模型评估(一)
只有选择与问题相匹配的评估方法,才能快速的发现模型选择或训练过程中出现的问题,迭代地对模型进行优化。模型评估主要分为离线评估和在线评估两个阶段。针对分类、排序、回归、序列预测等不同类型的机器学习问题,评估指标的选择也有所不同。有针对性地选择合适的评估指标、根据评估指标的反馈进行模型调整,是机器学习在模型评估阶段的关键。
一、评估指标的局限性
在模型评估过程中,分类问题、排序问题、回归问题往往需要使用不同的指标进行评估。在诸多的评估指标中,大部分指标只能片面地反映模型的一部分性能。如果不能合理地运用评估指标,不仅不能发现模型本身的问题,而且会得出错误的结论。常见的评估指标:如准确率、精确率、召回率、均方根误差。
1. 准确率的局限性
准确率 = 分类正确的样本个数/总样本个数。准确率是分类问题中最简单也是最直观的评价指标,但存在明显的缺陷。比如,当负样本占99%时,分类器把所有样本都预测为负样本也可以获得99%的准确率。所以,当不同类别的样本比例非常不均衡时,占比大的类别往往成为影响准确率的最主要因素。
为了解决这个问题,可以使用更为有效的平均准确率(每个类别下的样本准确率的算术平均)作为模型评估的指标。
即使评估指标选择对了,仍会存在模型过拟合或欠拟合、测试集和训练集划分不合理、线下评估与线上测试的样本分布存在差异等一系列问题。但评估指标的选择是最容易被发现,也是最可能影响评估结果的因素。
2. 精确率与召回率的权衡
精确率 = 分类正确的正样本个数/分类器判定为正样本的样本个数
召回率 = 分类正确的正样本个数/真正的正样本个数
在排序问题中,通常没有一个确定的阈值把得到的结果直接判定为正样本或负样本,而是采用Top N返回结果的精确值和召回值来衡量排序模型的性能,即可以认为模型返回的Top N的结果就是模型判定的正样本,然后计算前 N 个位置上的精确率和前 N 个位置上的召回率。
精确率和召回率是既矛盾又统一的两个指标,为了提高精确率,分类器需要尽量在更有把握时才把样本预测为正样本,但此时往往会因为过于保守而漏掉很多没有把握的正样本。导致召回率降低。
用户找不到想看的视频,说明模型没有把相关的视频呈现给用户。显然是召回率比较低。如果相关结果有100个,即使top5的精确率达到了100%,但是top5的召回率也仅仅是5%。所以在模型评估时,应同时关注精确率和召回率,选取不同Top N的结果进行观察,或者选取更高阶的评估指标来全面的反应模型在准确率和召回率两方面的表现。
为了综合评估一个排序模型的好坏,不仅要看模型的不同Top N下的精确率和召回率,做好绘制出模型的P-R曲线。
P-R曲线的横轴是召回率,纵轴是精确率。对于一个排序模型来说,P-R曲线上的一个点代表着,在某一阈值下,模型将大于该阈值的结果判定为正样本,小于该阈值的结果判定为负样本,此时返回结果对应的召回率和精确率。整条P-R曲线是通过将阈值从高到低移动而生成的。如下图,原点附近代表当阈值最大时模型的精确率和召回率。
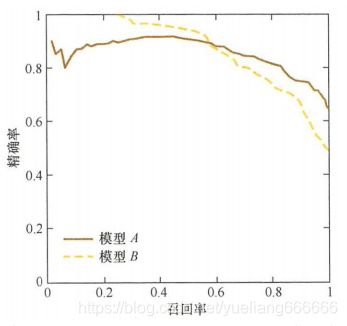
由图可见,当召回率接近于0时,模型A的精确率为0.9,模型B的精确率时1,这说明模型B得分前几位的样本全部是真的正样本。而模型A即使得分最高的几个样本也存在预测错误的情况。并且随着召回率的增加,精确率整体呈下降趋势。但是当召回率为1时,模型A的精确率反而超过了模型B。这充分说明,只用某个点对应的精确率和召回率是不能全面地衡量模型的性能。只有通过P-R曲线的整体表现,才能够对模型进行更为全面的评估。
