【综合案例】信用评分模型开发
目录
- 一、案例背景
- 二、前置知识
-
- 2.1 数据分箱
- 2.2 属性选择
- 2.3 回归方程
- 三、数据处理
-
- 3.1 数据清洗
- 3.2 因素分析
- 四、模型训练
- 五、模型预测
- 六、结语
- 后记
一、案例背景
在上一篇文章网络贷款违约预测案例中,我们在分析属性关系时发现:FICO信用评分与分类标签之间存在极强的相关关系。如果说要选择一个属性来区分客户是否违约贷款的话,FICO评分是最理想之选。
FICO评分的主要思路是:对大量拥有多个属性的用户数据进行收集、分析、转换,使用各项统计指标对属性进行取舍、赋权、组合,最终得到一个量化的、综合的、可用于比对的分值。分值的高低既反映了用户历史信用记录的好坏,又暗示未来违约可能性的大小。
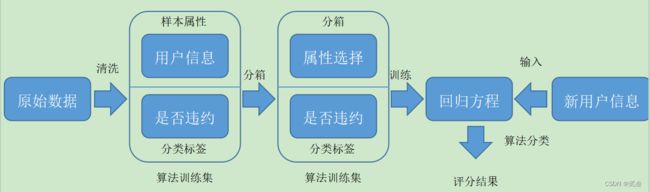
类似的,我们要对数据清洗之后才能进行模型训练和预测。其中,首先要重点说到的是数据分箱。
二、前置知识
2.1 数据分箱
数据分箱就是将采集到的某一个属性的数据取值划分为若干段,落在同一个箱体范围内的数据,用一个统一的数字代替。例如,{1,2,3,4,5,6,7,8,9}这个数据集,若分为3段,则1:{1,2,3}、2:{4,5,6}、3:{7,8,9};取均值代替原来的数据,最终为:箱1:{2,2,2}、箱2:{5,5,5}、箱1:{8,8,8}。
数据分箱的目的是:变量变换到了相似的尺度上,便于比较;后续逻辑回归计算量减少,降低模型过拟合风险;模型更稳定,不会因为少量数据的变化导致结果大幅波动。
2.2 属性选择
在数据分析中,为了降低复杂度,往往要对数据集中的属性进行取舍,排除冗杂多余的属性,除了相关关系之外,还可以用Woe(迹象权重)和IV(信息值)指标来考察属性对目标变量的重要程度。
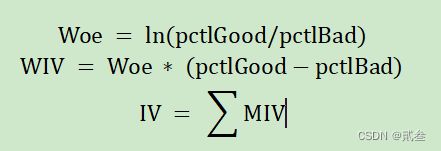
其中,pctlGood(pctlBad)表示好的、分类标签为正常的(坏的、分类标签为违约的)占所有的比重。
然后根据IV的取值来判断研究的属性与目标变量之间的关系:
| IV | 关系 |
|---|---|
| (0,0.02) | 极弱 |
| [0.02,0.1) | 弱 |
| [0.1,0.3) | 一般 |
| [0.3,0.5) | 强 |
| [0.5,1.0) | 极强 |
最后,根据自己的需求,舍弃关系为弱以下或极弱的属性。
2.3 回归方程
由于信用评分是一个数值,二分类标签是正常/违约这样离散的量,因此需要用到之前逻辑回归中学习到的Sigmoid函数:
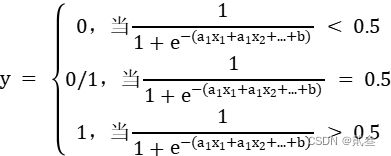
将连续值结果与阀值大小对比的结果转化为离散的分类标签,以此为基础得到用于计算信用评分的表达式。
三、数据处理
案例数据下载地址为:https://www.kaggle.com/c/GiveMeSomeCredit/data
数据包含11个属性:
| 变量名称 | 变量描述 | 数据类型 |
|---|---|---|
| SeriousDlqin2yrs | 逾期90天及以上 | 布尔值 |
| RevolvingUtilizationOfUnsecuredLines | 信用卡和个人信用额度的总余额除以总信用额度,除了房地产和没有分期付款债务,如汽车贷款 | 浮点型 |
| age | 借款人的年龄 | 整数型 |
| NumberOfTime30-59DaysPastDueNotWorse | 借款人逾期处于到期日后30-59天内的逾期次数 | 整数型 |
| DebtRatio | 每月还债、赡养费和生活费除以月总收入 | 浮点型 |
| MonthlyIncome | 月收入 | 整数型 |
| NumberOfOpenCreditLinesAndLoans | 贷款数量,如分期付款,汽车贷款或抵押贷款以及信用贷款(如信用卡) | 整数型 |
| NumberOfTimes90DaysLate | 借款人逾期90天或以上的次数 | 整数型 |
| NumberRealEstateLoansOrLines | 抵押贷款和房地产贷款的数目,包括房屋净值信贷额度 | 整数型 |
| NumberOfTime60-89DaysPastDueNotWorse | 借款人逾期处于到期日后60-89天的逾期次数 | 整数型 |
| NumberOfDependents | 家庭中不包括自己的受抚养人数(配偶、子女等) | 整数型 |
其中,第一项为分类标签,其他为变量参数。
3.1 数据清洗
首先,观察数据:
data = pd.read_csv('ch17_cs_training.csv')
print('原始数据概况:')
data.info()
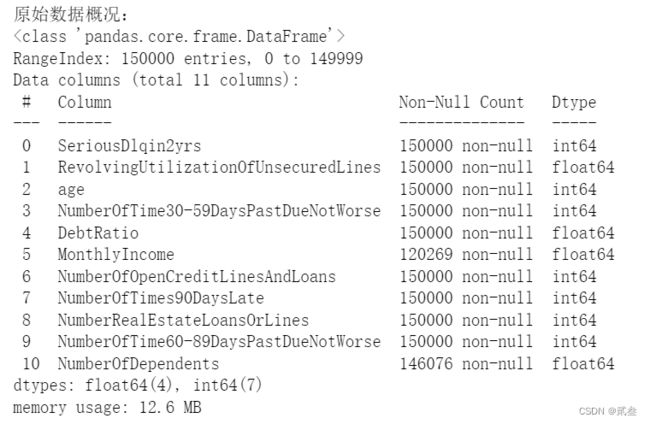
