机器学习PCA——实验报告
机器学习实验报告
- 〇、实验报告pdf可在该网址下载
- 一、实验目的与要求
- 二、实验内容与方法
-
- 2.0 PCA算法学习与回顾
-
- 2.0.1 PCA推导的优化问题
- 2.0.2 优化问题的解
- 2.0.3 算法流程
- 2.1 人脸数据集
- 2.2 实验流程图
- 三、实验步骤与过程
-
- 3.1 实验过程
-
- 3.1.2 实验效果图
- 3.2 PCA算法的人脸图像降维
-
- 3.2.1 人脸图像降维步骤
- 3.2.2 三个数据集降至2,3维的可视化效果图
- 3.3 PCA+KNN 人脸识别
-
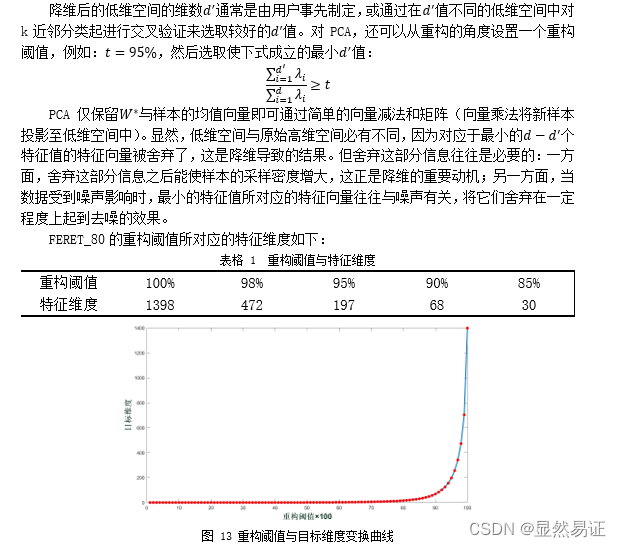
- 3.3.1 降维的重构阈值
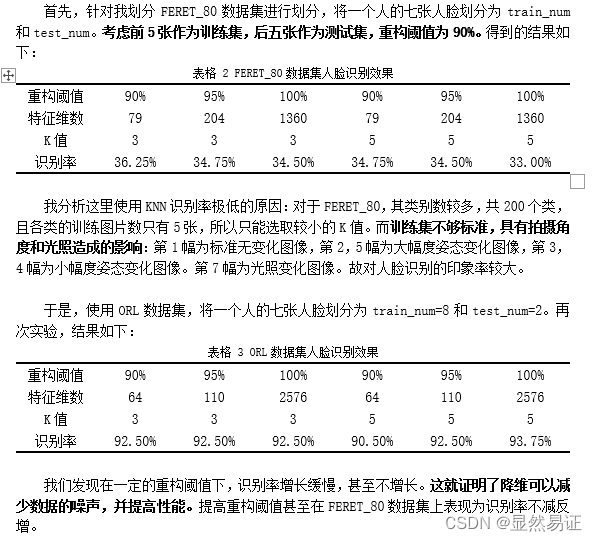
- 3.3.2 人脸识别效果数据展示
- 3.4 设计一个新的PCA算法
- 四、实验结论或体会
〇、实验报告pdf可在该网址下载
机器学习实验一:PCA
这个需要积分下载(因为实验报告后台查重,不建议直接白嫖)。
建议看博客,博客里面会有很多实验报告小说明会用【…】加粗注释。
一、实验目的与要求
- 实现 PCA 算法的人脸重构,即用 20,40,60,80,…,160 个投影来重构图像的效果;
- 实现 PCA 算法的人脸识别,给出 10,20,30,…,160 维的人脸识别识别率;
- 用 PCA 用来进行人脸图像降维,实现 3 个不同数据集多个子集的二维和三维空间实
现数据的可视化; - 同时设计一个新的 PCA 算法,内容简要写在实验报告中,并与经典 PCA 比较。(详
细内容可另写成一篇论文提交到“论文提交处”。); - 所有的实验必须独立完成,实验报告与代码等绝对不要抄!!我们后台有查重功能,
COPY一旦发现该课程为0分。不要把大一时做的那个垃圾级的PCA项目报告再次交上来,我要查看重复率。
二、实验内容与方法
2.0 PCA算法学习与回顾
PCA 是一种最常用的降维方法,在周志华老师的《机器学习》一书中给出了两种性质:
- 最近重构性:样本点到这个超平面的距离都足够近;
- 最大可分性:样本点在这个超平面上的投影都尽可能分开。
书中给出了明确推导,并认为基于最近重构性和最大可分性,能分别得到主成分分析的
两种等价推导。
2.0.1 PCA推导的优化问题

