模式识别实验之PCA人脸识别
模式识别实验之PCA人脸识别(matlab实现)
- 一、实验目的
- 二、实验原理
- 三、实验步骤
- 四、matlab编程过程详解
-
- 1、PCA人脸识别的基本流程
- 2、读入ROL库数据
- 3、PCA特征提取
一、实验目的
1.通过实验加深对于PCA人脸识别过程的理解。
2.通过编程进一步提高对图像、特征向量等概念的理解。
二、实验原理
PCA方法实现人脸识别,PCA的思想在这里就不详细论述了。
三、实验步骤
1.人脸识别图像库中包含40个人的头像图片,每人10幅。将400张图像分成两组,每个人的前五张照片作为训练图像,后五张作为测试图像。读入图像,并对图像数据进行处理。
2.采用PCA方法实现本征脸方法,对特征进行降维。
3.对训练图像进行重构,观察当保留特征维数不同时,重构效果的差异。
4.对测试图像进行判别。对测试图像进行预处理,根据本征脸计算重构系数,与每一幅本征脸图像的重构系数进行比较,根据最小距离进行图像类别的判别,实现人脸识别。
四、matlab编程过程详解
1、PCA人脸识别的基本流程
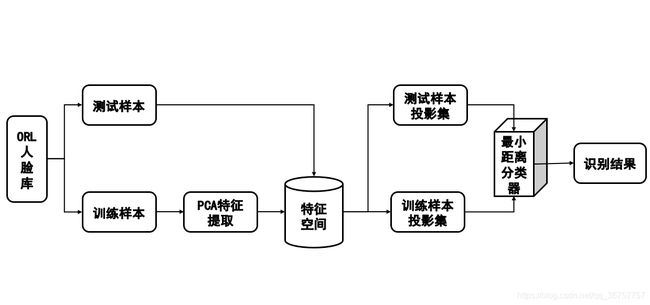
从上图中可以看出PCA人脸识别分为以下几个阶段:特征提取、构造特征空间、投影计算、分类器决策,我们的程序就是根据流程图所示编写。
2、读入ROL库数据
%测试数据:40人,每人10张照片。每人取前train_num张照片作为训练集,后(10-train_num)张照片作为测试集。
clear;
clc;
train_num=5;
%计算特征脸并创建特征空间
imdata=zeros(112*92,40*train_num);
for i=1:40
for j=1:train_num
addr=strcat('I:/模式识别/实验四/1107/orl_faces/s',num2str(i),'/',num2str(j),'.pgm');
a=imread(addr);%从地址中读入图像
b=a(1:112*92); %把图像a矩阵按列顺序转为行向量b
imdata(:,train_num*(i-1)+j)=b'; %把b的转置矩阵存放到imdata矩阵的第ph*(i-1)+j列
end
end
3、PCA特征提取
3.1得到训练集的平均脸。
首先我们需要计算这个训练集的平均脸。
%计算平均脸并显示
average_face=mean(imdata,2); %按行求平均mean(a,2) 按列mean(a)
Average_face=reshape(average_face,112,92);%将[112*92,1]的脸灰度数据转成[112,92]
figure;
subplot(1,1,1);
imshow(Average_face,[]);%imshow(I,[]) 显示灰度图像 I,根据 I 中的像素值范围对显示进行转换。
title(strcat('40*5张训练样本的平均脸'));
clear i j a b addr
运行后得到下图

这就是该库中的平均脸,平均脸和样本库有很大的关系,不同数据库得到的平均脸是不一样的。
3.2计算协方差矩阵并得到特征向量。
%图像预处理:减去平均均值
immin=zeros(112*92,40*train_num);
for i=1:40*train_num
immin(:,i) = imdata(:,i)-average_face;
end
clear i
%计算协方差矩阵
%W=immin*immin';%dxn*nxd =dxd,由N*N降为d*d
W=immin'*immin; %n*d x d*n= n*n 较小
%计算特征向量与特征值(向量)
[V,D]=eig(W);
该库中的每个特征向量是一个10304x1的向量,即仍然是一个112x92的图像,这些特征向量的图像任然具有一些人脸的特点,因此被称作“本征脸”。
下面给出了所得的部分特征脸:



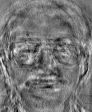

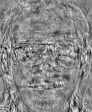
我们可以发现前面三张特征脸看上去要比后面三张特征脸“清楚”得多,也就是说前三张特征脸所包含的“信息”要比后三张所包含的“信息”多。其实这是由于这些特征向量对应的特征值的大小不同造成的,特征值越大,则人脸越“清晰”。
3.3选取部分特征值
从3.2节中我们知道有些特征脸所携带的“信息”十分少,那么我们可以将所得到的所有特征脸按照特征值的大小排序,选取累计贡献值大于85%的前neednum个特征脸,这样一来在尽可能小的影响模型精度的情况下对特征空间降维。
%对特征向量进行排序
[D_sort,index] = sort(diag(D),'descend');
SumAllFaceEigenValue=sum(D_sort);
NowFaceEigenValue=0;
%选取累计贡献大于90%的前neednum个特征脸
for i=1:size(D_sort,1)
NowFaceEigenValue=NowFaceEigenValue+D_sort(i);
neednum=i;
if(NowFaceEigenValue>SumAllFaceEigenValue*0.85)%累计贡献率达到85%以上即可
break;
end
end
V_sort = V(:,index);
VT=immin*V_sort; %dxn*nxk=d*k
for i=1:40*train_num
VT(:,i)=VT(:,i)/norm(VT(:,i));%归一化处理
end
newVT=VT(:,1:neednum);%取前neednum个特征值
(可选)我们也可以将排序后的特征脸输出保存
%显示前32个(32是为了显示方便选取的)特征脸,并保存所有的特征脸(200个)到image中(已按从大到小排序)
figure;
mkdir image % 如果文件夹已存在,会有警告,但不影响运行
for i=1:200
v=VT(:,i);
%向量矩阵化
out=reshape(v,112,92); %把(112*92)x1的列向量转成112x92的矩阵
if i<=32
subplot(4,8,i);
imshow(out,[]);
end
imwrite(mat2gray(out),strcat( 'image/test',num2str(i),'.png'));
title(strcat('Face',num2str(i)));
end
clear i v out

(中间部分图片已省略…)

我们可以看到,所有的特征脸已经按照“清晰度”(特征值)从大到小排序了。但是其实我们只需要选取累计贡献大于85%的前neednum个特征脸,于是我们把这些需要的特征脸保存到newVT中:
newVT=VT(:,1:neednum);%取前neednum个特征值
这neednum个特征向量就构成了我们需要的特征空间。
至此我们完成了计算协方差矩阵并得到特征向量,
3.4训练样本集在特征空间的投影及人脸图像的重建
face_train_projection=zeros(neednum,40*train_num);
for i=1:40*train_num
%映射训练集图像
Coefficient=newVT'*immin(:,i); %k*d x d*1=k*1;
face_train_projection(:,i)=Coefficient;
end
clear i Coefficient
根据人脸在特征空间中投影后的系数我们可以将人脸重建。根据PCA的相关知识我们可以知道当neednum等于总数(200)时,重建后的图像是的原图无差图像。
figure;
er=zeros(20,1);
%生成重建图
%建立存放目录,只需执行一次
%mkdir('I:\模式识别\实验四\Rebuild_face');
%for i=1:40
%mkdir(strcat('I:\模式识别\实验四\Rebuild_face\s',num2str(i)));
%end
for inum=1:200
people=inum;
for step=10:10:200
x=average_face;
for ii = 1:step
x=x+VT(:,ii)'*(imdata(:,people)-average_face)* VT(:,ii);
end
er(step/10)=sqrt(sum(sum((x-imdata(:,people)).^2)));
newX=reshape(x,112,92);
subplot(4,5,step/10);
set(gcf,'outerposition',get(0,'screensize'));
imshow(newX,[]);
title(strcat('选取',num2str(step),'个特征脸的重建图像'));
end
saveas(gcf,['Rebuild_face/s',num2str(ceil(inum/5)),'/','重建图',num2str(mod(inum,5)),'.tiff']);
end