发现部分属性数据缺失严重,需要进行处理:
from sklearn.ensemble import RandomForestRegressor
# 用随机森林对MonthlyIncome月收入缺失值进行预测填充
#参数: df-Daraframe,Pandas数据框
#返回值:df-Daraframe,填充了MonthlyIncome缺失值的数据框
def set_missing(df):
#将第5列MonthlyIncome提前到第0列,便于后续划分数据
print('随机森林回归填充0值:')
process_df = df.iloc[:,[5,0,1,2,3,4,6,7,8,9]]
#分成有数值/缺失值两组
known = process_df.loc[process_df['MonthlyIncome']!=0].values
unknown = process_df.loc[process_df['MonthlyIncome']==0].values
X = known[:, 1:]
y = known[:, 0]
#用X,y训练随机森林回归算法
rfr = RandomForestRegressor(random_state=0, n_estimators=200,max_depth=3,n_jobs=-1)
rfr.fit(X,y)
#得到的模型进行缺失值预测
predicted = rfr.predict(unknown[:, 1:]).round(0)
#用得到的预测结果填补原缺失数据
df.loc[df['MonthlyIncome']==0, 'MonthlyIncome'] = predicted
return df
这里选择了用随机森林回归算法对缺失值进行填充。
#离群点检测、删除,删除标准为:
#最小阈值=第一四分位点-1.5*(第三四分位点-第一四分位点)
#最大阈值=第三四分位点+1.5*(第三四分位点-第一四分位点)
#小于最小阈值,大于最大阈值的行将会被删除
#参数: df-Daraframe,Pandas数据框
# cname-字符串,进行离群点删除的列名
#返回值:df-Daraframe,完成了离群点检测删除的数据框
def outlier_processing(df,cname):
s=df[cname]
oneQuoter=s.quantile(0.25)
threeQuote=s.quantile(0.75)
irq=threeQuote-oneQuoter
min=oneQuoter-1.5*irq
max=threeQuote+1.5*irq
df=df[df[cname]<=max]
df=df[df[cname]>=min]
return df
然后,定义函数对属性中的离群数据点(异常值)进行删除,如对MonthlyIncome列进行处理:
#对MonthlyIncome列进行数据整理
print('MonthlyIncome属性离群点原始分布:')
data[['MonthlyIncome']].boxplot()
plt.savefig('ch17_cs01.png', dpi=300, bbox_inches='tight')
plt.show()
print('删除离群点、填充缺失数据:')
data=outlier_processing(data,'MonthlyIncome')
data=set_missing(data)
print('处理MonthlyIncome后数据概况:')
data.info()
data[['MonthlyIncome']].boxplot()
plt.savefig('ch17_cs02.png', dpi=300, bbox_inches='tight')
plt.show()


同样,也可对其他的属性进行处理,但是如果处理之后发现被错误的删除大量的数据,则不能用函数处理,需要手工处理:
#以下三个属性取值过于集中,三个四分位点的值都相等。
#直接使用outlier_processing函数会导致所有取值被删除,
#因此观察分布后,手工处理
Features=['NumberOfTime30-59DaysPastDueNotWorse',
'NumberOfTime60-89DaysPastDueNotWorse',
'NumberOfTimes90DaysLate']
Features_labale=['30-59Days','60-89Days','90+Days']
print('NumberOfTime30-59DaysPastDueNotWorse,\
NumberOfTime60-89DaysPastDueNotWorse,\
NumberOfTimes90DaysLate原始分布:')
data[Features].boxplot()
plt.xticks([1,2,3],Features_labale)