除此之外, F1 score和ROC曲线也能综合地反应一个排序模型的性能。F1 score是精确率和召回率的调和平均值。
F1 score = 2精确率召回率/(精确率+召回率)
3. 平方根误差的意外
RMSE 均方根误差,用来衡量回归模型的好坏。
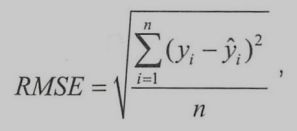
其中,yi是第i个样本点的真实值,n是样本点的个数。
![]()
一般情况下,RMSE能很好的反应回归模型预测值与真实值的偏离程度。但在实际问题中,如果存在个别偏离程度非常大的离群点时,即使离群点数量非常少,也会让RMSE指标变得很差。
模型在95% 的时间区间内的预测误差都小于1%,这说明在大部分时间区间内,模型的预测效果都是非常优秀的。然而RMSE却一直很差,这很可能是由于在其他的5%时间区间内存在非常严重的离群点。事实上,在流量预估这个问题上,噪声点很容易产生。比如流量特别小的美剧、刚上映的美剧或者刚获奖的美剧,或者一些突发事件带来的流量,都可能造成离群点。
针对此问题的解决方案。1.如果认定这些离群点是噪声点,就需要在数据预处理的阶段把这些噪声点过滤掉。2.如果不认为这些离群点是噪声点,就需要进一步提高模型的预测能力,将离群点产生的机制建模进去。3.找一个更合适的指标来评估该模型。存在比RMSE的鲁棒性更好的指标,比如平均绝对百分比误差(MAPE)。
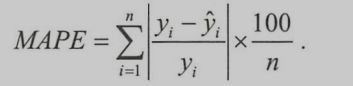
相比于RMSE,MAPE相当于把每个点的误差进行了归一化,降低了个别离群点带来的绝对误差的影响。
以上的问题都说明了选择合适指标的重要性。每个评估指标都有其价值,但如果只从单一的评估指标出发去评估模型,往往会得出片面甚至错误的结论;只有通过一组互补的指标去评估模型,才能更好地发现并解决模型存在的问题,从而更好地解决遇到的问题。
二、ROC曲线
二值分类器是机器学习领域最常见也是应用最广泛的分类器。评价二值分类器的指标有很多:比如精确率,召回率,F1 score,P-R曲线。但是这些指标或多或少只能反应模型在某一方面的性能。相比而言,ROC曲线有很多优点,经常作为评估二值分类器的最重要的指标之一。
1. 什么是ROC曲线
ROC曲线中文名为受试者工作特征曲线。ROC曲线的横坐标为假阳性率(FPR),纵坐标为真阳性率(TPR)。
FPR = FP/N TPR = TP/P
P是真实的正样本的数量,N是真实的负样本的数量,TP是P个正样本被分类器预测为正样本的个数,FP是N个负样本中被分类器预测为正样本的个数。
2. 如何绘制ROC曲线?
事实上,ROC曲线是通过不断移动分类器的截断点来生成曲线上的一组关键点的。截断点就是区分正负预测结果的阈值。
通过动态的调整截断点,从最高的得分开始(实际上是从正无穷开始,对应着ROC曲线的零点),逐渐调整到最低得分,每一个截断点都会对应一个FPR 和 TPR,在ROC图上绘制出每个截断点对应的位置,在连接所有点就得到最终的ROC曲线。
其实,还有一种更直观地绘制ROC曲线的方法。首先根据样本标签统计出正负样本的数量,假设正样本数量为P,负样本数量为N;接下来,把横轴的刻度间隔设置为1/N,纵轴的刻度间隔设置为1/P;再根据模型输出的预测概率对样本进行排序(从高到低);依次遍历样本,同时从零点开始绘制ROC曲线,每遇到一个正样本就沿着纵轴方向绘制一个刻度间隔的曲线,每遇到一个负样本就沿着横轴方向绘制一个刻度间隔的曲线,直到遍历完所有的样本,曲线最终停在(1,1)这个点,整个ROC曲线绘制完成。
3. 如何计算AUC ?
