):
# 节点1
python main.py --world_size=8 --node_rank=0 --master_addr="192.168.0.1" --master_port=22335
# 节点2
python main.py --world_size=8 --node_rank=1 --master_addr="192.168.0.1" --master_port=22335launch启动一个进程占一张卡
用launch方式需要注意的位置:
需要添加一个解析 local_rank的参数:
parser.add_argument("--local_rank", type=int)
dist初始化的方式 int_method取env:
dist.init_process_group("gloo", init_method='env://')
DDP的设备都需要指定local_rank
net = torch.nn.parallel.DistributedDataParallel(net, device_ids=[args.local_rank], output_device=args.local_rank)
参考伪代码,main.py
import argparse
import torch
from torch.utils.data import DataLoader, Dataset
from torch.utils.data.distributed import DistributedSampler
import torch.nn as nn
import torch.optim as optim
def main():
# 步骤一:定义local_rank
parser = argparse.ArgumentParser()
...
parser.add_argument("--local_rank", default=os.getenv('LOCAL_RANK', -1), type=int)
parser.add_argument("--train_batch_size", default=1, type=int) # 此次的batchsize是每个进程上的数目,不是总数目
parser.add_argument("--num_workers", default=1, type=int)
parser.add_argument("--epochs", default=1000, type=int)
args = parser.parse_args()
# 步骤二:初始化
if args.local_rank != -1:
torch.cuda.set_device(args.local_rank)
device = torch.device("cuda", args.local_rank)
torch.distributed.init_process_group(backend="nccl", init_method='env://')
# 步骤三:模型分布式处理
model = MODEL() # 创建模型,需修改
loss_fn = nn.MSELoss() # loss函数
optimizer = optim.SGD(ddp_model.parameters(), lr=0.0001) # 优化器
#记住要先放在device上再进行DistributedDataParallel,DistributedDataParallel需带参数device_ids和output_device
model.to(device)
num_gpus = torch.cuda.device_count()
if num_gpus > 1:
logger.info('use {} gpus!'.format(num_gpus))
model = nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank],
output_device=args.local_rank)
# 步骤四:定义数据集
train_datasets = ... # 自己定义的Dataset子类,需修改
train_sampler = DistributedSampler(train_datasets)
# 使用了sampler,shuffle不能为true,
train_dataloader = DataLoader(train_datasets, sampler=train_sampler, batch_size=args.train_batch_size,
num_workers=args.num_workers, pin_memory=True)
# 进行前向后向计算
for epoch in args.epochs:
# 步骤五:打乱顺序,相当于shuffle=TRUE
train_sampler.set_epoch(epoch)
for batch in train_dataloader:
input, label = batch[:2]
input = input.cuda()
label = label.cuda()
optimizer.zero_grad()
output = model(input)
loss = loss_fn(label, output)
loss.backward()
optimizer.step()
if __name__ == "__main__":
main()启动命令以单机3卡为例,需要多输入2个参数,其中nproc_per_node为GPU的数目,通过watch nvidia-smi查看GPU信息,可以看到使用的每张GPU的PID是不一样的。
CUDA_VISIBLE_DEVICES=0,1,2 python -m torch.distributed.launch --nproc_per_node=3 main.py需要注意的是,这两种模式下,设置batchsize时,是每张卡上的数目,这个和DP是有差异的。另外数据集要使用sampler参数,这时shuffle就不能设置为true,需要通过 train_sampler.set_epoch(epoch)来实现shuffle的功能。
单个进程占用多张卡
单进程占多张卡的代码和启动方式,代码中需要注意的位置:
1. dist.init_process_group里面的rank等于节点编号;
2. world_size等于节点的总数量,不是GPU的数目;
3. DDP不需要指定device。
参考伪代码main.py
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
