机器学习、深度学习理论基础,数据推导
0:Deep 概述
-
什么是深度学习:表达学习、可扩展的机器学习、生物神经网络的近似/粗略实现、人类的监督越来越少、多阶段的特征学习过程、相较于传统模式识别
-
激活函数分类
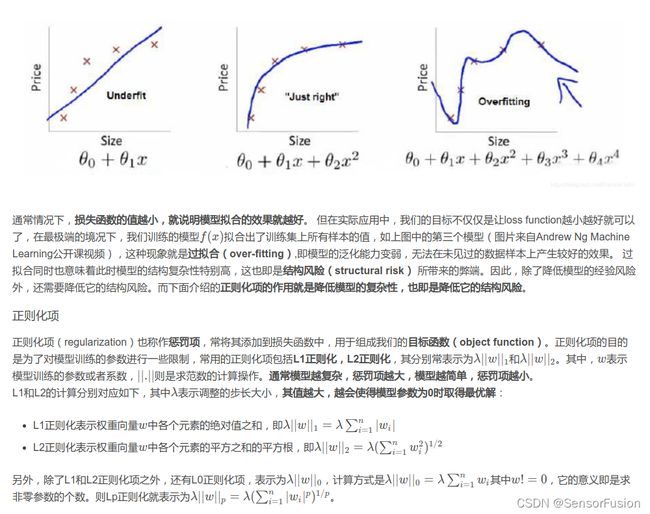
合理的稀疏比例:70~80%,屏蔽特征过多容易出现欠拟合。正则化在深度神经网络训练时的作用
正则化可以很好的解决模型过拟合的问题,常见的正则化方式有L2正则化和dropout,但是正则化是以牺牲模型的拟合能力来达到平衡的,因此在对训练集的拟合中有所损失。
1: L1正则化和L2正则化
L1和L2 详解(范数、损失函数、正则化)
稀疏化
https://zhuanlan.zhihu.com/p/137073968
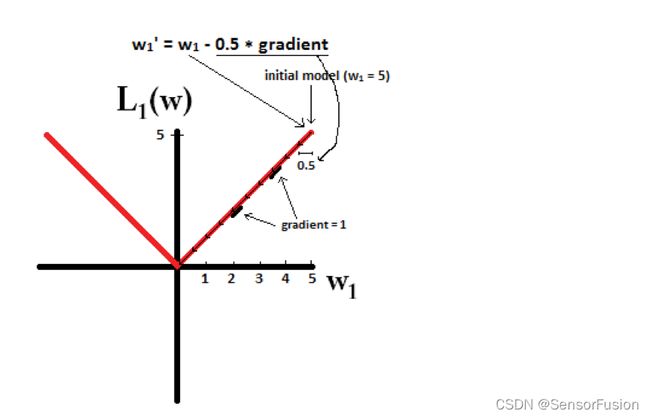
L1正则化可以产生稀疏值矩阵,即产生一个稀疏模型,可以用于特征选择和解决过拟合。能够帮助模型找到重要特征,而去掉无用特征或影响甚小的特征。
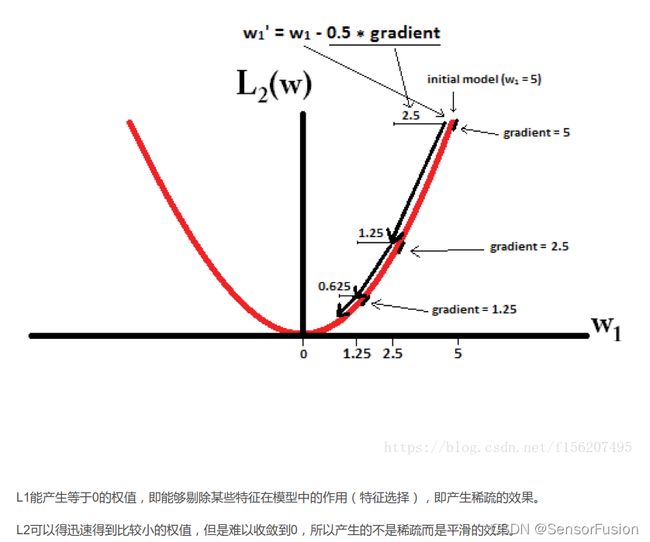
L2 让所有特征的系数都缩小, 但不会减为0,它会使优化求解稳定快速。所以L2适用于特征之间没有关联的情况。
L2正则化可以防止模型过拟合;一定程度上,L1也可以防止过拟合



