【深度学习 一】activation function以及loss function理解
一 首先线性回归模型: 可以看成是单层神经网络

二 引入非线性元素,使神经网络可以完成非线性映射,就引入了sigmoid,ReLU,softmax等激活函数
Sigmoid函数
Sigmoid =多标签分类问题=多个正确答案=非独占输出(例如胸部X光检查、住院)。构建分类器,解决有多个正确答案的问题时,用Sigmoid函数分别处理各个原始输出值。
Sigmoid函数是一种logistic函数,它将任意的值转换到[0,1]之间,如图1所示,函数表达式为:
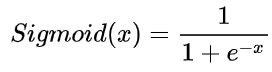
这里的x可以为向量y:

优点:1. Sigmoid函数的输出在(0,1)之间,可以用作输出层,可以输出多个类别。2. 连续函数,便于求导。
缺点:1. 其两侧导数逐渐趋近于0,容易造成梯度消失。2.激活函数的偏移现象。Sigmoid函数的输出值均大于0,使得输出不是0的均值,这会导致后一层的神经元将得到上一层非0均值的信号作为输入,这会对梯度产生影响。 3. 计算复杂度高,因为Sigmoid函数是指数形式。
Softmax函数
Softmax =多类别分类问题=只有一个正确答案=互斥输出(例如手写数字,鸢尾花)。构建分类器,解决只有唯一正确答案的问题时,用Softmax函数处理各个原始输出值。Softmax函数的分母综合了原始输出值的所有因素,所以softmax各向量元素的和为1。
Softmax函数,又称归一化指数函数,函数表达式为: ![[公式]](http://img.e-com-net.com/image/info8/2abf9a70af9a4525af51e53bc174e65b.jpg)
同理,softmax的输入参数x也是![]()
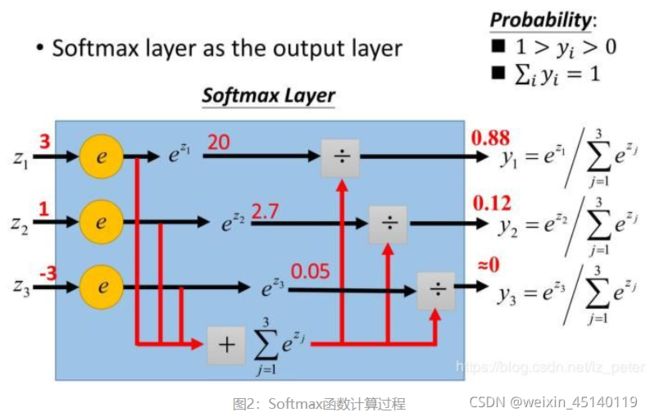
直白的说,就是将输入的参数归一化为(0,1)的值,并且这些值和为1,这样就可以把它理解为是概率,就可以选取概率最大的结点,作为分类的结果。
