异常检测论文
1. PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization
【论文笔记(8)】PaDiM a Patch Distribution Modeling Framework for Anomaly Detection and Localization_国家二级退堂鼓表演家的博客-CSDN博客
基于重构的方法被广泛应用于异常检测和定位。训练像自动编码器[1]、[9]-[11]、变分自动编码器[3]、[12]-[14]或生成对抗网络[15]-[17]这样的神经网络体系结构,只重建正常的训练图像。因此,异常图像可以被发现,因为它们没有很好地重建。在图像层面上,最简单的方法是将重构误差作为异常分数[10],但从潜在空间[16]、[18]、中间激活[19]或一个鉴别器[17]、[20]可以更好地识别异常图像。为了定位异常,基于重构的方法可以将像素级重构误差作为异常评分[1]或结构相似度[9]。或者,异常地图可以是由潜在空间[3]、[14]生成的视觉注意力地图。尽管基于重建的方法非常直观和可解释,但它们的性能受到限制,因为AE有时可以对异常图像(包括[21])产生良好的重建结果
基于相似度的嵌入方法利用深度神经网络提取描述整幅图像的有意义向量,用于异常检测[6]、[22]-[24],或用于异常定位[2]、[4]、[5]、[25]的图像Patch。尽管如此,仅执行异常检测的基于相似度的嵌入方法给出了有希望的结果,但往往缺乏可解释性,因为它不可能知道异常图像的哪一部分是导致高异常分数的原因。在这种情况下,异常分数是测试图像的嵌入向量与代表训练数据集正态性的参考向量之间的距离。