plt.savefig('ch17_cs03.png', dpi=300, bbox_inches='tight')
plt.show()
print('删除离群点后:')
data= data[data['NumberOfTime30-59DaysPastDueNotWorse'] < 90]
data= data[data['NumberOfTime60-89DaysPastDueNotWorse'] < 90]
data= data[data['NumberOfTimes90DaysLate'] < 90]
data[Features].boxplot()
plt.xticks([1,2,3],Features_labale)
plt.savefig('ch17_cs04.png',dpi=300, bbox_inches='tight')
plt.show()
print('处理离群点后后数据概况:')
data.info()

3.2 因素分析
数据处理之后,就得到了可以使用的数据集,首先,先划分测试集与训练集:
#测试集与训练集生成
from sklearn.model_selection import train_test_split
#SeriousDlqin2yrs原始值为0表示正常,为1表示违约
#而习惯上信用评分越高的,违约可能越小
#因此将该值转置,原值0的,置为1;原值1的,置为0
data['SeriousDlqin2yrs']=1-data['SeriousDlqin2yrs']
Y = data['SeriousDlqin2yrs']
X = data.iloc[:, 1:]
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=0)
# print(Y_train)
train = pd.concat([Y_train, X_train], axis=1)
test = pd.concat([Y_test, X_test], axis=1)
clasTest = test.groupby('SeriousDlqin2yrs')['SeriousDlqin2yrs'].count()
print('训练集数据:')
print(train.shape)
print('测试集数据:')
print(test.shape)

然后进行数据分箱处理:
#指定数量进行分箱,并计算WOE和IV
#参数: res-series,dataframe中的结果列
# feat-series,dataframe中的属性列
# n-数值,分箱数量,默认为10
#返回值:v_feature-Daraframe,含有用于计算WOE和IV的数值
# iv-数值,IV结果
# cut-List列表,分箱数据
# woe-List列表,
def mono_bin(res, feat, n = 10):
good=res.sum()
bad=res.count()-good
d1 = pd.DataFrame({'feat': feat, 'res': res, 'Bucket': pd.cut(feat, n)})
d2 = d1.groupby('Bucket', as_index = True)
d3 = pd.DataFrame(d2.feat.min(), columns = ['min'])
d3['min']=d2.min().feat
d3['max'] = d2.max().feat
d3['sum'] = d2.sum().res
d3['total'] = d2.count().res
d3['rate'] = d2.mean().res
d3['woe']=np.log((d3['rate']/(1-d3['rate']))/(good/bad))
d3['goodattribute']=d3['sum']/good
d3['badattribute']=(d3['total']-d3['sum'])/bad
iv=((d3['goodattribute']-d3['badattribute'])*d3['woe']).sum()
d4 = (d3.sort_values(by = 'min'))
cut=[]
cut.append(float('-inf'))#负无穷大
for i in range(1,n):
qua=feat.quantile(i/(n))
cut.append(round(qua,4))
cut.append(float('inf'))#正无穷大
woe=list(d4['woe'].round(3))
return d4,iv,cut,woe
#指定间隔进行分箱,并计算WOE和IV
#参数: res-series,dataframe中的结果列
