【学习打卡】ZFNet深度学习图像分类算法
文章目录
-
-
- 引言
-
- 可以学到什么
- 为什么叫ZFNet
- ZFNet的网络结构简介
- 方法:可视化反卷积
-
- 反池化
- 反激活
- 反卷积
- 训练细节
-
- 大小裁剪
- 层可视化
-
- 特征可视化
-
- 第 1 层
- 第 2 层
-
- 两边的对应关系
- 更深的层
-
- 第 3 层
- 第 4 层
- 第 5 层
- 特征演化
- 特征不变性
-
- 实验简介
- 图的分析
- 模型改进:AlexNet
- 局部遮挡测试
-
- 敏感性分析
- 相关性分析
- 实验
-
- 多种版本
- 特征泛化性
-
- 去除某些层
- 迁移学习
-
- Caltech-101数据集:
- Caltech-256数据集:
- PASCAL数据集(二分类)
- 有效性
- 总结
-
引言
- 纽约大学ZFNet,2013年ImageNet图像分类竞赛冠军模型。对AlexNet进行改进的基础上,提出了一系列可视化卷积神经网络中间层特征的方法,并巧妙设置了对照消融实验,从各个角度分析卷积神经网络各层提取的特征及对变换的敏感性
- 论文:Visualizing and Understanding Convolutional Networks(可视化并理解卷基神经网络)
- 该课程由B站同济子豪兄主讲
- 课程主页:https://www.bilibili.com/video/BV17b4y1m7x8?p=1&vd_source=2c3e1c3086544e2bbc96712d9fb90632
可以学到什么
在这篇论文中,它提出了一种非常巧妙的可视化卷积神经网络中间层特征的方法和技巧,使用该技巧,可以打破卷积神经网络黑箱子
- 知道中间每一个神经元到底是在提取什么样的特征
- 利用这些可视化的技巧和利用这些特征,可以改进之前的网络
为什么叫ZFNet
两个作者的首字母分别为Z和F
下图为Zeiler 在YouTube上有一个讲解ZFNet的视频

ZFNet的网络结构简介
在AlexNet的基础上进行了一些修改:
- 卷积核:11×11 -> 7x7
- 步长:4 -> 2
- 后边的卷积层增加了卷积核的个数

方法:可视化反卷积
下图(右部分是正向的卷积)是可视化卷积神经网间层特征的一个反卷积的技巧
想可视化中间这一个卷积层的特征,是把该卷积层逆向重构回原始输入的像素空间
-
原来正向的话,需要经过卷积、激活、池化等等操作,我们把这三个操作反回去
-
反池化、反激活、反卷积,给他重构回原始输入的像素空间,变成我们人类能够看懂的特征
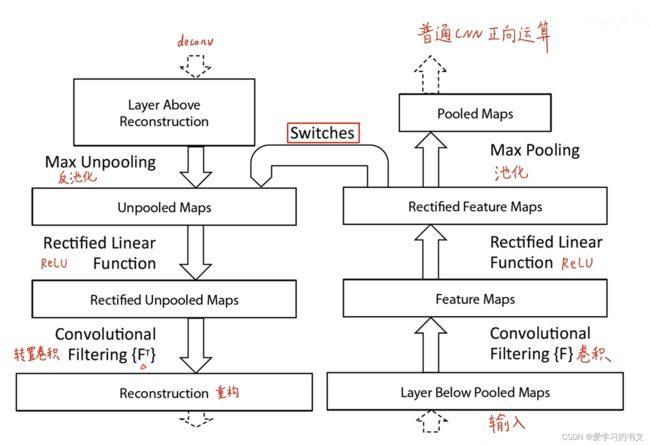
反池化
正向池化,以最大池化为例,是把每一个池化窗口里面最大的这个值挑出来
那如何把这个过程反过来重构回去呢?