我们也可以计算这过程中的误差:
%绘制误差曲线图
people=3;
for step=10:10:200
x=average_face;
for ii = 1:step
x=x+VT(:,ii)'*(imdata(:,people)-average_face)* VT(:,ii);
end
er(step/10)=sqrt(sum(sum((x-imdata(:,people)).^2)));
newX=reshape(x,112,92);
subplot(4,5,step/10);
set(gcf,'outerposition',get(0,'screensize'));
imshow(newX,[]);
title(strcat('选取',num2str(step),'个特征脸的重建图像'));
end
ER=(er-min(er))/(max(er)-min(ER));
figure;
plot(ER,'k');
set(gca, 'XTick', [0 :20]);
set(gca,'XTickLabel',[0 :10:200]) ;
xlabel('选取的特征脸数量');
ylabel('误差');
可以得到下图:
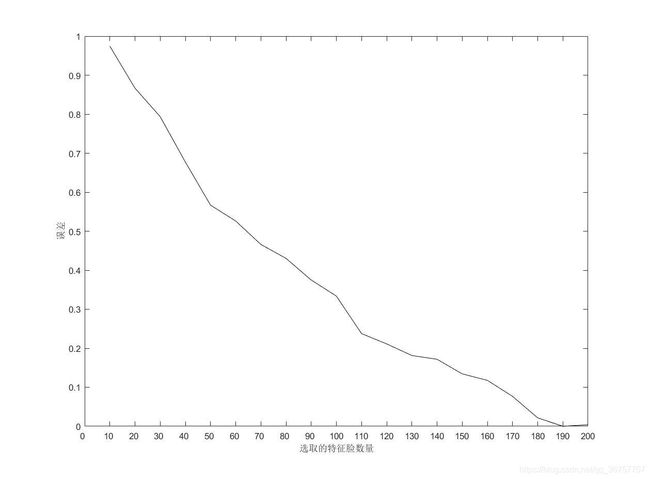
我们可以看到随着neednum的值不断增加,误差在逐渐减小。除了按照贡献度来选择neednum的大小,我们也可以根据具体误差的要求来选择合适的neednum。
3.5利用测试集测试,并得到错误率。
我们先读取测试集,并将测试集投影到特征空间中:
%读入样本数据
test=zeros(112*92,40*(10-train_num));
for i=1:40
for j=(train_num+1):10 %6到10,后五张作为测试样本
addr=strcat('I:/模式识别/实验四/1107/orl_faces/s',num2str(i),'/',num2str(j),'.pgm');
a=imread(addr);
b=a(1:112*92);
test(:,(10-train_num)*(i-1)+(j-train_num))=b';
end
end
%减去平均脸
testmin=zeros(112*92,40*(10-train_num));
for i=1:40*(10-train_num)
testmin(:,i) = test(:,i)-average_face;
end
clear i j a b addr test
face_test_projection=zeros(neednum,40*(10-train_num));
for i=1:40*(10-train_num)
%映射测试集图像
Coefficient=newVT'*testmin(:,i);
face_test_projection(:,i)=Coefficient;
end
clear i Coefficient
这样我们得到了 face_test_projection和face_train_projection这两个投影向量,对于face_test_projection中的每一列(每一张图片在投影空间是一个列向量)而言,它总能在face_train_projection中找到一个与它距离最小的一个列向量,那么我们就可以设计一个最小距离分类器来实现分类(也可以利用Fisher线性分类器,可能效果会更好一点),从而实现人类识别:
%识别,并计算错误率
error=0;%判错数
for num=1:40*(10-train_num)
class=minindex(num,face_train_projection,face_test_projection);
display(strcat('测试集中的第',num2str(num),'张图片属于类别:S',num2str(class)));
if class~=ceil(num/5)
error=error+1;
end
end
display(strcat('测试中判错数为:',num2str(error),'张,正确数为:',num2str(length(face_test_projection)-error),'张,错误率为:',num2str(100*error/length(face_test_projection)),'%'));
minindex函数:
function class=minindex(class_num,face_train_projection,face_test_projection)
distance=zeros(length(face_train_projection),1);
for p=1:length(face_train_projection)
distance(p)=normest(face_test_projection(:,class_num)-face_train_projection(:,p));
end
[num,index ]=min(distance);
class=ceil(index/5);
下面是运行结果:
》》 recognition
测试集中的第1张图片属于类别:S1
测试集中的第2张图片属于类别:S1
测试集中的第3张图片属于类别:S1
测试集中的第4张图片属于类别:S1
*
*
*
测试集中的第197张图片属于类别:S40
测试集中的第198张图片属于类别:S40
测试集中的第199张图片属于类别:S40
测试集中的第200张图片属于类别:S40
测试中判错数为:23张,正确数为:177张,错误率为:11.5%
至此,我们实现了利用PCA对ORL人脸库进行识别。