# feat-series,dataframe中的属性列
# cat-List列表,分箱数值
#返回值:v_feature-Daraframe,含有用于计算WOE和IV的数值
# iv-数值,IV结果
# woe-List列表,
def self_bin(res,feat,cat):
good=res.sum()
bad=res.count()-good
d1=pd.DataFrame({'feat':feat,'res':res,'Bucket':pd.cut(feat,cat)})
d2=d1.groupby('Bucket', as_index = True)
d3 = pd.DataFrame(d2.feat.min(), columns=['min'])
d3['min'] = d2.min().feat
d3['max'] = d2.max().feat
d3['sum'] = d2.sum().res
d3['total'] = d2.count().res
d3['rate'] = d2.mean().res
d3['woe'] = np.log((d3['rate'] / (1 - d3['rate'])) / (good / bad))
d3['goodattribute'] = d3['sum'] / good
d3['badattribute'] = (d3['total'] - d3['sum']) / bad
iv = ((d3['goodattribute'] - d3['badattribute']) * d3['woe']).sum()
d4 = (d3.sort_values(by='min'))
woe = list(d4['woe'].round(3))
return d4,iv,woe
这里的两个函数都是对属性进行分箱处理,区别在于第一个指定分箱数量,第二个指定分箱间隔。然后对数据进行指定分箱数量操作:
#对第1、2、4、5列数据进行10段分箱
pinf = float('inf')#正无穷大
ninf = float('-inf')#负无穷大
dfx1, ivx1,cutx1,woex1=mono_bin(train['SeriousDlqin2yrs'],
train['RevolvingUtilizationOfUnsecuredLines'],n=10)
#显示RevolvingUtilizationOfUnsecuredLines分箱和woe信息,限于篇幅,其他列不逐一显示
print("=" * 60)
print('RevolvingUtilizationOfUnsecuredLines分箱,woe信息:')
print(dfx1)
dfx2, ivx2,cutx2,woex2=mono_bin(train['SeriousDlqin2yrs'],train['age'], n=10)
dfx4, ivx4,cutx4,woex4 =mono_bin(train['SeriousDlqin2yrs'],
train['DebtRatio'], n=10)
dfx5, ivx5,cutx5,woex5 =mono_bin(train['SeriousDlqin2yrs'],
train['MonthlyIncome'], n=10)

对数据进行指定分箱间隔操作:
#对第3、6、7、8、9、10列数据进行指定间隔分箱
cutx3 = [ninf, 0, 1, 3, 5, pinf]
cutx6 = [ninf, 1, 2, 3, 5, pinf]
cutx7 = [ninf, 0, 1, 3, 5, pinf]
cutx8 = [ninf, 0,1,2, 3, pinf]
cutx9 = [ninf, 0, 1, 3, pinf]
cutx10 = [ninf, 0, 1, 2, 3, 5, pinf]
dfx3,ivx3,woex3= self_bin(train['SeriousDlqin2yrs'],
train['NumberOfTime30-59DaysPastDueNotWorse'], cutx3)
#显示NumberOfTime30-59DaysPastDueNotWorse分箱和woe信息,
#限于篇幅,其他列不逐一显示
print("=" * 60)
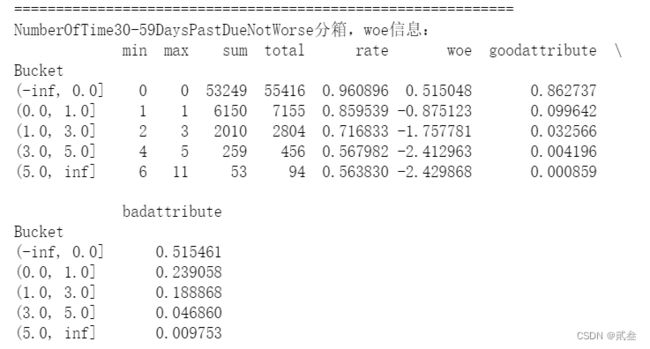
print('NumberOfTime30-59DaysPastDueNotWorse分箱,woe信息:')
print(dfx3)
dfx6,ivx6 ,woex6= self_bin(train['SeriousDlqin2yrs'],
train['NumberOfOpenCreditLinesAndLoans'], cutx6)
dfx7,ivx7,woex7= self_bin(train['SeriousDlqin2yrs'],