法向参考可以是包含法向图像[4]、[22]嵌入的nsphere的中心,高斯分布参数[23]、[26]或整个法向嵌入向量集合[5]、[24]。最后一个选项是SPADE[5],它在异常定位方面报告的结果最好。然而,在测试时,它在一组正规的嵌入向量上运行K-NN算法,因此推理复杂度随数据集训练大小线性增长。这可能会阻碍该方法的工业应用
说白了,取最大特征图上的一点上的特征,顺次高层特征图上对应点的特征取出,然后将这所有的特征向量拼接在一起,作为这点的特征向量,那么这个点上有 N 个特征向量, N 为训练集大小, 假设 N 个特征向量服从正态分布,那么把这个正态分布的期望和标准差就作为这个点的最终正常特征.
推理时,将待测图片也计算出特征向量,然后根据马氏距离计算每个点的差异,得到最终的缺陷值


2. MobileNet V1—(专注于移动设备上的轻量级网络)
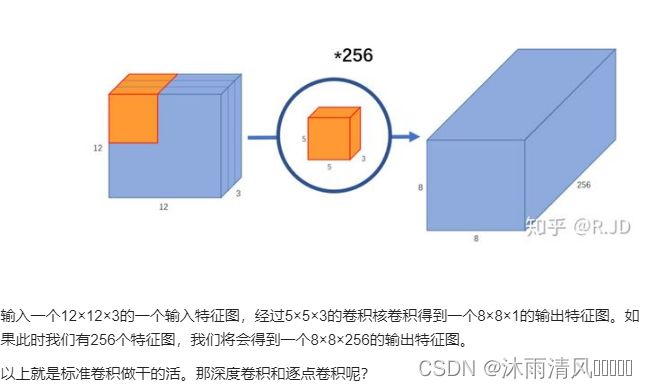
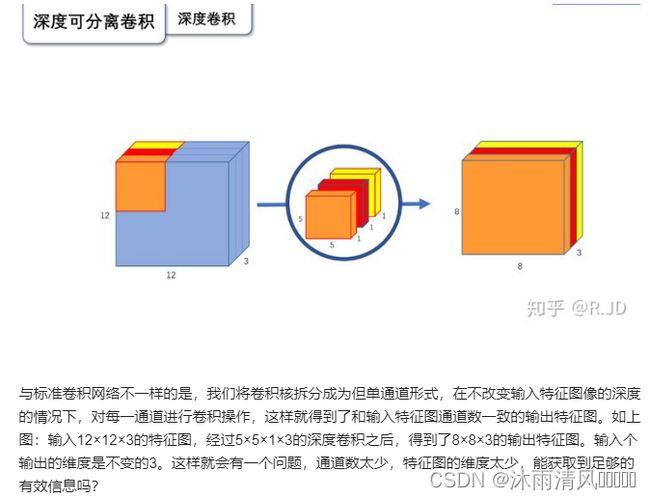
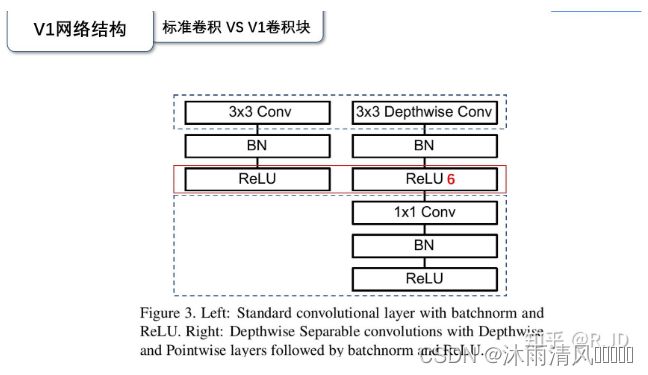
其主要的思想还是在于:深度可分离卷积
空间分离卷积:就是将3x3 变成1x3 3x1这种达到减少计算量的目的

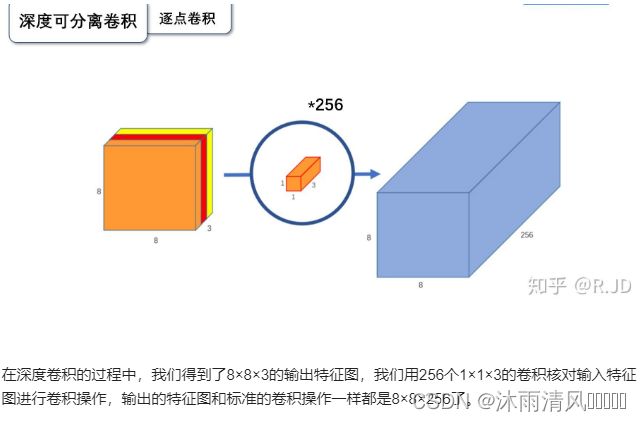
MobileNet V2
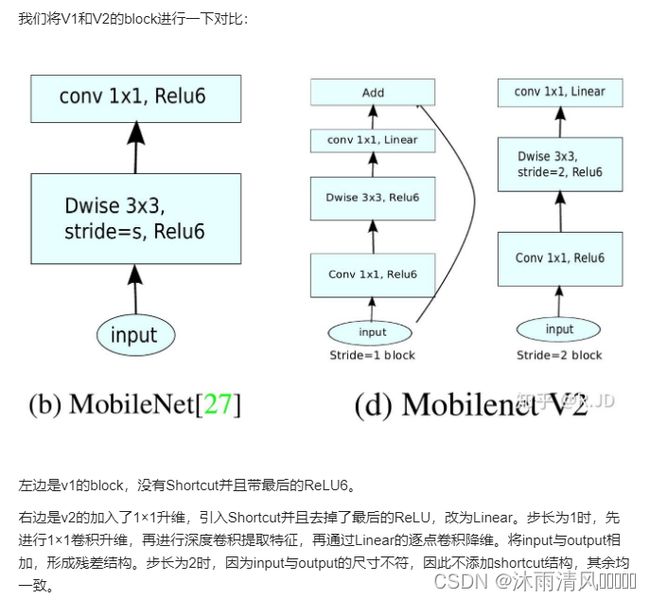
在实际使用的时候, 发现深度卷积部分的卷积核比较容易训废掉:训完之后发现深度卷积训出来的卷积核有不少是空的
对低维度做ReLU运算,很容易造成信息的丢失。而在高维度进行ReLU运算的话,信息的丢失则会很少