机器学习必会技能之微积分【一文到底】
机器学习必会技能 —— 微积分【一文到底】
文章目录
-
-
- 机器学习必会技能 —— 微积分【一文到底】
-
- 1 微积分的四类问题
- 2 深入理解导数的本质
- 3 深入理解复合函数求导
- 4 理解多元函数偏导
- 5 梯度究竟是什么?
- 6 真正理解微积分
-
- 6.1 直观理解
- 6.2 理解微积分基本定理
- 7 非常重要的泰勒公式
-
- 7.1 泰勒的典型应用
- 7.2 泰勒公式的由来
- 7.3 微积分基本定理与泰勒公式的关系
-
微积分是机器学习背后极其重要且不可或缺的一类数学知识。
绝大多数机器学习算法在训练或者预测时会碰到最优化问题,而最优化问题的解决需要用到微积分中函数极值的求解知识,可以说微积分是机器学习数学大厦的基石。
1 微积分的四类问题
- 求解变速运动中的瞬时速度【微分】
- 求解曲线上某点处的切线【微分】
- 求解函数的最大值和最小值【微分】
- 求解曲线的长度、曲面的面积、物体体积等【积分】
微积分包含众多知识点,其中,研究导数、微分及其应用的部分一般称为微分学,研究不定积分、定积分及其应用的部分一般称为积分学。【统称微积分学】
2 深入理解导数的本质
数学中,函数是描述物体运动与变化的重要工具。
比如说你,你这个人可以被看成一个以时间为自变量、自身状态为因变量的函数,自变量的取值范围是你的寿命,而你就是与时刻对应的无穷多状态的总和。
其实导数的概念并不是凭空产生的,而是基于生产、生活的需要出现的。
导数典型的应用场景就是对瞬时速度的求解。
我们应如何求解一辆汽车在某个时刻的速度【注意:用行驶距离 / 行驶时间得到的是汽车的平均速度,不叫瞬时速度】,也就是瞬时速度呢?【牛顿入手了这个问题】
假设我们想求解汽车在时刻t0的瞬时速度,光盯着这个时刻是没有办法求解的【这个很好理解,因此那个时刻是“静止的”,盯着那儿,也就死在那儿了】,因为汽车在某一时刻的位置是确定的,我们需要把时间延伸到时刻t1。
简单进行一个计算:
一个合理的想法:Δt 越小,Δs / Δt 这个平均速度就越接近于时刻t0 的瞬时速度。【这个也好想明白,两个时刻间隔越小,自然就接近于 “那个值”】
我们再仔细推一下

OK,这个值 2t0 也称为函数s = t^2 + 1 在 t = t0 时刻的导数,即函数在该点的导数。
概括的说, 导数描述了自变量的微小变化导致因变量微小变化的关系。
第一次看到结论,相信你和我一样,会觉得不踏实。使用趋于0的时间段的平均速度来定义瞬时速度的想法虽然 符合常理且很好地解决了难题。
这样采取“近似”的做法让人一时难以接受。。当牛顿开创了微分方法后,虽然由于它的实用性,该方法受到了数学家和物理学家的热烈欢迎,但由于逻辑上一些不清晰的地方,该方法也受到了猛烈批评,最著名的就是乔治 • 伯克利主教对牛顿的微分方法的批评。
伯克利主教猛烈批评牛顿的微分方法,他指出:无穷小量如果等于0,那么它不能作为分母被化简【对!】;
无穷小量如果不等于0,那么它无论多小都不能随意省略。
无穷小量既不是0又是0,那它到底是个什么勾八?【就是这样的问题,导致解释不通了 】
这一逻辑上的缺陷直到19世纪才由柯西等数学家弥补起来。【这也是 “极限” 概念的由来】
将瞬时速度定义为平均速度在Δt趋近于0时的极限值。
那么极限这个东西又要怎么 说清楚?这花费了数学家们一个多世纪的时间,并且整个论证过程烦琐复杂,导致我们学起来很困难。
我们都知道,一次函数可以代表匀速运动,一次项系数k正好就是匀速运动的速度。
如果所有的运动都是匀速运动,那么我们的问题就解决了,匀速运动的速度就是瞬时速度。
回到我们之前那个汽车的行驶栗子:

如果我们认可变速运动的速度变化是连续的,进而微小时间段内的速度变化也较小,可以看作近似的匀速运动,那么可以在微小的时间段内使用匀速运动来代替变速运动。
那么问题来了。
答案是不会!!!!
先下个结论:f1(Δt) 确实就是最接近真实运动规律 f(Δt) 的近似函数。
【证明】
这里就要分情况讨论了
第三种情况下,两个函数是同一个函数,描述的是同一个匀速运动。
因此,我们可以知道由某点的二次函数的常数项和一次项组成的一次函数描述的是最接近该点真实运动规律的匀速运动,匀速运动的速度可以看成该点的瞬时速度。
看到这里会不会感觉就真的有导数内味了
总结一下:
一般来说,如果函数
y = f ( x ) y = f(x) y=f(x)
在x = a 点附近可以使用一次函数或者常数 f1(x) 来近似代替,使得它们的误差
∣ f ( x ) − f 1 ( x ) ∣ |f(x) - f1(x)| ∣f(x)−f1(x)∣
是Δx阶无穷小。我们就可以很容易证明 f1(x) 在 x = a 点处是最接近 f(x) 的一次函数或者常数。
f 1 ( x ) = f ( a ) + k Δ x f1(x) = f(a) + kΔx f1(x)=f(a)+kΔx
的一次项系数k 就是 y = f(x) 在 x = a点处的导数。
3 深入理解复合函数求导
基本函数的复合方式总结起来主要分为3类:函数相加、函数相乘、函数嵌套。
-
加法法则
基本函数相加形成的复合函数导数等于基本函数导数之和。
举个栗子:

-
乘法法则
基本函数相乘形成的复合函数导数等于“前导后不导 加上 后导前不导”。
举个栗子
这样你对乘法法则会不会有了更清晰的认识。
-
链式法则
基本函数嵌套形成的复合函数导数等于“外层导数与内层导数依次相乘”。
同样举个栗子
虽然大多数情况下,我们只需要记住最后的结论就行了
4 理解多元函数偏导
其实,多元函数在生活中随处可见,例如矩形的面积
s = x y ( x , y 分别是矩形的长和宽 ) s = xy (x,y 分别是矩形的长和宽) s=xy(x,y分别是矩形的长和宽)
这就是个二元函数。
梯形的面积
s = ( x + y ) z / 2 ( 我们以前背的上底 + 下底乘高除以 2 ) s = (x + y ) z / 2 (我们以前背的上底 + 下底 乘 高 除以 2) s=(x+y)z/2(我们以前背的上底+下底乘高除以2)
从映射的观点来看,一元函数是实数集到实数集的映射,多元函数则是有序数组集合到实数集合的映射。
看一个典型的一元函数。
f ( x ) = a x 2 + b x + c f(x) = ax^2 + bx + c f(x)=ax2+bx+c
对这个求导有
f ′ ( x ) = 2 a x + b f'(x) = 2ax + b f′(x)=2ax+b
实际上,式子中的a、b、c也是可以变化的。
所以这个求导过程也是求解
f ( x , a , b , c ) = a x 2 + b x + c f(x,a,b,c) = ax^2 + bx + c f(x,a,b,c)=ax2+bx+c
这个函数关于 x 的偏导数。
由此可知,多元函数偏导数的求解方法就是**“各个击破”**,对一个变量求导时,将其他变量暂时看成固定的参数。
我直接板书。

5 梯度究竟是什么?
梯度和导数是密切相关的一对概念,实际上梯度是导数对多元函数的推广,它是多元函数对各个自变量求偏导形成的向量。
一些典型的微分函数:
d ( 2 x ) = 2 d x d(2x) = 2dx d(2x)=2dx
d ( x 2 ) = 2 x d x d(x^2) = 2xdx d(x2)=2xdx
d ( x 2 y 2 ) = 2 x y 2 d x 【这个是个偏导】 d(x^2y^2) = 2xy^2dx 【这个是个偏导】 d(x2y2)=2xy2dx【这个是个偏导】
梯度实际上就是多变量微分的一般化
比如对下面这个函数
J ( θ ) = 3 θ 1 + 4 θ 2 − 5 θ 3 − 1.2 J(θ) = 3θ_1 + 4θ_2 - 5θ_3 - 1.2 J(θ)=3θ1+4θ2−5θ3−1.2
对它求解微分,也就得到了梯度