train['NumberOfTimes90DaysLate'], cutx7)
dfx8,ivx8,woex8= self_bin(train['SeriousDlqin2yrs'],
train['NumberRealEstateLoansOrLines'], cutx8)
dfx9,ivx9,woex9= self_bin(train['SeriousDlqin2yrs'],
train['NumberOfTime60-89DaysPastDueNotWorse'], cutx9)
dfx10,ivx10,woex10= self_bin(train['SeriousDlqin2yrs'],
train['NumberOfDependents'], cutx10)
最后,计算IV值:
#按照IV选取属性
ivlist=[ivx1,ivx2,ivx3,ivx4,ivx5,ivx6,ivx7,ivx8,ivx9,ivx10]
index=['x1','x2','x3','x4','x5','x6','x7','x8','x9','x10']
fig1 = plt.figure(1)
ax1 = fig1.add_subplot(1, 1, 1)
x = np.arange(len(index))+1
ax1.bar(x, ivlist, width=0.4)
ax1.set_xticks(x)
ax1.set_xticklabels(index, rotation=0, fontsize=12)
ax1.set_ylabel('IV(Information Value)', fontsize=14)
for a, b in zip(x, ivlist):
plt.text(a, b + 0.01, '%.4f' % b, ha='center', va='bottom', fontsize=10)
plt.savefig('ch17_cs05.png', dpi=300, bbox_inches='tight')
plt.show()

根据IV的大小即属性与目标变量的强弱关系,选择对应的属性即可。
四、模型训练
将原始数据转化为相应的woe值,可以提高模型训练的效果:
#将原始数据转化为相应的woe值,用于计算信用得分
#参数: feat-series,dataframe中的属性列
# cut-List列表,该属性的分箱数值
# woe-List列表,该属性的woe值
#返回值:res-List列表,输入的属性列对应的woe数值列
def get_woe(feat,cut,woe):
res=[]
for row in feat.iteritems():
value=row[1]
j=len(cut)-2
m=len(cut)-2
while j>=0:
if value>=cut[j]:
j=-1
else:
j -=1
m -= 1
res.append(woe[m])
return res
根据函数,将训练集和测试集所有的数据进行转化,然后进行训练:
import statsmodels.api as sm
from sklearn.metrics import roc_curve, auc
Y=woe_train['SeriousDlqin2yrs']
X=woe_train.drop(['SeriousDlqin2yrs','DebtRatio',
'MonthlyIncome','NumberOfOpenCreditLinesAndLoans',
'NumberRealEstateLoansOrLines','NumberOfDependents'],axis=1)
X1=sm.add_constant(X)
logit=sm.Logit(Y,X1)
Logit_model=logit.fit()
print('输出拟合的各项系数:')
print(Logit_model.params)

计算模型的准确率:
Y_test = woe_test['SeriousDlqin2yrs']
X_test = woe_test.drop(['SeriousDlqin2yrs', 'DebtRatio', 'MonthlyIncome',
'NumberOfOpenCreditLinesAndLoans',
'NumberRealEstateLoansOrLines',
'NumberOfDependents'], axis=1)
X3 = sm.add_constant(X_test)
resu = Logit_model.predict(X3)
fpr, tpr, threshold = roc_curve(Y_test, resu)
rocauc = auc(fpr, tpr)
plt.plot(fpr, tpr, 'b', label='AUC = %0.2f' % rocauc)
plt.legend(loc='lower right')
plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0, 1])
plt.ylim([0, 1])
plt.ylabel('真正率')
plt.xlabel('假正率')
plt.savefig('ch17_cs06.png', dpi=300, bbox_inches='tight')
print('模型AUC曲线:')
plt.show()
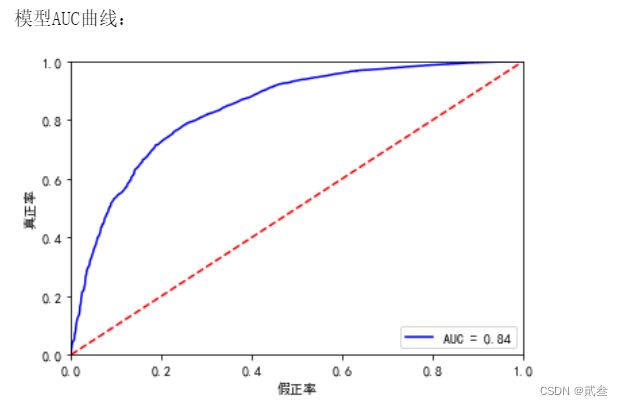
AUC值为0.84,说明算法还是可以的。
五、模型预测
最后就是模型预测部分了:
因为前面进行了数据分箱操作,所以接下来只需要对各个分段区间的分数进行计算。
#根据woe分段,计算某一列属性的woe取值所对应的分数分段取值
#参数: coe-数值,Logit模型计算得到的该列属性对应的系数
# woe-List列表,该属性的woe值
# factor-数值,调整系数
#返回值:scores-List列表,每一个woe分段对应的分数
def get_score(coe,woe,factor):
scores=[]
for w in woe:
score=round(coe*w*factor,0)
scores.append(score)
return scores
import math
#coe为逻辑回归模型的系数
coe=Logit_model.params
# 我们取600分为基础分值,调整方法见参考文献《信用评分卡模型的建立》
p = 20 / math.log(2)
q = 600 - 20 * math.log(20) / math.log(2)
#q = 600 - 20 * math.log(50) / math.log(2)
baseScore = round(q + p * coe[0], 0)
#各列分箱对应分数
x1 = get_score(coe[1], woex1, p)
print('第1列属性取值在各分箱段对应的分数')
print(x1)
#限于篇幅,其他列不逐一显示
x2 = get_score(coe[2], woex2, p)
x3 = get_score(coe[3], woex3, p)
x7 = get_score(coe[4], woex7, p)
x9 = get_score(coe[5], woex9, p)

然后根据数据的取值及其对应区间的分数,计算各个客户信息每一个属性的分数,再汇总成总分,就得到了客户的信用评分了。
#根据属性取值,计算其对应的分数
#参数: feat-series,dataframe中的属性列
# cut-List列表,该属性的分箱数值
# score-List列表,该属性woe分段对应的分数(来自get_score函数)
#返回值:res-List列表,输入的属性列对应的woe数值列
def compute_score(feat,cut,score):
res = []
for row in feat.iteritems():
value=row[1]
j=len(cut)-2
m=len(cut)-2
while j>=0:
if value>=cut[j]:
j=-1
else:
j -=1
m -= 1
res.append(score[m])
return res
#计算分数
test['BaseScore']=np.zeros(len(test))+baseScore
test['x1'] = compute_score(test['RevolvingUtilizationOfUnsecuredLines'],
cutx1, x1)
test['x2'] = compute_score(test['age'], cutx2, x2)
test['x3'] = compute_score(test['NumberOfTime30-59DaysPastDueNotWorse'],
cutx3, x3)
test['x7'] = compute_score(test['NumberOfTimes90DaysLate'], cutx7, x7)
test['x9'] = compute_score(test['NumberOfTime60-89DaysPastDueNotWorse'],
cutx9, x9)
test['Score'] = test['x1'] + test['x2'] + test['x3'] + test['x7'] +test['x9'] \
+baseScore
同时,可以对计算出来的正常/违约客户信用分数的分布进行展示:
#考察正常/违约用户的信用评分分数分布情况
Normal = test.loc[test['SeriousDlqin2yrs']==1]
Charged = test.loc[test['SeriousDlqin2yrs']==0]