就是在正向池化的过程中,记录每一个最大值所在的位置。
反池化的时候,就把每一个池化窗口按照对应的位置派遣回去
举例子
正向池化,是从每个村挑出最聪明的一个人。在挑出来的时候,就要记录每个人他所在的村,反过来的时候,我们要把每一个聪明人派回他原来所在的村里去
反激活
仍然使用ReLU激活函数
反卷积
使用的是原来正向卷积核的转置(也就是行列互换)
- 转置卷积没有需要学习的参数,是一个完全无监督的过程。
训练细节
大小裁剪
- 如果不进行大小裁剪,卷积核中会有一些卷积核特别的大。
- 所以需要对过大的卷积核进行裁剪,把它限定在一个大小范围内。
层可视化
特征可视化
第 1 层
通过该技巧能把卷积神经网络中间层的某一个feature map的特征,重构回原始输入的像素空间,效果如下图:
- 上面是第 1 层卷积核
- 下面是使得上面这9个卷积核激活最大的数据集中已经存在的原图patch
- 左上角这9个图, 是使第 1 层第一个卷积核最大激活的的前9个原始的小图小patch
- 第1个卷积核是提取的是从左上角往右下角的对角线特征/边缘特征
- 第8个卷积核提取的是绿色的特征
- 总结:第 1 层,提取的特征非常的底层:就是边缘颜色这样的特征
第 2 层
开始使用我们提到的反卷积的技巧。
-
首先从第 2 层中选出16个卷积核(左边),找到原图中能够使得这16个卷积核最大激活的图片(每一个卷积核9张图)
能够使得它最大激活的图片是从原始数据中挑出来的,比如说右图第二个数值条纹的图片能够使得左图第二个激活最大
-
然后呢,我们把这 9 张图片传到第 2 层的feature map,使用反卷积的技巧重构回原始输入的像素空间。就变成了这个灰色的左图
举例说明:
- 第2个卷积核其实就在提取数字条纹特征
- 第5个卷积核在提取晚霞色的特征
- 第8个卷积核在提取1/4圆的这个右下角的圆环+同心圆的特征
- 第14个卷积核在提取金黄色的特征
- 第16个卷积核是在提取这样的直角的特征
总结:第 2 层比第 1 层的特征要高级一些,但是仍然是比较底层的特征。
两边的对应关系
-
真正右边的这些彩色图,是数据中真实存在的小图
-
灰色的这个图呢,是把这九张喂图未到网络里面,把第 2 层对应的feature map用反卷积技巧重构回原始输入像素空间得到的图。
每一张图其实是对应的,它们其实是很像的,左图上的光亮和色彩体现了它捕获到的模式和特征。例如,第二个卷积核提取到的是数值条纹特征。
更深的层
到了第 3 层和第 4 层,第 5 层,这些提取的特征就越来越高级
第 3 层
步骤:
-
从第 3 层网络中挑出 12 个卷积核,分别找到使这 12 个卷积核激活最大的原始输入像素,即原始数据集中的图片。
- 每一个卷积核,我们找到 9 张能够使得它输入最大的图片
-
把这 9 张图片喂到网络里
-
把第 3 层的这个卷积核生成的feature map用反卷积的技巧重构回原始输入像素空间,得到了左边的灰图
举例:
- 第 1 个提取的是网格信息
- 第 6 个提取的是车轱辘的信息
- 第 8 个提取的是文字和条形码的信息。
- 第 10 个提取的是橘黄色圆形物体的信息
- 第 11 个提取的是人脸人身和人脸的信息
根据卷积核和feature map -> 反映模式和特征 -> 得到黑匣子中间是什么样的原理
第 4 层
10个卷积核
-
第 1 个:狗脸(狗的眼睛和鼻子的信息)
-
第 4 个:圆圈,螺旋型的信息特征
-
第 8 个:鸟腿
第 5 层
特征非常的高级和复杂
例子:花瓣、狗、眼睛
重要特点:
-
浅层的一组9个图片非常想像
-
第 5 层如第二个,特征变得高级,特化和复杂,具备一定的Invariance 不变性(9 张图片他们都是能够使得第 5 层这个feature map激活最大的原始数据中的九张图片,但是这九张图片长的是不太一样的)
-
第 5 层随着网络变身,他越来越提取这个sematic的语义特征,而不是在提取长宽方向上的special的信息。
第 5 层第二个卷积核:提取草地的背景特征,而不是人、马和狗这样的前景特征。 -> 说明网络越到高级、层数越深,提取的特征就越特化,高级和不变,越来越倾向于提取语义特征。
特征演化
训练过程中不同层的卷积核的特征演化的过程
图(之前的灰色图)的解释
第 1 层、第 2 层、第 3 层、第 4 层和第 5 层的五层的六个卷积核
- 每一行表示一个卷积核