梯度的本意是一个向量,表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)
一般来说,梯度可以定义为一个函数的全部偏导数构成的向量。梯度在机器学习中有着重要的应用,例如梯度下降算法。【这个必须得会撒】
6 真正理解微积分
微积分基本定理无疑是人类思想最伟大的成就之一。
6.1 直观理解
之前我们说导数的时候,是已知汽车的位移函数来求解某个时刻的瞬时速度。
那么问题就有了,如果已知汽车各个时刻的瞬时速度,能否求出汽车的位移情况甚至位移函数呢?
【答案当然是可以的】
【1】情况1:匀速运动
如果汽车匀速运动,也就是每时每刻的速度都相等,那么汽车位移就应该是速度曲线下方的面积,像下面这样
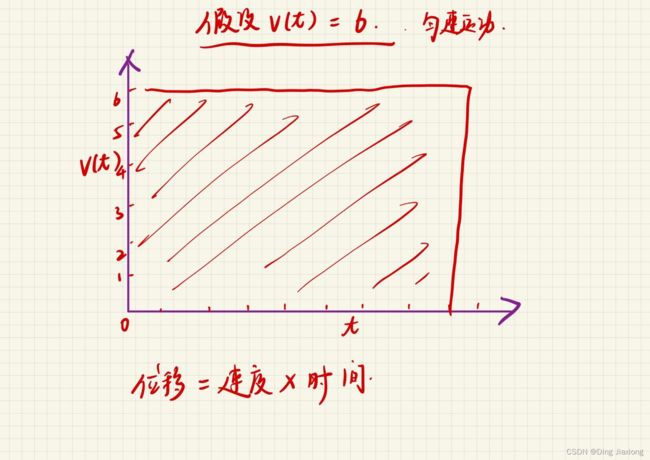
这个很简单。
【2】情况2:变速运动
所以就有了下面这样的一个情况
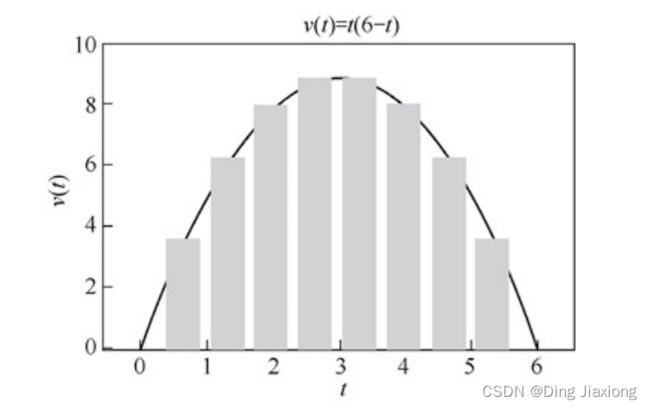
如果把它再分细一点,将 0 - 6 秒划分为很多很多很多份
每一段长度为 dt,该段时间的内的(瞬时) 速度为 v(t)
这个图就会变成下面这样

面积之和
∫ 0 6 v ( t ) d t \int_0^6v(t)dt ∫06v(t)dt
上述过程分解得越来越细致,以至于0~6秒被划分成无穷多个时间段,则直方图的面积最终会趋近于整个速度曲线下方的面积,像下面这样
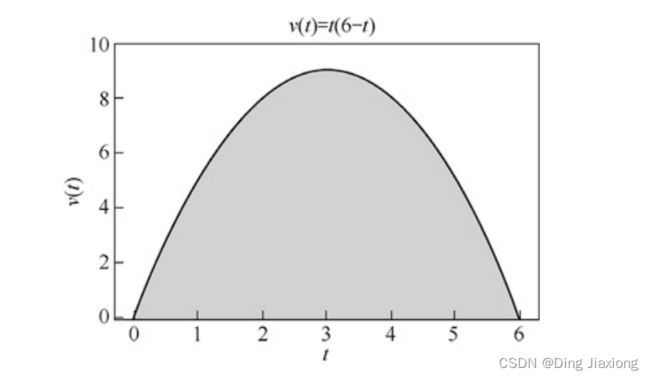
曲线下方的面积就是速度对时间的“积分”,它表示所有的微小量累加起来的结果。
【这就是 积分】
6.2 理解微积分基本定理
有了积分的概念以后,我们就可以进一步思考:积分的数值是多少呢?
一辆汽车从时刻0启动行驶到时刻T,行驶速度函数为
v ( t ) = t ( 6 − t ) v(t) = t(6 - t ) v(t)=t(6−t)
则汽车行驶的位移是多少?
我们首先可以肯定的一个东西是,不同的时刻T对应的速度v(t)和位移s(t)都是不同的。

