Python数据分析基础——数据预处理方法笔记(持续更新)
python数据预处理方法目录
- 一、数据探索
-
- 1.1 查看表总体信息
- 1.2 查看表细节信息
- 二、数据清洗
-
- 2.1 重复值处理
- 2.2 缺失值处理
- 2.3 异常值处理
- 2.4 提取字符串
- 2.5 数据离散化
- 2.6 数据标准化
- 2.7 数据整合
- 三、数据类型的转换
-
- 3.1 时间类型数据处理
- 3.2 字符串类型数据处理
- 四、特征构造
-
- 4.1 时间特征
-
- 4.1.1 提取年月日等
- 4.1.2 构造时间
- 4.1.3 计算时间间隔
- 4.1.4 判断是否为:工作日/节假日/调休日/星期几
一、数据探索
1.1 查看表总体信息
data.dtypes # 展示各字段及其数据类型
data.info() # 比dtypes多一列,还可展示各字段数据量
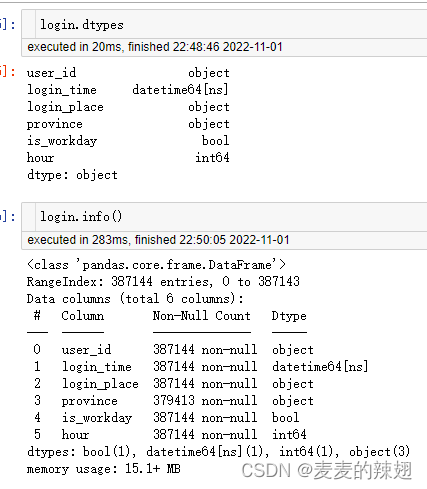
1.2 查看表细节信息
# 查看数据框形状大小
data.shape
# 查看表的所有列名
data.columns
# 查看表的索引
data.index
# 查看各字段数据大小、均值、标准差、最小值、上四分位点、中间值、下四分位点、最大值
data.describe()
二、数据清洗
2.1 重复值处理
- 探索数据框中的重复值情况;
- 根据实际情况决定是否删除;
- 删除方式:删除完全重复的数据或指定情况进行部分删除。
'————第一步:探索重复数据————'
# 探索完全相同的行数据
data.duplicated().sum()
'————第二步:处理缺失数据(删除)————'
# 删除所有字段完全相同的数据
data.drop_duplicates()
# 若有n条重复数据,保留最后一条重复数据
data.drop_duplicates(keep='last')
# 按照指定字段去重
# 单列
data.drop_duplicates(subset='列名1',inplace=True)
# 多列
data.drop_duplicates(subset=['列名1','列名2'],inplace=True) # inplace=True在原数据上删除
2.2 缺失值处理
- 探索数据框中的缺失值情况;
- 根据实际情况决定如何处理:不处理、删除、填补、插值
'————第一步:探索缺失数据————'
# 统计每一列字段缺失值的个数
data.isnull().sum()
# 统计每列字段缺失比例
data.apply(lambda x: str(round(sum(x.isnull())/len(x)*100,2))+'%' , axis= 0)
'————第二步:处理缺失数据————'
'————删除————'
# 默认删除只要存在一个缺失值的行
data.dropna()
# 删除所有元素都是缺失值的列
data.dropna(axis=1,how='all') # any:只要有缺失,就删除这一行
# 指定字段删除缺失值
data.dropna(subset=['字段名'],axis=0)
'————填补————'
# 指定值填补
data['列名'] = data['列名'].fillna('填补的数据')
# 均值填补
data['列名'] = data['列名'].fillna(data['列名'].mean())
# 中位数填补
data['列名'] = data['列名'].fillna(data['列名'].median())
# 众数填补
data['列名'] = data['列名'].fillna(data['列名'].mode()[0])
# 指定多列同时填补
data.fillna(value = {'第一列_众数' :某列.mode ()[0],'第二列_均值':某列.mean()})
# 用后一个数据填补
data.fillna(method='backfill')
# 用前一个数据填补
data.fillna(method='pad')
'————插值————'
# 线性等距插值:用缺失值上下值的平均值填充
data['列名'] = data['列名'].fillna(data['列名'].interpolate())
# 连续插值:选用前一个值来填充
data['列名'] = data['列名'].fillna(data['列名'].interpolate(method="pad"))
2.3 异常值处理
- 异常值处理没有固定流程,对于每个项目来说异常值的判定标准都不一样,有可能是时间数据2022-11-1变成了–,也有可能是表中年龄存在200岁等;
- 简单查看:①可通过Excel的–数据筛选–快速查看是否有异常值;②python中的value_counts();③箱线图;
- 处理:筛选出异常值后按实际情况删除or替换即可。
'————探索异常数据————'
# 展现数据情况
data['列名'].value_counts()
# 箱线图
import matplotlib.pyplot as plt
plt.boxplot(data['列名'])
plt.show()
2.4 提取字符串
- 只提取中文内容
data['列名'] = data['列名'].str.replace(r'[^\u4e00-\u9fa5]','')
- replace提取目标字符串(将非目标字符全部替换为空)
适合字符串中含有复杂符号的情况,如:'[ ] \
# 将不要的字符替换为空
data['列名'] = data['列名'].apply(lambda x:x.replace('不要的字符',''))
# 若一次替换完成不了,可多次replace
data['列名'] = data['列名'].apply(lambda x:x.replace('不要的字符','').replace('不要的字符',''))
- str提取目标字符串(适合简单情况,字符串位置可数)
# 单个
data['列名'] = data['列名'].str[7]
# 多个(切片)
data['列名'] = data['列名'].str[0:2]
2.5 数据离散化
2.6 数据标准化
2.7 数据整合
三、数据类型的转换
3.1 时间类型数据处理
- Pandas中使用to_datetime()方法将文本格式转换为日期格式
- 对于时间差数据,可以使用timedelta函数将其转换为指定时间单位的数值