注:由于Softmax函数先拉大了输入向量元素之间的差异(通过指数函数),然后才归一化为一个概率分布,在应用到分类问题时,它使得各个类别的概率差异比较显著,最大值产生的概率更接近1,这样输出分布的形式更接近真实分布。
注:softmax可以当作arg max的一种平滑近似,与arg max操作中暴力地选出一个最大值(产生一个one-hot向量)不同,softmax将这种输出作了一定的平滑,即变成取了最大的概率。
计算过程:
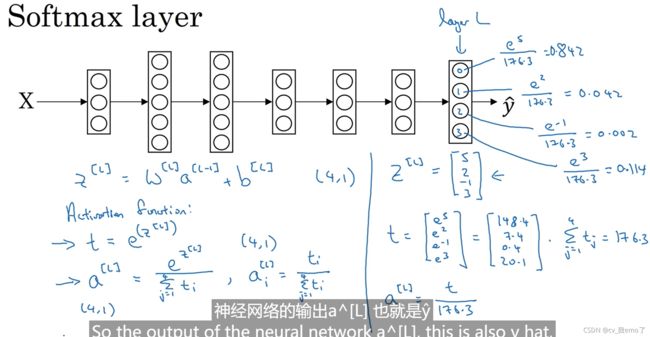
sigmoid和softmax总结
- 如果模型输出为非互斥类别,且可以同时选择多个类别,则采用Sigmoid函数计算该网络的原始输出值。
- 如果模型输出为互斥类别,且只能选择一个类别,则采用Softmax函数计算该网络的原始输出值。
- Sigmoid函数可以用来解决多标签问题,Softmax函数用来解决单标签问题。
- 对于某个分类场景,当Softmax函数能用时,Sigmoid函数一定可以用。
- sigmoid一般做二分类任务,softmax一般做多分类任务。
ReLU函数
ReLU函数是目前比较火的一个激活函数,函数公式: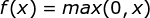 ,函数图像如下
,函数图像如下
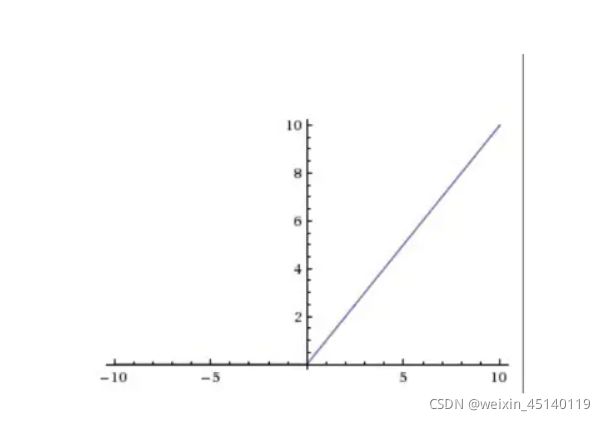
相比sigmod函数与tanh函数有以下几个优点
1)克服梯度消失的问题
2)加快训练速度
注:正因为克服了梯度消失问题,训练才会快
缺点:
1)输入负数,则完全不激活,ReLU函数死掉。
2)ReLU函数输出要么是0,要么是正数,也就是ReLU函数不是以0为中心的函数
深度学习中最大的问题是梯度消失问题,使用tanh、sigmod等饱和激活函数情况下特别严重(神经网络在进行方向误差传播时,各个层都要乘以激活函数的一阶导数,梯度每传递一层就会衰减一层,网络层数较多时,梯度G就会不停衰减直到消失),使得训练网络收敛越来越慢,而ReLU函数凭借其线性、非饱和的形式,训练速度则快很多。
为什么说Relu是非线性激活函数
一开始我也觉得在大于0部分不是线性的吗?看博客得到了答案

