基于BP神经网络算法的性别识别
目录
基于 BP 神经网络算法的性别识别 1
目录 1
1.背景介绍 2
2. OpenCV 的介绍 3
3.安装 OpenCV 4
4. BP 神经网络算法介绍和实践 4
4.1 BP 神经网络结构 4
4.2 BP 算法原理 5
6
2. 修正权值 8
4.3 BP 算法收敛性 8
5.结果展示 8
2.OpenCV 的介绍
OpenCV 是一个基于 BSD 许可(开源)发行的跨平台计算机视觉库,可以运行在 Linux、
Windows、Android 和 Mac OS 操作系统上。它轻量级而且高效——由一系列 C 函数和少量 C++ 类构成,同时提供了 Python、Ruby、MATLAB 等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
OpenCV 用 C++语言编写,它的主要接口也是 C++语言,但是依然保留了大量的 C 语言接口。该库也有大量的 Python、Java and MATLAB/OCTAVE(版本 2.5)的接口。这些语言的 API 接口函数可以通过在线文档获得。如今也提供对于 C#、Ch、Ruby,GO 的支持。
OpenCV 具有模块化结构,这就意味着开发包里面包含多个共享库或者静态库。下面是可使用的模块:
1.核心功能(Core functionality):一个紧凑的模块,定义了基本的数据结构,包括密集的多维 Mat 数组和被其他模块使用的基本功能。
2.图像处理(Image processing):一个图像处理模块,它包括线性和非线性图像滤波,几何图形转化(重置大小,放射和透视变形,通用基本表格重置映射),色彩空间转 换,直方图等。
3.影像分析(video):一个影像分析模块,它包括动作判断,背景弱化和目标跟踪算法。
4.3D 校准(calib3d):基于多视图的几何算法,平面和立体摄像机校准,对象姿势判断,立体匹配算法,和 3D 元素的重建。
5.平面特征(features2d):突出的特征判断,特征描述和对特征描述的对比。
6.对象侦查(objdetect):目标和预定义类别实例化的侦查(例如:脸、眼睛、杯子、人、汽车等等)。
7.highgui:一个容易使用的用户功能界面。
8.视频输入输出(videoio):一个容易使用的视频采集和视频解码器。
9.GPU:来自不同 OpenCV 模块的 GPU 加速算法。
10.一些其他的辅助模块,比如 FLANN 和谷歌的测试封装,Python 绑定和其他。
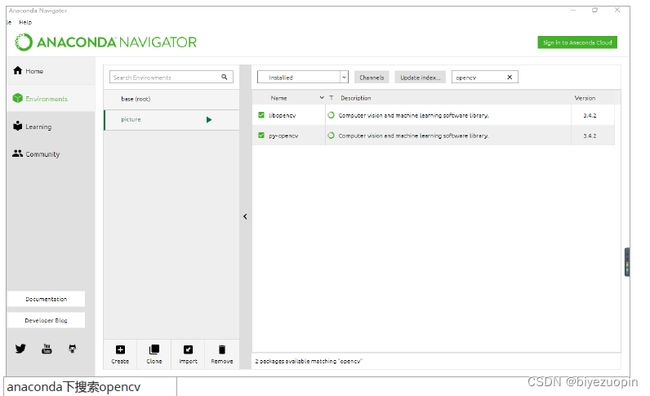
3.安装 OpenCV
我们利用 python 里面已有的库来安装 OpenCV。Python 是一种计算机程序设计语言。是一种动态的、面向对象的脚本语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的、大型项目的开发。
我们只需要通过 pip 或者 anaconda 安装 OpenCV 包就可以通过导入包并使用。
4.BP 神经网络算法介绍和实践
BP 神经网络通常是指基于误差反向传播算法( Back Propagation, 简称 BP 算法)的多层前向神经网络 ( Multi-laye Feed-forward Neural Networks, MFNN),它最初是由 Paul
Werboss 在 1974 年提 出, 但未在传播,直到 20 世纪 80 年代中期 Rumelhart、Hinton 和Williams, David Parker 和 Yann Le Cun 重新发现了 BP 算法,同时因此算法被包括在《并行分布处理》(Parallel Distributed Processing),此算法才广为人知。本文转载自http://www.biyezuopin.vip/onews.asp?id=14996目前 BP 算法已成为应用最广泛的神经网络学习算法,据统计有近 90%的神经网络应用是基于 BP 算法的。BP 网络的神经元采用的传递函数通常是 Sigmoid 型可微函数,所以可以实现输入和输出间的任意非线性映射,这使得它在诸如信号处理、计算机网络、过程控制、语音识别、函数逼近、模式识别及数据压缩等领域均取得了成功的应用。
from PIL import Image
import dlib
import cv2
import os.path
import PIL.Image
from pylab import *
import os
import numpy as np
import shutil
'''
通过BP神经网络学习图片并检测性别
'''
'''参数选择'''
picture_show=0 #是否显示照片
pixel=40 #像素大小
pixel_mat=pixel*pixel #像素总个数
file_num=0 #文件数量
photonum=0 #照片总数量
boy_photonum=0 #男生照片总数量
girl_photonum=0 #女生照片总数量
'''路径选择'''
girlpath = '../beauty' #女孩照片路径,用于训练
boypath = '../nan' #男孩照片路径,用于训练
photopath = '../faces' #截取彩色照片路径
graypath = '../grayfaces' #黑白照片路径
numpath= '../faces' #用于读取照片数量路径
def deletphoto(dir):
delList = os.listdir(dir)
for f in delList:
filePath = os.path.join(dir, f)
if os.path.isfile(filePath):
os.remove(filePath)
print(filePath + " was removed!")