- 激活函数的作用
激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,深层神经网络表达能力更强大,可以应用到众多的非线性模型中。
- Sigmoid函数
特点:它能够把输入的连续实值变换为0和1之间的输出,特别的,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1.
缺点:在深度神经网络中梯度反向传递时导致梯度爆炸和梯度消失,其中梯度爆炸发生的概率非常小,而梯度消失发生的概率比较大;Sigmoid 的 output 不是0均值;其解析式中含有幂运算,计算机求解时相对来讲比较耗时。
- Relu函数
特点:解决了gradient vanishing问题 (在正区间);计算速度非常快,只需要判断输入是否大于0;收敛速度远快于sigmoid和tanh
缺点:ReLU的输出不是0均值;某些神经元可能永远不会被激活,导致相应的参数永远不能被更新。
- AdaGrad算法
AdaGrad算法就是将每一个参数的每一次迭代的梯度取平方累加后在开方,用全局学习率除以这个数,作为学习率的动态更新。
其中,r为梯度累积变量,r的初始值为0。ε为全局学习率,需要自己设置。δ为小常数,为了数值稳定大约设置为10^-7
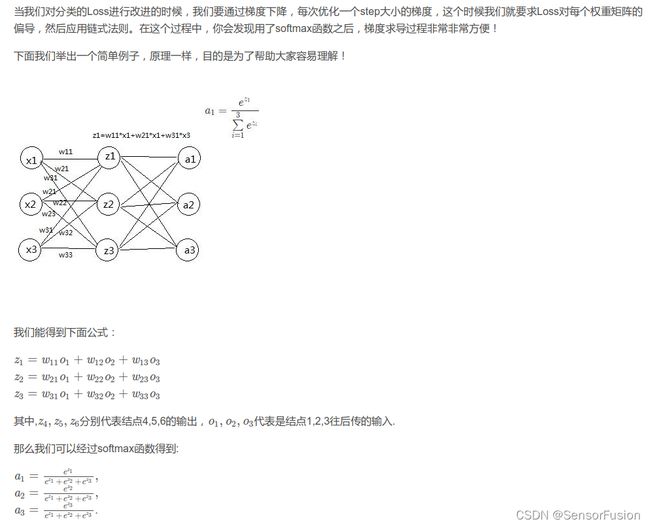
2: BP反向传播,softmax反向求导
多元复合函数求导的链式法则

反向传播
BP神经网络举例原理:
https://zhuanlan.zhihu.com/p/32819991
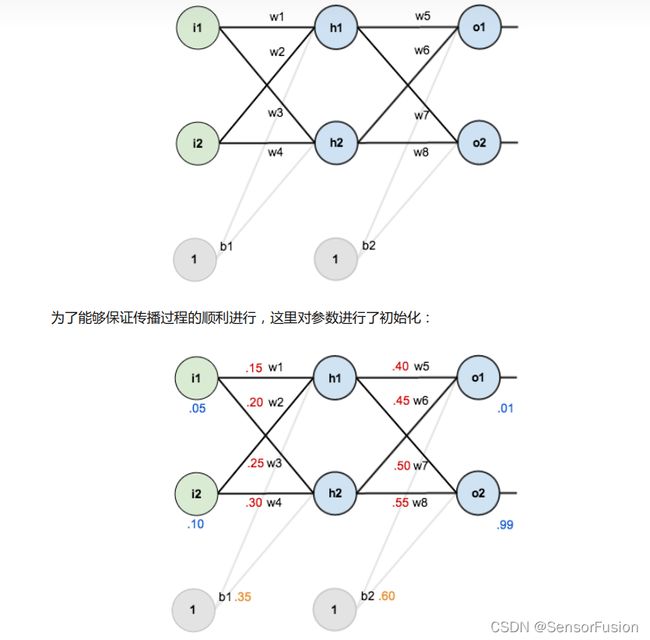
反向传播是根据链式求导法则对参数w和b进行更新。
反向传播其中一个参数更新:

解释上面求导结果:

https://www.cnblogs.com/geekfx/p/14192158.html
https://zhuanlan.zhihu.com/p/25723112
https://blog.csdn.net/xxuffei/article/details/90022008


- 优化算法的选择
如果输入数据是稀疏的,选择任一自适应学习率算法可能会得到最好的结果。无需调整学习率,选用默认值就可能达到最好的结果。
RMSprop, Adadelta, 和 Adam 非常相似,在相同的情况下表现都很好。
偏置校验让Adam的效果稍微比RMSprop好一点
进行过很好的参数调优的SGD+Momentum算法效果好于Adagrad/Adadelta
如果不知道选择哪种优化算法,就直接选Adam吧
- 如何判断模型过拟合
模型在验证集合上和训练集合上表现都很好,而在测试集合上变现很差。过拟合即在训练误差很小,而泛化误差很大,因为模型可能过于的复杂,
- 如何防止过拟合
Dropout:神经网络的每个单元都被赋予在计算中被暂时忽略的概率p,称为丢失率,通常将其默认值设置为0.5。然后,在每次迭代中,根据指定的概率随机选择丢弃的神经元。因此,每次训练会使用较小的神经网络。
提前停止:让模型在训练的差不多的时候就停下来,继续训练带来提升不大或者连续几轮训练都不带来提升的时候,这样可以避免只是改进了训练集的指标但降低了测试集的指标。
批量正则化:将卷积神经网络的每层之间加上将神经元的权重调成标准正态分布的正则化层,可以让每一层的训练都从相似的起点出发,而对权重进行拉伸,等价于对特征进行拉伸,在输入层等价于数据增强。