显然,ReLU的导数不是常数,所以ReLU是非线性的。
常见的损失函数(loss function)
平方损失函数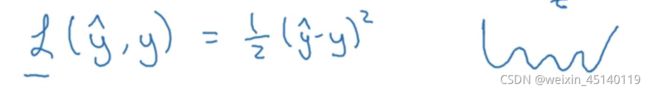
交叉熵损失函数 (Cross-entropy loss function)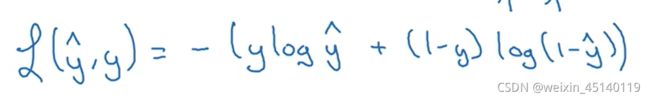
本质上也是一种对数似然函数,可用于二分类和多分类任务:
binary_crossentropy

categorical_crossentropy

均方误差损失(MSE)

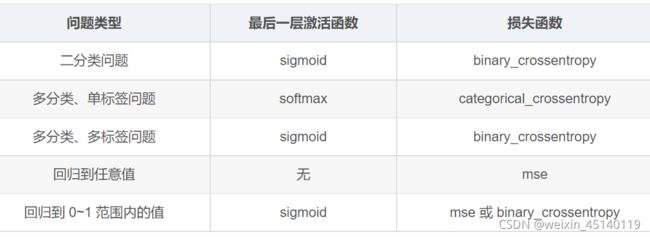
sigmoid和softmax一般用于最后一层网络,ReLU用于中间层防止梯度消失。
梯度下降
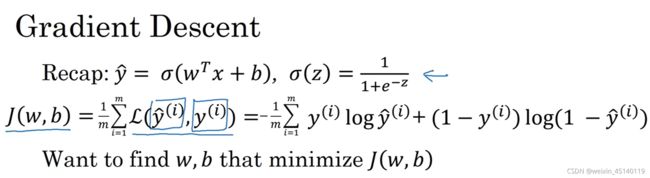
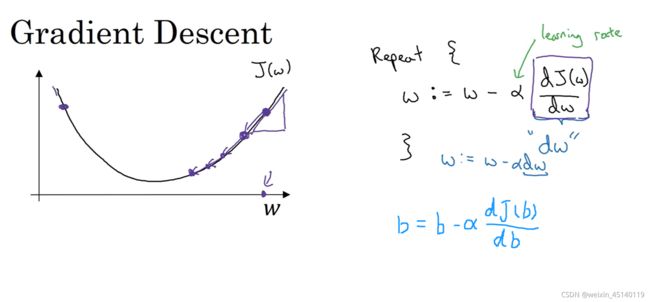
J(w,b)就是loss,也就是真实值和预测值的比较,越小越好,所以我们想要得到梯度最低的那个点。通过更新权重w、b来实现梯度下降,如上图w=w-α(dw),dw就是w对J(w,b)的偏导,J(w)在最低点的右边,所以偏导dw大于0,所以w=w-α(dw)会减小,慢慢向最低点靠拢。同理b=b-α(db)。这样就完成了对w、b的权重更新,最终会得到一个权重使得预测值最近似于真实值。

反向传播的过程:

就是通过求导一步步求出dw,L(a,t)→da→dz→dw。
向量化:代替for循环,可以大量的节省计算性能和时间。
for循环:
z=0
for i in range(n_x):
z+=w[i]*x[i]
z+=bvectorized:
import numpy as np
z=np.dot(w,x)速度对比:
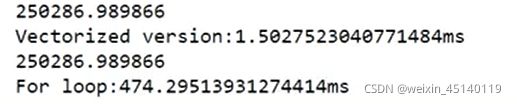
所以你的代码要避免用for循环,越少越好。
python广播容易引起一些bug,所以定义numpy尽量定义为矩阵:

多层神经网络:
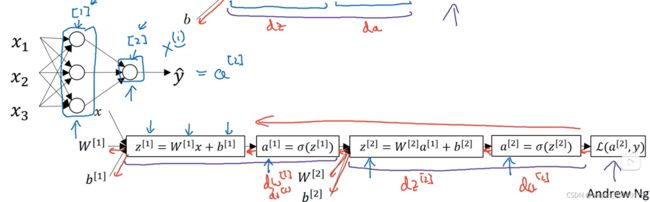
第一层[1]输入的是x,w[1],b[1],输出的是a[1],代表第一层的a。
第二层[2]输入的是a[1],w[2],b[2],输出的是a[2],代表第二层的a。
得到最后一层的loss再一步步向前传播得到更新后的w1,b1,再进行下一轮的运算。
多样本:

随机初始化:
如果初始化w都为0,那么每层的w都是对称的,也就是每行的w都一样,那样深层网络就没有意义了。一般随机初始化为很小的数。
b没有影响,所以可以初始化为0。
w[1]=np.random.randn((2,2))*0.01
b[1]=np.zeros((2,1))
w[2]=np.random.randn((1,2))*0.01
b[2]=0
参考博客:softmax,sigmoid函数在使用上的区别是什么? - 知乎
深度学习中常见的激活函数与损失函数的选择与介绍_DDB-CSDN博客_激活函数的选择
[双语字幕]吴恩达深度学习deeplearning.ai_哔哩哔哩_bilibili等