- 每一列表示训练过程中不同的轮次:第 1 轮、第 2 轮、第5轮、第10轮、第20轮、第30轮、第40轮和第64轮
- 收敛
- 那底层的卷积核,很快就收敛了
- 高层的卷积核,它要多轮之后才能收敛
- 突变:能够使卷积核最大激活的图片变了
- 第三组第三个:提取眼睛信息;第四个:提取脸的信息
特征不变性
研究对原图进行平移、缩放和旋转,会对网络的不同层的
feature vector即不同层提取的信息)以及对最后的输出结果有什么样的影响。
实验简介
实验对象:
割草机、西施犬、非洲鳄鱼、非洲鹦鹉和娱乐中心
不同程度的变换
- 不同像素的数值平移
- 不同尺度的缩放
- 不同角度的旋转
feature vector:feature map拉平成的向量
- 计算变换之后的
feature vector和原图的feature vector他们的欧式距离。
图的分析
第一列 -> 第 1 层卷积核
- 1-1图:稍微平移一点点像素 -> 欧式距急剧的增大
- 2-1图:稍微扩大一点点的缩放倍数 -> 第 1 层的
feature vector的欧式距急剧的增大 - 3-1图:稍微旋转一点点的角度,那么提取的
feature vector的欧式距离也会迅速的增大
表明对于网络的底层来说,稍微进行一点点的变换会对网络的这个中间提取的结果底层的结果造成很大的影响。
第二列 -> 第 7 层卷积核
- 倾向于线性变化,而不是急剧变换
- 说明变换对于网络的深层而言是影响比较小的。
- 侧面说明网络浅层在关注长宽方向上的special信息。而深层是在关注semantic的语义信息
第三列
表示变换之后,对正确类别的影响/概率的影响/对网络最后的识别结果的影响
看图中的线,标注
3 - 1平移
-
深蓝紫 - 除草机:随着除草机进入和移出视野,它的概率先升高后变得很低。
-
深蓝色 - 吸食犬:随着吸食犬不断露出身体,它的概率也会变高
3 - 2缩放
- 娱乐中心对缩放非常敏感
- 除草机和鹦鹉,在图像中始终出现,所以缩放对它们的影响是不大的。
3-3旋转
每旋转90度,就有一个尖峰,准确率就会出现一个峰值,说明它每旋转90度就出现了一个对称性,网络能捕获同样的特征
模型改进:AlexNet
对AlexNet第 1 层的卷积核进行可视化,发现其中有一些灰暗的/失效的卷积核(1-2图)
修改步长:4 -> 2;卷积核大小:11x11改到7x7
生成了这个ZFNet的第 1 层,失效的卷积核少多了(2-2图)
-
1-3 图是AlexNet的第 2 层卷积核的,因为步长过大,出现网格样式的卷积核(特殊的黑和白那两个),这些卷积核是不太健康,不太良好的卷机盒,它是提取不出什么有价值信息的。
-
1 - 4图是ZFNet的第 2 层卷积核,修改步长和卷积核大小,就能够改善这样的情况,可视化结果中没有混乱的网格的情况
局部遮挡测试
敏感性分析
用一个小灰方块在图像上进行遮挡来分析这个遮挡。网络最后的结果对这个遮挡的敏感性
第四列-博美犬举例:
把这个灰色挡板遮在图像中的不同地方,然后1-4图就体现网络能够识别出博美犬的概率。
- 灰色挡板移在跟狗无关的其他地方的时候,是红色,表示它仍然能够识别出是博美犬,而且博美犬的概率很高。
- 把灰色挡板挡在这个狗脸上的时候,概率变得很低,说明网络是非常关注狗脸这一块,把这部分挡住的话,网络就无法正确的识别了
对于3-1,如果把人脸挡住,反而能帮助这个网络更确信它是阿富汗猎犬。因为人在这个图中实际上是一个干扰,如果我们把人人脸挡住的话,你看它是变成红色的,就说明网络能够对这个猎犬的置信度是更高的
对于最后一列,表示是当前识别最高的类别
第三列
- 黑框中代表原始图像的最大激活
- 狗:狗脸
- 车:文字
- 猎犬:人脸
- 其他三框代表数据集中其他能使feature map激活最大的图像对应的反卷积
- 狗:毛茸茸
- 车:文字
- 猎犬:人脸
第二列
遍历遮挡,每次记录第 5 层激活最大的feature map的值叠加,形成的热力图
第一行,毛茸茸和狗脸被遮挡都会降低,其他同理
结论:通过一系列特别巧妙的对照实验表明了这个神经网络对遮挡的敏感性
注意
- feature map保留了空间信息,左上角和原图左上角信息相对应
- 以第三行的为例,激活最大的feature map不一定是对分类最有用的特征(识别猎犬但是激活最大的是人脸)
- 卷积核是人,但是最后结果不是人是因为数据集中没有人脸这个类别
相关性分析