AUC指的是ROC曲线下的面积大小,该值能够量化地反应基于ROC曲线衡量出的模型性能。计算AUC值只需要沿着ROC横轴做积分就可以了。由于ROC曲线一般都处于y = x这条直线的上方(如果不是的话,只需要把模型预测的概率反转成1-p就可以得到一个更好的分类器),所以AUC的取值一般在0.5~1之间。AUC 越大,说明分类器越可能把真正的正样本排在前面,分类性能越好。
python中计算AUC代码:
import numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
roc_auc_score(y_true, y_scores)
0.75
4. ROC曲线相比P-R曲线有什么特点?
相比于P-R曲线,ROC曲线有一个特点,当正负样本的分布发生变化时,ROC曲线的形状能够基本保持不变,而P-R曲线的形状一般会发生较剧烈的变化。
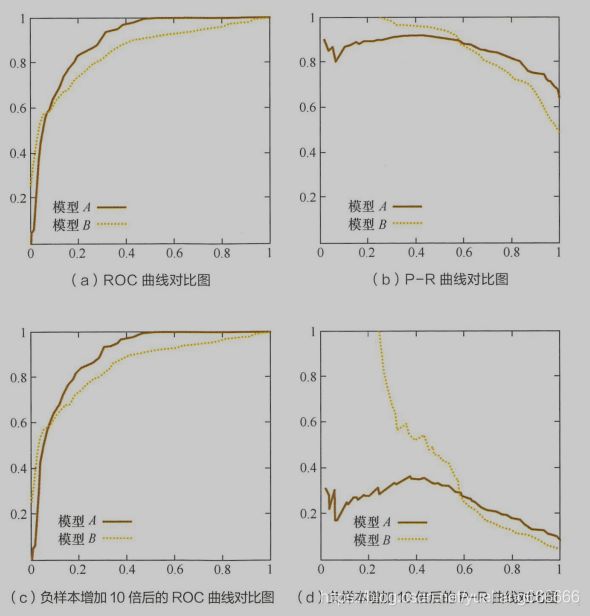
由上图可以看出,P-R曲线发生了明显的变化,而ROC曲线形状基本不变。这个特点让ROC曲线能尽量降低不同测试集带来的干扰,更加客观地衡量模型本身的性能。在很多实际问题中,正负样本数量往往很不均衡。若选择不同的测试集,P-R 曲线的变化就会非常大,而ROC曲线则能更稳定的反应模型本身的好坏。所以ROC曲线适用场景更多,被广泛用于广告、推荐、排序等领域。但是如果希望更多地看到模型在特定数据集上的表现,P-R 曲线则能更直观的反映其性能。
三、余弦距离的应用
在模型训练过程中,也在不断地评估着样本间的距离,如何评估样本距离也是定义优化目标和训练方法的基础。
在机器学习问题中,通常将特征表示为向量的形式,所以在分析两个特征向量之间的相似性时,常使用余弦相似度来表示。余弦相似度的取值范围是[-1,1],相同的两个向量之间的相似度为1。如果得到类似于距离的表示,将1减去余弦相似度即为余弦距离。因此,余弦距离的取值范围为[0,2],相同的两个向量余弦距离为0。
1. 为什么在一些场景中要使用余弦相似度而不是欧式距离?

