离群点检测方法_密度聚类算法——离群点检测
离群点检测
1 离群点检测基本知识
离群点检测是数据挖掘中的一项重要内容,Hawkins最早给出了异常点离群点或孤立点的本质性定义异常点如此不同于数据集中的其它数据,以致于使人怀疑这些数据并非随机偏差,而是产生于完全不同的机制。离群点产生的原因可能多种多样,比如由于度量或执行错误产生的,或者由于固有数据变异产生的,或其它原因。检测离群点可以提高聚类精度。离群点检测的基本思想是从给定的包含个数据对象的数据集中发现与其他数据相比具有显著不同的数据。离群点检测算法大致分为基于统计的方法、基于距离的方法、基于密度的方法与基于偏离的方法。检测算法主要有两个过程,即离群点定义与离群点挖掘。虽然离群点检测只是为了发现数据集中少部分异常数据,但是对于人们发现有价值的知识很有意义。离群点检测方法可以分为以下几类。
(1)基于统计的离群点检测。基于统计分布的离群点检测方法是通过对小概率事件的判别来实现离群点的检测。其基本思想是通过对给定的数据集假设一个分布或概率模型,然后根据假设的模型通过不一致性测试来识别离群点。这种方法简便易行,但该方法在很大程度上依赖于待挖掘的数据集是否满足某种概率分布模型,而这个假设模型的参数、离群点的数目等是需要很多先验知识来确定的。此外,这种方法大多只适合于挖掘单变量的数值型数据。
(2)基于距离的离群点检测。基于距离的离群点检测方法把数据集看作高维空间,把数据看作高维空间中的点,定义离群点为与数据集中大多数点之间的距离大于某个阂值的点。基于距离的离群点检测算法有种基于索引的算法、基于单元的算法、嵌套一循环算法。基于索引的算法具有良好的可伸缩性,但是算法依赖索引结构的性能,维数的增加使得索引结构的性能下降。基于单元的离群点检测是将数据集划分为多个单元,化对象检测为单元检测。该算法具有很好的可伸缩性和可扩展性,但是需要将数据空间分隔成独立的单元结构,参数的每个变化都需要调整单元结构。嵌套一循环算法可以避免构建索引结构,并使最小化。基于距离的方法不必假设数据集的分布模型、数据特点等,克服了基于统计方法仅能检测单个属性,以及对先验知识需求很多的特点。
(3)基于密度的离群点检测。基于统计和基于距离的离群点检测方法对于非均匀分布的数据集不能得到很好的检测效果,因为这两种方法都依赖于给定数据集的全局分布,然而数据通常并非是均匀分布的。基于密度的方法是在基于距离的方法上改进而来,能够检测出基于距离检测所不能发现的局部离群点。LOF(Local Outlier Factor)是Breunig等人提出的基于局部离群因子的离群点检测算法。数据中每个对象的异常程度用局部离群因子LOF来衡量。LOF首先产生所有点的K-邻域及K最近邻距离,并计算点到其中每个点的距离,然后计算每个点的局部离群因子,并根据局部离群因子挖掘局部离群点。
(4)基于偏移的离群点检测。基于偏移的检测算法是通过检查一组对象的主要特征来识别离群点。目前基于偏移的离群点主要有两种顺序异常技术与OLAP数据立方体技术。但是这种方法要事确定数据的主要特征,在应用中不太实际,所以实际问题中很少使用。
2 基于LOF的离群点检测方法
因为各种原因,数据中往往存在一些离群点,为了提高聚类精度引入基于密度的离群点检测方法。算法中为每个对象定义一个局部离群因子,对于离群点的判定转化为对离群因子的判定,Breunig在文献中提出了一种基于密度的局部离群点检测方法LOF。此处,利用其方法定义离群因子,离群因子的定义中有下列定义。


图3.1 连接距离




(3.1)

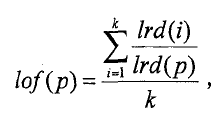
(3.2)

对于密度分布均匀的数据集,簇中点的离群点因子值在1附近。对于数据集中的离群点,因其局部密度远远小于其邻域的局部密度,使得其离群点因子较大,从而可以从离群点因子分辨离群点。如图3.2,(a)为一组二维数据集,其中有两个均匀分布的簇,两个簇的密度不等,(b)为数据集1各点离群因子,可以看出各个数据点的离群因子分布在1附近。(c)为一组二维数据集,其中有两个高斯分布的簇以及一些离群点,两个簇的紧凑程度不一样。数据集2各点离群点因子如(d)所示,从图中可以看出簇的紧凑区域,簇中各点离群因子在1附近,对于高斯分布的簇中少数稀疏区域的离群因子超过了2,对于离群点或稀疏点的离群因子大多都大于2,从离群因子的值可以得到离群点的判断。
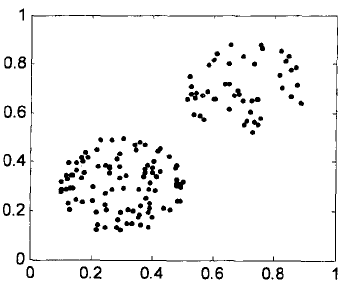
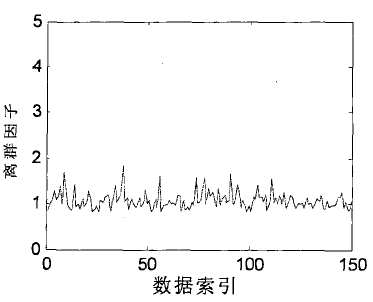
a)数据集1 b)离群因子曲线1
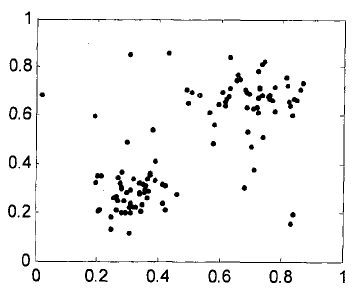

c)数据集2 d)离群因子曲线2
图3.2 数据集的离群因子
《来源科技文献,经本人分析整理,以技术会友,广交天下朋友》