'————转换为时间数据————'
# 最简单转换
data['列名'] = pd.to_datetime(data['列名'])
# format设置时间格式
data['列名'] = pd.to_datetime(data['列名'], format='%Y%m%d')
3.2 字符串类型数据处理
- 以下字符串函数只能对字符型变量进行使用
- 通过str方法访问相关属性
|函数|说明 |
|–|–|
| replace | 替换字符串 |
| lower | 所有字母都转为小写 |
| upper | 所有字母都转为大写|
| split | 返回字符串中的单词列表 |
| strip | 删除前导和后置空格 |
| join | 可连接字符串 |
# 用逗号分隔此字段数据,用于文本处理
data['列名'].str.split(',')
# 计算字符串长度
data['列名'].str.len()
# 显示前3行
data['列名'].head(3)
# 转换为float数据
data['列名'] = data['列名'].astype(float)
四、特征构造
4.1 时间特征
4.1.1 提取年月日等
- 当数据类型为datetime64时,可用dt方法提取出时间特征:年月日等
data['年'] = data['日期'].dt.year
data['月'] = data['日期'].dt.month
data['日'] = data['日期'].dt.day
data['季度'] = data['日期'].dt.quarter
data['星期几'] = data['日期'].dt.dayofweek
data['周次'] = data['日期'].dt.week
data['时'] = data['日期'].dt.hour
data['分'] = data['日期'].dt.minute
data['秒'] = data['日期'].dt.second
4.1.2 构造时间
- 构造时间,利用datetime模块中的timedelta类。timedelta类一定要结合date类的对象 或 datetime类的对象使用。也就是说,一定是基于这两个类的对象,进行时间的加、减。
(1)date类主要是用于处理年、月、日的,因此对该对象进行时间的加、减,主要是做“日(天数)”的加减;
(2)datetime类主要是用于处理年、月、日、时、分、秒、毫秒、微妙的,因此对该对象进行时间的加、减,主要做“日(天数)”、“时”、“分”、“秒”、“毫秒”、“微秒”、的加减;
(3)time类对象不支持。
'————date用法————'
# 定义date对象
day = date(2022,11,12)
# 昨天
yesterday = day + timedelta(days=-1)
# 明天
tomorrow = day + timedelta(days=1)
print('昨天:',yesterday)
print('明天:',tomorrow)
————————————————————————————————
Output:
昨天: 2022-11-11
明天: 2022-11-13
'————datetime用法————'
# 定义datetime对象
day = datetime(2022,11,12,23,59,59)
# 昨天
yesterday = day + timedelta(days=-1)
# 明天
tomorrow = day + timedelta(days=1)
# 上一个小时
last_hour = day + timedelta(hours=-1)
# 下一个小时
next_hour = day + timedelta(hours=1)
# 上一秒
last_m = day + timedelta(seconds=-1)
# 下一秒
next_m = day + timedelta(seconds=1)
print('昨天:',yesterday)
print('明天:',tomorrow)
print('上一个小时:',last_hour)
print('下一个小时:',next_hour)
print('上一秒:',last_m)
print('下一秒:',next_m)
————————————————————————————————
Output:
昨天: 2022-11-11 23:59:59
明天: 2022-11-13 23:59:59
上一个小时: 2022-11-12 22:59:59
下一个小时: 2022-11-13 00:59:59
上一秒: 2022-11-12 23:59:58
下一秒: 2022-11-13 00:00:00
4.1.3 计算时间间隔
- 计算两个日期的时间间隔,基于date类型、datetime类型数据。
# 提取间隔天数
(tomorrow - yesterday).days
————————————————————————————————
Output:
2
4.1.4 判断是否为:工作日/节假日/调休日/星期几
调用chinese_calendar库中的is_workday、is_holiday、is_in_lieu模块,判断目标日期是否为工作日、节假日、调休日。返回的是一个布尔值。
import datetime
from chinese_calendar import is_workday # 判断是否为工作日
from chinese_calendar import is_holiday # 判断是否为节假日
from chinese_calendar import is_in_lieu # 判断是否为调休日
day = datetime(2022,11,12,23,59,59) # 11月12日是星期六
print(is_workday(day))
print(is_holiday(day))
print(is_in_lieu(day))
————————————————————————————————
Output:
False
True
False
date和datetime类型都可用weekday方法判断目标日期是星期几。0~6分别对应星期一至星期天。
# 11月12日是星期六
day = datetime(2022,11,12,23,59,59)
day.weekday()
————————————————————————————————
Output:
5