import argparse
def main(rank, world_size):
# 初始化
dist.init_process_group("gloo",
init_method="tcp://{}:{}".format(args.master_addr, args.master_port),
#init_method="tcp://localhost:22355",
rank=rank,
world_size=world_size)
# 创建模型
model = MODEL() # 创建模型,需修改
model = model.cuda()
num_gpus = torch.cuda.device_count()
if num_gpus > 1:
logger.info('use {} gpus!'.format(num_gpus))
model = nn.parallel.DistributedDataParallel(model)
loss_fn = nn.MSELoss() # loss函数
optimizer = optim.SGD(ddp_model.parameters(), lr=0.0001) # 优化器
# 步骤四:定义数据集
train_datasets = ... # 自己定义的Dataset子类,需修改
train_sampler = DistributedSampler(train_datasets)
# 使用了sampler,shuffle不能为true,
train_dataloader = DataLoader(train_datasets, sampler=train_sampler, batch_size=args.train_batch_size,
num_workers=args.num_workers, pin_memory=True)
# 进行前向后向计算
for epoch in args.epochs:
# 步骤五:打乱顺序,相当于shuffle=TRUE
train_sampler.set_epoch(epoch)
for batch in train_dataloader:
input, label = batch[:2]
input = input.cuda()
label = label.cuda()
optimizer.zero_grad()
output = model(input)
loss = loss_fn(label, output)
loss.backward()
optimizer.step()
if __name__=="__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--rank", default=0, type=int)
parser.add_argument("--world_size", default=1, type=int)
parser.add_argument("--master_addr", default="127.0.0.1", type=str)
parser.add_argument("--master_port", default="12355", type=str)
args = parser.parse_args()
main(args.rank, args.world_size)启动命令,以单机三卡为例,因为是单机,只有一个节点,所以world_size应该为1。
CUDA_VISIBLE_DEVICES=0,1,2 python main.py --world_size=1 --rank=0 --master_addr="192.168.0.1" --master_port=22335需要注意的时,这种情况下,batchsize是单卡的数目乘每张卡上的图像数,和DP类似,和DDP不一样, 通过watch nvidia-smi查看GPU信息,可以看到使用的每张GPU的PID是一样的。
分布式的参数
rank、local_rank、node等的概念
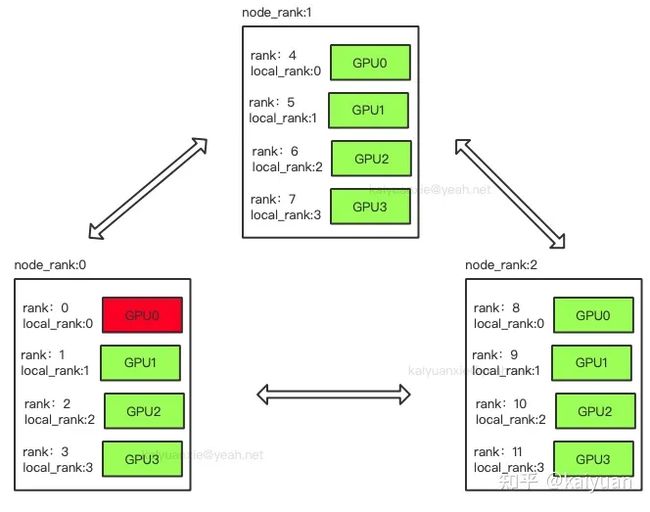
rank:用于表示进程的编号/序号(在一些结构图中rank指的是软节点,rank可以看成一个计算单位),每一个进程对应了一个rank的进程,整个分布式由许多rank完成。
node:物理节点,可以是一台机器也可以是一个容器,节点内部可以有多个GPU。
rank与local_rank: rank是指在整个分布式任务中进程的序号;local_rank是指在一个node上进程的相对序号,local_rank在node之间相互独立。
nnodes、node_rank与nproc_per_node: nnodes是指物理节点数量,node_rank是物理节点的序号;nproc_per_node是指每个物理节点上面进程的数量。
word size : 全局(一个分布式任务)中,rank的数量。
Group:进程组,一个分布式任务对应了一个进程组。只有用户需要创立多个进程组时才会用到group来管理,默认情况下只有一个group。
下图中一共有12个rank,nproc_per_node=4,nnodes=3,每个节点都一个对应的node_rank。
注意事项
使用DDP时,保存模型或者打印log时,如果不加限制,是会有多份的,为了保证只存一份模型,可以用rank来指定一个进程保存。
if torch.distributed.get_rank() == 0: #一般用0,当然,可以选任意的rank保存。
torch.save(net, "net.pth")加载模型不同于保存,可以让每个进程独立的加载,也可以让某个rank加载后然后进行广播。值得注意的是,当模型大的情况下,独立加载最好将模型映射到cpu上,不然容易出现加载模型的OOM。
torch.load(model_path, map_location='cpu')如果出现端口被占用的情况,可以换个端口,或者杀死原来的端口,通过以下命令可以查看端口
fuser -v /dev/nvidia*通过如下命令可以杀死端口
kill -9 2885448(端口号)参考资料
DataParallel 和 DistributedDataParallel 的区别和使用方法_Golden-sun的博客-CSDN博客_dataparallel
解决GPU显存未释放问题 - 臭咸鱼 - 博客园
PyTorch分布式训练基础--DDP使用 - 知乎
关于DistributedDataParallel的简单详细步骤以及踩坑总结 - 知乎
关于DDP的使用,还有些没有弄明白,以后用到时再进一步学习,中途如果有错误的地方,欢迎批评指正。