elif os.path.isdir(filePath):
shutil.rmtree(filePath, True)
print('Directory: " + filePath +"was removed!')
'''
利用别人写好的人脸分类器来截取图片中的人脸,并保存到spath中
i:截取图片保存名
path:原图片路径
spath:处理过后图片路径
'''
def get_face_from_photo(i,path,spath):
detector = dlib.get_frontal_face_detector() #获取人脸分类,采用dlib进行人脸识别,dlib更多的人脸识别模型,可以检测脸部68甚至更多的特征点
filenames = os.listdir(path) # 读取path路径下的图片,获得所有的图片名字
for f1 in filenames:
f = os.path.join(path,f1)
img = cv2.imread(f, cv2.IMREAD_COLOR)
iimag = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB)) #转换文件格式
counts = detector(img, 1) #人脸检测
for index, face in enumerate(counts): #在图片中标注人脸,并显示
left = face.left()
top = face.top()
right = face.right()
bottom = face.bottom()
j =str(i)
j = j+'.jpg'
save_path = os.path.join(spath,j)
region = (left,top,right,bottom)
cropImg = iimag.crop(region) #裁切图片
cropImg.save(save_path) #保存裁切后的图片
if(picture_show==0):
print(i)
i +=1
cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0), 3)
if(picture_show==1):
cv2.namedWindow(f, cv2.WINDOW_AUTOSIZE)
cv2.imshow(f, img)
print("read_ok")
if(picture_show==1):
k = cv2.waitKey(0)
cv2.destroyAllWindows()
return i
'''
将人脸图片转化为pixel*pixel的灰度图片
path:人脸图片
spath:灰度图片
'''
def change_photo_size(path,spath):
filenames = os.listdir(path)
for filename in filenames:
f = os.path.join(path,filename)
iimag = PIL.Image.open(f).convert('L').resize((pixel,pixel))
savepath = os.path.join(spath,filename)
iimag.save(savepath)
'''
读取训练图片
k:照片数量
photo_path:照片保存的路径
'''
def read_photo_for_train(k,photo_path):
for i in range(k):
j = i
j = str(j)
st = '.jpg'
j = j+st
j = os.path.join(photo_path,j)
im1 = array(Image.open(j).convert('L'))
im1 = im1.reshape((pixel_mat,1))
if i == 0: #把所有的图片灰度值放到一个矩阵中,一列代表一张图片的信息
im = im1
else:
im = np.hstack((im,im1))
return im
'''
sigmoid函数实现
'''
def layerout(w,b,x):
y = np.dot(w,x) + b
t = -1.0*y
y = 1.0/(1+exp(t))
return y
'''
训练样本:百度的图片。女生标签为0,男生标签为1.