五张不太一样狗的图片,探究深度学习是否对狗这类别进行了语义上的定义,分析不同狗的图片遮挡同一个部位,在不同图片上的影响是是否是一样
如果完全不同的狗,遮住右眼后,对这些狗的网络的影响是一样的,就说明深度学习隐式的定义了右眼这个位置。
影响的数值化:遮挡后的feature vector与遮挡前的差
根据表中的结果
- 遮特定的部位,前后差比较小,说明同一个部位对这些不同狗的图片的影响是相同的,是接近的
- 随机乱遮
- 第 5 层影响较大,第 7 层影响较小
- 再次证明:网络越到深层,他提越提取的是语义特征
实验
消融实验:冰川的水化掉了,主要矛盾凸显出来,就是对比试验
多种版本
测试:2012年的图像分类数据
- a模型是原始ZFNet模型
- b模型在a基础上,把3、4、5层卷积核增加到512、1024和512
- 将6个模型集成在一起,效果不错,超过AlexNet,模型错误率是亚军的一半
特征泛化性
去除某些层
- 去除这个两个卷积层,影响不是特别大
- 去掉全连接层,影响也不是特别大
- 既去掉卷积层又去掉全连接层,影响非常大
所以说明网络的深度非常重要的
把全连接层的神经元的个数调得非常大,会造成过参数量爆炸,训练集上的误差非常小,但是在验证集上的误差也不见得小到哪去,出现了过拟合
3、4、5卷积层的卷积和个数调调高,改成512、1024和512,即b模型是最好的模型
迁移学习
除了ImageNet,是否能够泛化到其他的数据集上,进行一个迁移,学习和微调
Caltech-101数据集:
- 保留这个模型之前的部分,只改动这个最后的softmax分类层。然后在Caltech-101上重新训练我们新加的softmax分类层。效果是非常不错的,是比原有的模型效果要好很多的
- 只保留网络的结构。不要原来的参数完全随机初始化,然后再开后,他给101数据上重新训练这个网络,我们会发现效果是不太好的
说明了迁移学习是非常棒的一个技巧,可以把ImageNet上训练好的模型来泛化到其他的数据集上,站在巨人的肩膀上来构建人工智能的模型。
Caltech-256数据集:
是一样。
特别的结论:
- 在Caltech-256,只需要每一个类别只用六张图片训练。训练好处的模型就能够达到原来最佳的这个数据上模型的精度。
- 也就是说,如果使用迁移学习的话,我们可以使用很少量的数据就可以达到非常好的性能。
- 那如果我们使用了很大量的数据的话,那性能就会更好
PASCAL数据集(二分类)
之前结论行不通,因为它和ImageNet数据集长得有点不太一样
- ImageNet一张图片里面只有一个物体
- PASCAL一个图片中可以有很多个物体
结论:对于数据集不太像的场景,直接照搬原来的技迁移学习,效果是比不了这个PASCAL当年最佳的模型的,就因为这个数据集有差异。
解决:如果针对PASCAL情况,修改一下损失函数,对这个网络进行更精精细的调节,让他适应PASCAL也是可以的。
实验结果:我们的模型是要比a算法都要好的,但是比有一些比不上b算法
有效性
网络中不同的层提取的特征对分类的有效性
问:把不同层的feature vector取出来,然后在后面加一个支持限量机分类模型或者是softmax分类模型,来分析不同层的提取出的特征对最终的分类是否有效?
答:越深的层,他提取的信息对分类是越有效的。而且不管是用softmax还是用知识向量机,都能够起到一个分类的作用。
全连阶层是一个线性的分类器
不管是使用全连接层也好。使用知识向量机也好,都是能够起到对高维向量进行分类的作用,而且模型越深,这个向量越具有分类的有效性(discriminative information)
总结
本次学习了ZFNet,它是在AlexNet之后新的改进,它主要提出了一种反卷积的思想,反卷积的可视化有助于人们理解卷积神经网络每一层提取到的信息是什么,有助于增加人们对神经网络这个黑盒做了什么的理解。
反卷积过程主要是正常卷积过程的卷积、激活和池化过程反过来,然后对于每一层的卷积核,找到使它最大激活的9张图片,对图片重构得到可视化结果,得到最重要的结论是浅层网络提取的是基础的special信息,深层网络能提取到语义信息。
通过特征演化,可以看到高层语义需要更多次的训练才能收敛;通过特征不变性,可以看到利用平移、旋转和缩放对结果的影响;还进行了遮挡测试,可以发现神经网络确实是有隐式地提取眼睛这样地信息。
通过实验,可以知道通过训练好的结果进行迁移学习能获得不错的结果。