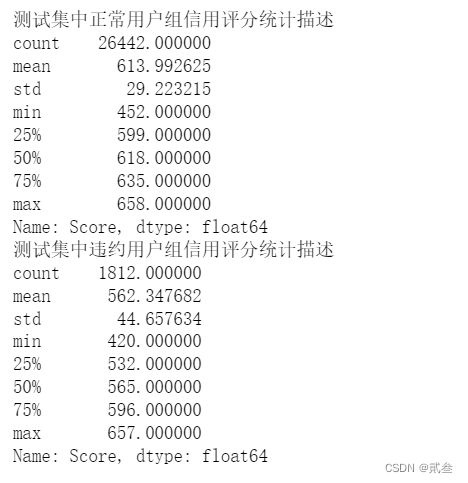
print('测试集中正常用户组信用评分统计描述')
print(Normal['Score'].describe())
print('测试集中违约用户组信用评分统计描述')
print(Charged['Score'].describe())
import seaborn as sns;
plt.figure(figsize=(10,4))
sns.kdeplot(Normal['Score'],label='正常',linewidth=2,linestyle='--')
sns.kdeplot(Charged['Score'],label='违约',linewidth=2,linestyle='-')
plt.xlabel('Score',fontdict={'size':10})
plt.ylabel('概率',fontdict={'size':10})
plt.title('测试集正常/违约客户分数分布',fontdict={'size':18})
plt.savefig('ch19_cs07.png', dpi=300, bbox_inches='tight')
plt.show()

通过上面的计算方法,我们也就可以对新客户的信用分进行计算预测了。
#计算单个客户的信用评分
custInfo={'RevolvingUtilizationOfUnsecuredLines':0.248537,
'age':48,
'NumberOfTime30-59DaysPastDueNotWorse':0,
'DebtRatio':0.177586,
'MonthlyIncome':4166,
'NumberOfOpenCreditLinesAndLoans':11,
'NumberOfTimes90DaysLate':0,
'NumberRealEstateLoansOrLines':1,
'NumberOfTime60-89DaysPastDueNotWorse':0,
'NumberOfDependents':0}
custData = pd.DataFrame(custInfo,pd.Index(range(1)))
custData.drop(['DebtRatio', 'MonthlyIncome',
'NumberOfOpenCreditLinesAndLoans','NumberRealEstateLoansOrLines',
'NumberOfDependents'], axis=1)
custData['x1'] = compute_score(custData['RevolvingUtilizationOfUnsecuredLines'],
cutx1, x1)
custData['x2'] = compute_score(custData['age'], cutx2, x2)
custData['x3'] = compute_score(custData['NumberOfTime30-59DaysPastDueNotWorse'],
cutx3, x3)
custData['x7'] = compute_score(custData['NumberOfTimes90DaysLate'], cutx7, x7)
custData['x9'] = compute_score(custData['NumberOfTime60-89DaysPastDueNotWorse'],
cutx9, x9)
custData['Score'] = custData['x1'] + custData['x2'] + custData['x3'] + custData['x7'] +custData['x9'] + baseScore
print('该客户的信用评分为:')
print(custData.loc[0,'Score'])
按照模型需要的数据输入新客户的信息,根据各分段分数即可计算出新客户信用分了,如以上数据计算出来分数是:613。
六、结语
到此,【综合案例】一共完成了3篇:信用卡虚拟交易识别、网络贷款违约预测及本文信用评分模型开发。这三篇可以来说是比较典型的案例了,其涉及的知识点也比较广泛。大家如果想要相关的数据及代码的话可以到我的资源上去下载或者私信,然后可以对照文章中的解析或者自己深入探索其中的意思。
最后的最后,大家如果觉得文章不错的话,记得点赞、收藏、关注三连~
后记
自3月时拾起python至今,断断续续地学习数据分析大概有半年的时间了。从开始的基础知识学习,到后来的模型学习、分类算法学习,再到如今的综合案例分析,也算是一步一个脚印了。虽然并没有取得什么成就,但是在学习过程之中多多少少还是有些许收获。
不过由于个人时间的安排,所以就在10.24暂时画下句号,以后有空再来![]()