训练方法:简单的梯度下降法
参考:https://blog.csdn.net/yunyunyx/article/details/80539222
'''
'''
设置一个隐藏层,为每张照片像素值-->pixel_mat 隐藏层神经元个数-->1
输入为每张图片的灰度像素矩阵
x_train:训练样本的像素数据
y_train:训练样本的标签
w:输出层权重
b:输出层偏置
w_h:隐藏层权重
b_h:隐藏层偏置
step:循环步数
'''
def mytrain(x_train,y_train):
step=int(input('mytrain迭代步数:'))
a=double(input('学习因子:'))
inn = pixel_mat #输入神经元个数
hid = int(input('隐藏层神经元个数:')) #隐藏层神经元个数
out = 1 #输出层神经元个数
w = np.random.randn(out,hid)
w = np.mat(w)
b = np.mat(np.random.randn(out,1))
w_h = np.random.randn(hid,inn)
w_h = np.mat(w_h)
b_h = np.mat(np.random.randn(hid,1))
for i in range(step):
#打乱训练样本
r=np.random.permutation(photonum)
x_train = x_train[:,r]
y_train = y_train[:,r]
for j in range(photonum):
x = np.mat(x_train[:,j])
x = x.reshape((pixel_mat,1))
y = np.mat(y_train[:,j])
y = y.reshape((1,1))
hid_put = layerout(w_h,b_h,x)
out_put = layerout(w,b,hid_put)
#更新公式的实现
o_update = np.multiply(np.multiply((y-out_put),out_put),(1-out_put)) #计算输出单元误差项,y->tk
h_update = np.multiply(np.multiply(np.dot((w.T),np.mat(o_update)),hid_put),(1-hid_put)) #隐藏单元误差项
outw_update = a*np.dot(o_update,(hid_put.T)) #从隐藏层到输出层的dw
outb_update = a*o_update
hidw_update = a*np.dot(h_update,(x.T))
hidb_update = a*h_update
w = w + outw_update #更新参数
b = b+ outb_update
w_h = w_h +hidw_update
b_h =b_h +hidb_update
return w,b,w_h,b_h
'''
预测结果pre大于0.5,为男;预测结果小于或等于0.5为女
'''
def mytest(x_test,w,b,w_h,b_h):
hid = layerout(w_h,b_h,x_test);
pre = layerout(w,b,hid);
print(pre)
if pre > 0.5:
print("hello,boy!")
else:
print("hello,girl!")
return pre
'''主函数'''
deletphoto(photopath)
deletphoto(graypath)
#框出人脸,并保存到faces中,i为保存的名字
i = 0
i = get_face_from_photo(i,girlpath,photopath) #女孩
girl_photonum=i
print(girl_photonum)
i = get_face_from_photo(i,boypath,photopath) # 男孩
boy_photonum=i-girl_photonum
print(boy_photonum)
change_photo_size(photopath,graypath) #将人脸图片转化为28*28的灰度图片
photonum=(len([lists for lists in os.listdir(numpath) if os.path.isfile(os.path.join(numpath, lists))])) #获取图片数量
print(photonum)
im = read_photo_for_train(photonum,graypath)
#归一化
immin = im.min()
immax = im.max()
im = (im-immin)/(immax-immin)
x_train = im
#制作标签,女生为0,男生为1
y1 = np.zeros((1,girl_photonum))
y2 = np.ones((1,boy_photonum))
y_train = np.hstack((y1,y2))
#开始训练
print("----------------------开始训练-----------------------------------------")
w,b,w_h,b_h = mytrain(x_train,y_train)
print("-----------------------训练结束------------------------------------------")
# 测试
print("--------------------视频测试-----------------------------------------")
camera= cv2.VideoCapture(0)
while(True):
ret, f = camera.read() #图片来自视频中读取的内容
detector = dlib.get_frontal_face_detector() #获取人脸分类,采用dlib进行人脸识别,dlib更多的人脸识别模型,可以检测脸部68甚至更多的特征点
iimag = Image.fromarray(cv2.cvtColor(f, cv2.COLOR_BGR2RGB)) #把灰度处理后的图片进行处理,把OpenCV转换成PIL.Image格式
counts = detector(f, 1) # 人脸检测
for index, face in enumerate(counts): # 在图片中标注人脸,并显示
left = face.left()
top = face.top()
right = face.right()
bottom = face.bottom()
region = (left, top, right, bottom)
cropImg = iimag.crop(region) #将识别出的人脸提取出来
finaImg=cropImg.convert('L').resize((pixel,pixel)) #把大小统一转换成28*28像素
im1 = array(finaImg)
im1 = im1.reshape((pixel_mat, 1))
im = im1
#归一化
immin = im.min()
immax = im.max()
im = (im - immin) / (immax - immin)
i=0
x_test = im
xx = x_test[:, i]
xx = xx.reshape((pixel_mat, 1))
mytest(xx, w, b, w_h, b_h)
pre=mytest(xx, w, b, w_h, b_h)
font = cv2.FONT_HERSHEY_SIMPLEX # 使用默认字体
if pre > 0.5:
img = cv2.putText(f, 'man', (left, top - 30), font, 1.2, (255, 255, 255),2) # 添加文字,1.2表示字体大小,(0,40)是初始的位置,
# 保存
else:
img = cv2.putText(f, 'girl', (left, top - 30), font, 1.2, (255, 255, 255), 2) # 添加文字,1.2
cv2.rectangle(f, (left, top), (right, bottom), (0, 255, 0), 2)
cv2.imshow("camera", f)
if cv2.waitKey(1) & 0xff == ord("q"):
break
camera.release()
cv2.destroyAllWindows()