OpenCV零基础实战项目1:OCR
简述
Anaconda编译环境下,利用OpenCV和tesseract进行OCR文字识别。配置环境后,通过OpenCV的函数读取并对图像进行预处理。然后将处理好的图像进行pytesseract相关操作对字符进行识别和定位。得到字符的位置和内容信息后再通过OpenCV绘制。
目录
-
- 简述
- 1. 资源及配置
-
- 资源
- 环境配置
- 2. 单个字符识别的实现
- 3. 词汇识别
- 4. 数字的识别
1. 资源及配置
资源
代码资源:Fafa-DL/Opencv-project
视频资源:(强推)OpenCV超实用实战项目
案例图片:

环境配置
-
下载并安装
Windows:UB-Mannheim
/tesseract
解压并安装tesseract.exe,关注一下安装目录。本电脑为’D:\Install\Tessdoc\tesseract.exe’。 -
Anaconda配置
打开Anaconda prompt,输入以下命令行:conda install pytesseract若没有安装OpenCV,输入以下命令行:
conda install opencv
注:经实验想用tesseract以上两步缺一不可,有不严谨之处还请指出。
2. 单个字符识别的实现
-
导入模块
import pytesseract import cv2 as cv安装完成后为了能在cmd命令行直接使用tesseract.exe,需要指明tesseract_cmd命令的位置,方便pytesseract调用。也可以在目录中添加,可参考:pytesseract安装和基本使用
pytesseract.pytesseract.tesseract_cmd = 'D:\\Install\\Tessdoc\\tesseract.exe' -
OpenCV图像预处理
img = cv.imread('E:\\CV\\pics\\1.png') img = cv.cvtColor(img, cv.COLOR_BGR2RGB)OpenCV以BGR读入,但pytesseract只能处理RGB格式的图片。
-
tesseract字符的识别
用到函数 pytesseract.image_to_boxes(),返回字符串,每行显示一个字符的内容和位置坐标。这里的boxes是string。boxes = pytesseract.image_to_boxes(img)形如:

-
字符信息的提取
将string类的boxes转换为字符组成的list,每一个list表示一个字符。然后提取出相应的位置坐标。
for b in boxes.splitlines(): b=b.split() x,y,x1,y1 = int(b[1]), int(b[2]), int(b[3]), int(b[4])print(b)以后得到:
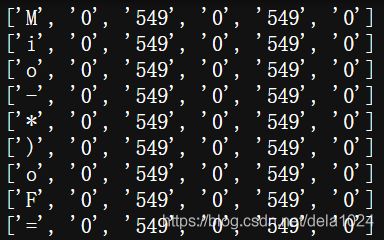
-
OpenCV绘制框和内容
框选需要用到函数cv.rectangle(),标注需要cv.putText()。下面两张图分别是boxes中字母和数字的识别结果。
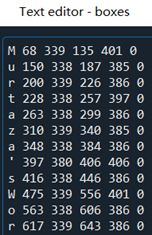
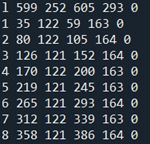
Boxes给出的坐标和绘制长方形的rectangle函数需要的参数坐标定义方式不一致,需要转换。
rectangle第二、三个参数是一组对角坐标,且坐标系是以图片的左上角点(顶部)为原点构建的。关注boxes,对比字母和数字。已知字母M在数字1上方,字母第二个坐标值却大于数字的。可知越靠近图片下方,数值越小。纵坐标从底部向上增大。
对比1的第一个坐标值和第三个坐标值,仅相差6个像素。可知第三个坐标值应该是矩形某点横坐标。而第四个坐标值大于第二个坐标值,说明其是右上角点纵坐标。
故先计算出图片的长宽:
hImg,wImg,_ = img.shape再绘制框和字符。提取和绘制的完整代码如下:
for b in boxes.splitlines(): b=b.split(' ') x,y,x1,y1 = int(b[1]), int(b[2]), int(b[3]), int(b[4]) cv.rectangle(img,(x1,hImg-y1),(x,hImg-y),(0,0,255),2) cv.putText(img,b[0],(x,hImg-y+25),cv.FONT_HERSHEY_COMPLEX,1,(50,50,255),1)
-
图片显示
cv.imshow('Result',img) cv.waitKey(0) -
完整实现
import pytesseract import cv2 as cv pytesseract.pytesseract.tesseract_cmd = 'D:\\Install\\Tessdoc\\tesseract.exe' #pretreatment img = cv.imread('E:\\CV\\pics\\1.png') img = cv.cvtColor(img, cv.COLOR_BGR2GRAY) img = cv.cvtColor(img, cv.COLOR_GRAY2RGB) #print(pytesseract.image_to_string(img)) #print(pytesseract.image_to_boxes(img)) hImg,wImg,_ = img.shape #for character boxes = pytesseract.image_to_boxes(img) for b in boxes.splitlines(): #print(b) b=b.split(' ') #print(b) x,y,x1,y1 = int(b[1]), int(b[2]), int(b[3]), int(b[4]) cv.rectangle(img,(x1,hImg-y1),(x,hImg-y),(0,0,255),2) cv.putText(img,b[0],(x,hImg-y+25),cv.FONT_HERSHEY_COMPLEX,1,(50,50,255),1) cv.imshow('Result',img) cv.waitKey(0)
3. 词汇识别
用到函数pytesseract.image_to_data(),相较于pytesseract.image_to_boxes()可以获得更多信息。
运行
boxes = pytesseract.image_to_data(img)
得到boxes内容为:
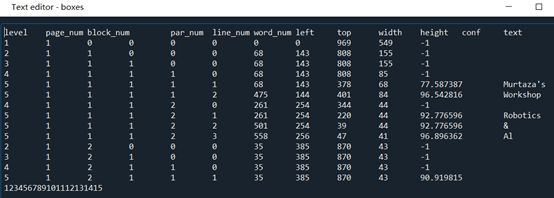
观察可知,不需要第一行的信息。最后一列text即识别出的word。仅需绘制出有12个元素的对应信息。
此时,6、7、8和9(标号而不是第几个)给出的坐标值是左上x,y和宽、高。
识别与绘制部分代码如下:
#for words
boxes = pytesseract.image_to_data(img)
for x,b in enumerate(boxes.splitlines()):
if x!=0:
b=b.split()
if len(b)==12:
x,y,w,h = int(b[6]), int(b[7]), int(b[8]), int(b[9])
cv.rectangle(img,(x,y),(x+w,y+h),(0,0,255),3)
cv.putText(img,b[-1],(x,y-5),cv.FONT_HERSHEY_PLAIN,1.5,(50,50,255),2)
注意到x变量和enumerate()是为了排除第一行(0行)的干扰。

4. 数字的识别
对pytesseract.image_to_boxes()限制检测范围,数字digits。
声明一个命令:
cong=r'--oem 3 --psm 6 outputbase digits'
其中,–oem 3:

–psm 6
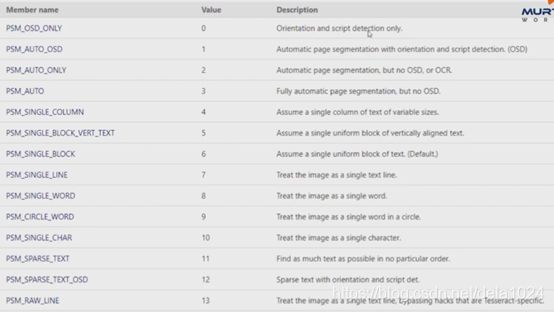
digits表示数字
识别与绘制部分代码如下:
cong = r'oem 2 --psm 6 outputbase digits'
boxes = pytesseract.image_to_boxes(img, config=cong)
for b in boxes.splitlines():
b=b.split()
print(b)
x,y,x1,y1 = int(b[1]), int(b[2]), int(b[3]), int(b[4])
cv.rectangle(img,(x1,hImg-y1),(x,hImg-y),(0,0,255),2)
cv.putText(img,b[0],(x,hImg-y+25),cv.FONT_HERSHEY_COMPLEX,1,(50,50,255),1)