即两个向量夹角的余弦,关注的是向量之间的角度关系,并不关心他们的绝对大小,其取值范围是[-1,1]。当一对文本相似度的长度差距很大、但内容相近时,如果使用词频或者词向量作为特征,他们在特征空间中欧式距离通常很大;而如果使用余弦相似度的话,他们之间的夹角可能很小,因而相似度很高。此外,在文本、图像、视频等领域,研究的对象的特征维度往往很高,余弦相似度在高维情况下依然保持相同时为1,正交时为0,相反时为-1的性质,而欧式距离的数值则受维度的影响,范围不固定,并且含义也比较模糊。
在一些场景中,例如Word2Vec中,其向量的模长是经过归一化的,此时欧式距离与余弦距离有着单调的关系,
![]()
![]()
(1-cos(A,B))表示余弦距离。在此情况下,如果选择距离最小(相似度最大)的近邻,那么使用余弦相似度和欧式距离的结果是相同的。
总体来说,欧式距离体现数值上的绝对差异,而余弦距离体现方向上的相对差异。
例如统计两部剧的用户观看行为,用户A的观看向量为(0,1),用户B为(1,0);此时二者的余弦距离很大,而欧式距离很小;分析两个用户对于不同视频的偏好,更关注相对差异,显然应当使用余弦距离。当分析用户活跃度,以登陆次数和平均观看时长作为特征时,余弦距离会认为(1, 10)、(10,100)两个用户距离很近;但显然这两个用户活跃度有极大差异,此时更关注数值绝对差异,应当使用欧式距离。
2. 余弦距离是否是一个严格定义的距离?
距离的定义:在一个集合中,如果每一对元素均可唯一确定一个实数,使得三条距离公理(正定性,对称性,三角不等式)成立,则该实数可称为这对元素之间的距离。余弦距离满足正定性和对称性,但是不满足三角不等式,因此他并不是严格定义的距离。
正定性:d(x,y)>=0,取等号当且仅当x=y
对称性:d(x,y)=d(y,x)
三角不等式:在三角形中两边之和大于第三边

在机器学习领域,被俗称为距离,却不满足三条距离公理的不仅有余弦距离,还有KL 距离,也叫相对熵,它常用于计算两个分布之间的差异,但不满足对称性和三角不等式。
四、A/B测试的陷阱
A/B测试是验证新模块、新功能、新产品是否有效,新算法,新模型效果是否有提升,新设计是否收到用户欢迎,新更改是否影响用户体验的主要测试方法。A/B测试是验证模型最终效果的主要手段。
1. 在对模型进行过充分的离线评估之后,为什么还要进行在线A/B测试?
a) 离线评估无法完全消除模型过拟合的影响,因此,得出的离线评估结果无法完全替代线上评估结果。
b) 离线评估无法完全还原线上的工程环境。一般来讲,离线评估往往不会考虑线上环境的延时、数据丢失、标签数据缺失等情况。因此离线评估的结果是理想工程环境下的结果。
c) 线上系统的某些商业指标在离线评估中无法计算。离线评估一般是针对模型本身进行评估,而与模型相关的其他指标,特别是商业指标,往往无法直接获得。比如,上线了新的推荐算法,离线评估往往关注的是ROC 曲线、P-R曲线等的改进,而线上评估可以全面了解该推荐算法带来的用户点击率、留存时长、 PV 访问量等的变化。这些都要由A/B测试来进行全面的评估。
2. 如何进行线上A/B测试?
进行A/B测试的主要手段是进行用户分桶,即将用户分成实验组和对照组,对实验组的用户施以新模型,对对照组的用户施以旧模型。在分桶的过程中,要注意样本的独立性和采样方式的无偏性,确保同一用户每次只能分到同一个桶中,在分桶过程中所选取的user_id需要是一个随机数,这样才能保证桶中的样本是无偏的。
3. 如何划分实验组和对照组?
实验组和对照组划分时,要保证除了对比的因素不一样之外,其他的因素全都要一模一样。