它一直在变化。
所以现在我们会自然的想到,哪个位移函数对 时间t 求导的结果恰好是上面的速度函数?
这个反推回去很简单,可以算出来位移函数
s ( t ) = − 1 / 3 t 3 + 3 t 2 + c 【 c 是常数】 s(t) = -1/3t ^3 + 3t^2 + c 【c是常数】 s(t)=−1/3t3+3t2+c【c是常数】
这个函数求导的结果就是
− t 2 + 6 t -t^2 + 6t −t2+6t
即我们上面那个速度函数
于是从时刻0到时刻T的位移就是
s ( T ) − s ( 0 ) = − 1 / 3 T 3 + 3 T 2 s(T) - s(0) = -1/3 T^3 + 3T^2 s(T)−s(0)=−1/3T3+3T2
因此,我们可以知道
∫ 0 T v ( t ) d t = s ( T ) − s ( 0 ) = − 1 / 3 T 3 + 3 T 2 \int_0^Tv(t)dt = s(T) - s(0) = -1/3 T^3 + 3T^2 ∫0Tv(t)dt=s(T)−s(0)=−1/3T3+3T2
看个更一般的情况
某个区间的积分结果为
∫ a b v ( t ) d t = s ( b ) − s ( a ) \int_a^bv(t)dt = s(b) - s(a) ∫abv(t)dt=s(b)−s(a)
其中s(t)是函数v(t)的原函数。区间积分结果就会下面这样

上述结论的一般形式就是微积分基本定理:
如果函数f (x)在区间[a,b]上连续,并且存在原函数F (x),则
∫ a b f ( x ) d x = F ( b ) − F ( a ) \int_a^bf(x)dx = F(b) - F(a) ∫abf(x)dx=F(b)−F(a)
【牛逼!这些知识回想起来了!】
7 非常重要的泰勒公式
实际上,泰勒公式是微分的“巅峰”和精华所在。
一个泰勒公式的典型形式:
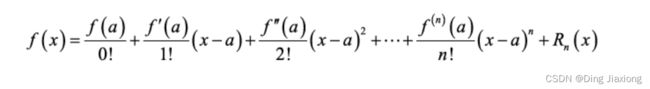
其中,Rn(x)是高阶无穷小量。上述公式也称为f (x)在点a处的泰勒级数。
这个东西一下看不懂没关系,我们先知道它的作用,泰勒公式的主要作用是对特别复杂的函数进行化简,具体来说就是通过近似函数来代替原函数,通过使用简单熟悉的多项式去代替复杂的原函数。
7.1 泰勒的典型应用
看个问题,
已知 9 = 3 ,我现在要你求解 10 的值 已知 \sqrt{9} = 3,我现在要你求解 \sqrt{10} 的值 已知9=3,我现在要你求解10的值
三三得九,9的算术平方根当然好求解,但是根号10,你会不会第一眼看懵掉
其实如果硬解,它真不是一件容易的事情,但是! 如果我们使用泰勒公式,问题就可以轻松化解。
我们转换一下这个问题
对于一个函数 f ( x ) = x , 已知在 a = 9 处,函数值 f ( a ) = 3 , 求点 a = 9 的附近点 x = 10 处的函数值 对于一个函数 f(x) = \sqrt{x} , 已知在a = 9 处,函数值 f(a) = 3,求点 a = 9 的附近点 x = 10 处的函数值 对于一个函数f(x)=x,已知在a=9处,函数值f(a)=3,求点a=9的附近点x=10处的函数值
根据泰勒公式,我们可以得到在点 a = 9 附近的函数展开式:

代入a = 9 化简可得:
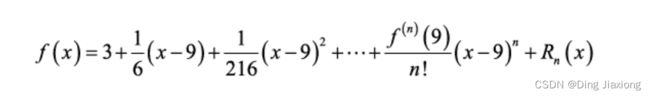
观察这个东西,我们会发现 函数
f ( x ) = x f(x) = \sqrt{x} f(x)=x
在自变量的给定值a附近可以用无穷个多项式不断展开来近似代替,展开式越多,代替的精度也就越高。
比如:
我们 用一次函数
f ( x ) = 3 + 1 / 6 ( x − 9 ) f(x) = 3 + 1/6(x - 9) f(x)=3+1/6(x−9)
代替,那么一次项系数
f ′ ( a ) = f ′ ( 9 ) = 1 / 6 f'(a) = f'(9) = 1/6 f′(a)=f′(9)=1/6
这就反映了函数在 x = a = 9 处的变化。
如果用上面那个 一次函数来近似代替原函数 f(x) = √x 的值,那么精度就依赖于Δx = x - a 的大小。
如果|Δx | 足够小,那么使用一次函数来近似代替的效果就还可以,如果 |Δx | 不够小,那就可能导致误差也不够小。
如果想得到精度更高的近似值,就需要考虑使用更高次项的多项式来代替原函数。
代入 x = 10 看看
-
用一次项近似代替
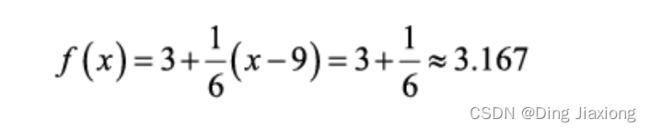
-
用二次项近似代替
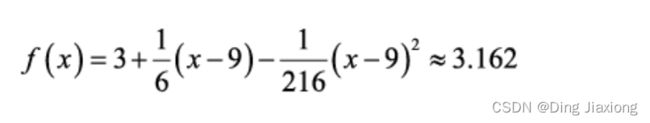
-
用三次项近似代替:
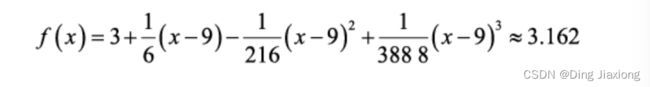
次项越高,代替的精度也就越高。
7.2 泰勒公式的由来
泰勒公式被称为微积分的最高峰,在实践中有着大量而广泛的应用,是数学中广泛应用的函数近似工具。
泰勒公式常见的应用场景是在某个点附近用多项式函数去逼近某个复杂的函数,从而通过多项式函数在该点处的数值去获得复杂函数在该点处的近似值。
多项式函数具有很好的性质,如易于计算、求导和积分等,所以如果能够用多项式函数来近似代替一些复杂函数,那样很多问题就好解决了。
7.3 微积分基本定理与泰勒公式的关系
泰勒公式本质上是微积分基本定理连续累加的结果
微积分基本定理采用定积分来展示函数F(x)与它的导数之间的关系
∫ a b F ′ ( x ) d x = F ( b ) − F ( a ) \int_a^bF'(x)dx = F(b) - F(a) ∫abF′(x)dx=F(b)−F(a)
也就是说,已知F(x)可以求解F'(x)的定积分。
假设a 为定值,且
b − a = h → b = a + h b - a = h → b = a + h b−a=h→b=a+h
则上面的微积分基本定理可以写成:
F ( a + h ) = F ( a ) + ∫ a a + h F ′ ( x ) d x F(a + h) = F(a) + \int_a^{a+h}F'(x)dx F(a+h)=F(a)+∫aa+hF′(x)dx
这样我们就就可以 使用 F’(x) 的定积分和 F(a) 来计算 F(a + h) 的数值
我们继续对定积分进行变量代换
x = a + t x = a + t x=a+t
则有
F ( a + h ) = F ( a ) + ∫ a a + h F ′ ( a + t ) d x F(a + h) = F(a) + \int_a^{a+h}F'(a + t)dx F(a+h)=F(a)+∫aa+hF′(a+t)dx
如果F’(x) 是连续可导函数,
那么
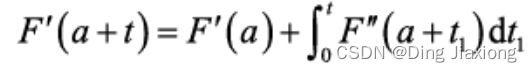
再次迭代:

如此循环迭代,就可以得到泰勒公式。
这说明,泰勒公式本质上是微积分基本定理的多次连用,两者本质上具有统一性。