2.0.2 优化问题的解
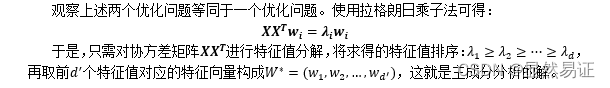
2.0.3 算法流程

2.1 人脸数据集
本次实验主要使用的人脸数据集有:
ORL56_46人脸数据集,该数据集共有40个人,每个人10张图片。每张图片像素大小为56×46。本次实验该数据集全部照片使用。
AR人脸数据集,该数据库由3个以上的数据库组成;126名受试者面部正面图像的200幅彩色图像。每个主题有26张不同的图片。对于每个受试者,这些图像被记录在两个不同的时段,间隔两周,每个时段由13张图像组成。所有图像均由同一台摄像机在严格控制的照明和视点条件下拍摄。数据库中的每个图像都是768×576像素大小,每个像素由24位RGB颜色值表示。本次实验采用前15个人的人脸子集,每个人只采用前7张未遮挡的人脸图像。
FERET人脸数据集,200人,每人7张,已分类,灰度图,80x80像素。第1幅为标准无变化图像,第2,5幅为大幅度姿态变化图像,第3,4幅为小幅度姿态变化图像。第7幅为光照变化图像。
2.2 实验流程图
三、实验步骤与过程
3.1 实验过程
在特征提取中,主成分分析是一种重要的线性变换方法,这里通过对ORL数据集进行实验来说明PCA提取人脸特征以及利用这些特征进行人脸重建的过程。最终展示20,40,60,80,…,160个投影来重构图像的效果。
1) 首先导入40×10=400张人脸,并拉成列向量,拼成一个人脸矩阵faces;
%----------导入一类人脸样本----------
faces=zeros(face_length*face_width,sample*class);
for i=1:class
for j=1:sample
p=(i-1)*10+j;
facepath = strcat('C:\Users\Vermouth\Desktop\ML\作业\ORL56_46\orl',num2str(i),'_',num2str(j),'.bmp');
face=imread(facepath);
faces(:,p)=face(:); %将人脸拉成列向量
end
end
2) 然后对人脸进行去中心化的操作,计算协方差faces_cov,对协方差矩阵进行特征值分解得到特征值和特征向量,计算出基base;
%----------pca算法----------
faces_average=mean(faces,2); %平均脸
faces_diff=faces-repmat(faces_average,1,sample*class); %减去平均脸
%计算协方差
faces_cov=faces_diff'*faces_diff;
%特征值分解
[V,D]=eig(faces_cov);
D1=diag(D);
D_sort = flipud(D1);
V_sort = fliplr(V);
base = faces_diff*V_sort(:,:)*diag(D_sort(:).^(-1/2)); %基
3) 接着取出第一个人的第一张照片(orl1_1.bmp)进行重构;
%----------对第一张图片进行重构----------
img1=strcat('C:\Users\Vermouth\Desktop\ML\作业\ORL56_46\orl1_',num2str(1),'.bmp');
test1=imread(img1);
combined1(:,1)=test1(1:face_length*face_width);
combined1=double(combined1);
dis1=combined1-faces_average; %减去平均脸
factor1=base'*dis1;
4) 投影向量归一化+结果可视化。
figure
for t=20:20:160
base_temp = base(:,1:t)*factor1(1:t);
base_temp = base_temp + faces_average;
base_temp = reshape(base_temp, face_length,face_width);
MAX=max(max(base_temp)); %求出图像矩阵中灰度值最大的值
MIN=min(min(base_temp)); %求出图像矩阵中灰度值最小的值
base_temp(:,:)=(base_temp(:,:)-MIN)/(MAX-MIN)*255; %归一化后再映射到0-255
base_temp=uint8(base_temp);
subplot(2,4,t/20);
imshow(base_temp);
end
【不建议在实验报告上粘代码,后面的实验报告不会直接粘贴代码】
3.1.2 实验效果图
对于投影矩阵,orl数据集得到以下结果:
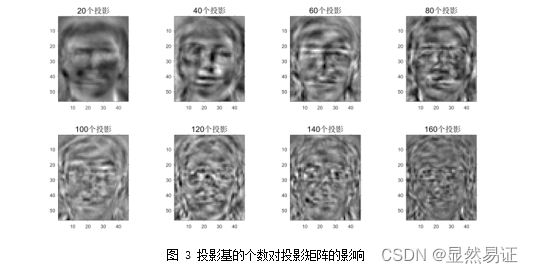
对于orl1_1.bmp人脸图像,得到了以下重构结果:

对于orl2_1.bmp人脸图像,得到了以下重构结果:

3.2 PCA算法的人脸图像降维
3.2.1 人脸图像降维步骤
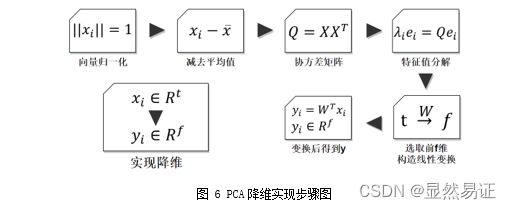
3.2.2 三个数据集降至2,3维的可视化效果图
下面展示了3个不同数据集多个子集的二维和三维空间实现数据的可视化效果:
1) ORL人脸数据集(200张人脸图像)
-
目标维度:2维
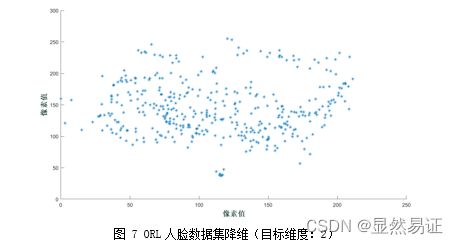
-
目标维度:3维

2) FERET_80人脸数据集 -
目标维度:2

-
目标维度:3
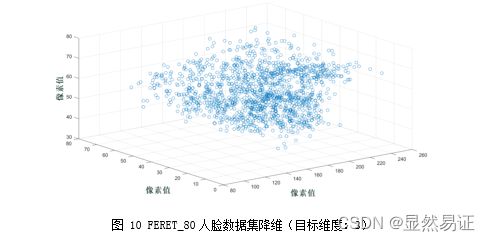
3) AR人脸数据集: -
目标维度:2
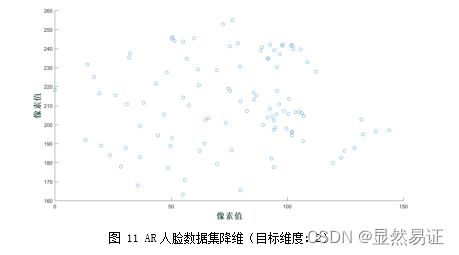
-
目标维度:3
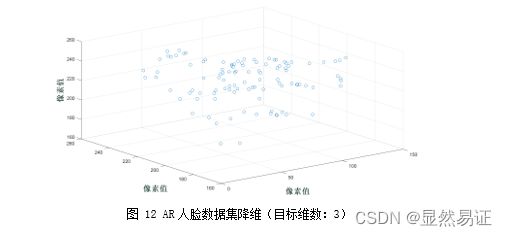
3.3 PCA+KNN 人脸识别
本次实验主要针对降维的重构阈值,训练集测试集的比例以及KNN的k设置进行考量。本次实验使用了FERET_80人脸数据集。
3.3.1 降维的重构阈值
3.3.2 人脸识别效果数据展示
3.4 设计一个新的PCA算法
【这个你们加油!!!我就不公开献丑了!!!】
四、实验结论或体会
大一可能更多的是“尽可能理解PCA并完成实验”,到了大二,并且具备了一段时间的科研经历,我可以拓展的思考PCA的优势在哪里,为什么会有这种优势,这个优势可以优化其他什么算法,PCA有什么不足,那么我可以怎么优化等。
对于实验报告的排版和书写,在经过了一年半的学习,也逐渐形成了自己的风格。比大一时会更加严谨规范。
在思考PCA优化的时候,我考虑了核函数,考虑了图像熵,甚至考虑将PCA与LBP结合,还有集成学习来提高识别率等等方法,但是没有取得一个很好的识别效果。虽然这个左右脸来优化PCA的想法比较简单,但却是我尝试了众多方法后效果较好,且复杂度降低的方法。
操作上更多的时MATLAB不会再使用a,b,c等等变量名了,大一的时候,我记得我上台分享PCA代码的时候,代码真的很“丑”,现在想想,这种代码思维还是有很大改进的。
本次PCA实验的代码比较详细,本次实验所要探讨的问题也尽可能的详细化,希望后面可以抱着科研学者的“匠心态度”对待每一件事情。 本次实验相比于大一的PCA实验而言,更多的是处于一种自己的理解和探索。
![]()