PyTorch学习记录(十)关于CIFAR-10的一些学习笔记
前言
在B站中看完了《PyTorch深度学习实践》完结合集——刘二大人前11个视频,想来自己动手实践试试,边实践边学习。
首先复习一下
一般我们主要有以下几个步骤:
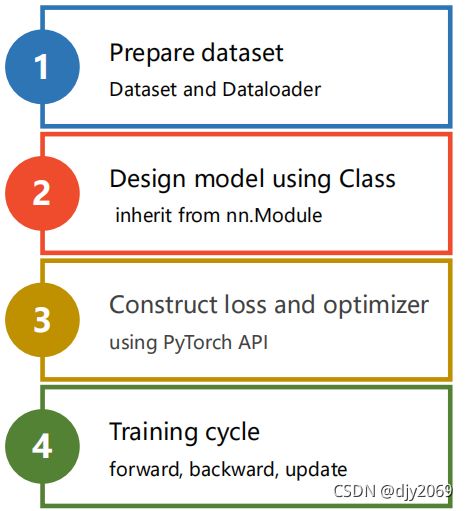
(一)prepare dataset
在这个步骤中,我们首先需要用到torchvision
1、torchvision:包含了流行的数据集、模型架构和用于计算机视觉的常见图像转换。
(1)torchvision.datasets(数据):MNIST、Fashion-MNIST、COCO、LSUN、ImageFolder、Imagenet-12、CIFAR、STL10SVHN、PhotoTour
(2)torchvision.models(模型):Alexnet、VGG、ResNet、SqueezeNet、DenseNet、Inception v3
(3)torchvision.transforms(数据转换):Transforms on PIL Image、Transforms on torch.*Tensor、Conversion Transforms、Generic Transforms
(4)torchvision.utils(实用工具)
在torchvision的文档中,我们可以看到关于CIFAR的内容:
https://pytorch.org/docs/0.3.0/torchvision/datasets.html#cifar
在pytorch中读图像时用的是python的PIL(pillow),神经网络在处理pillow读进来的图像的时候,它希望输入数值较小、在(-1,1)之间且遵从正态分布,故需要将它转换为图像张量。
- 所以我们首先需要利用torchvision来完成这个转换:
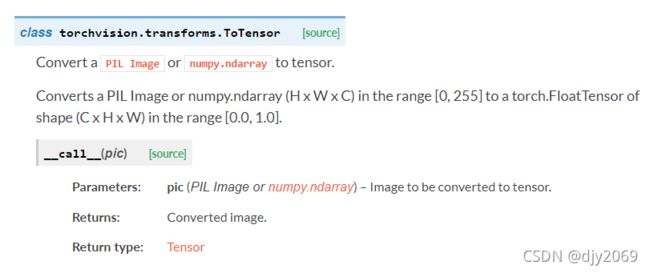
将 [0, 255] 范围内的 PIL Image 或 numpy.ndarray (H x W x C) 转换为 [0.0, 1.0] 范围内形状 (C x H x W) 的 torch.FloatTensor。
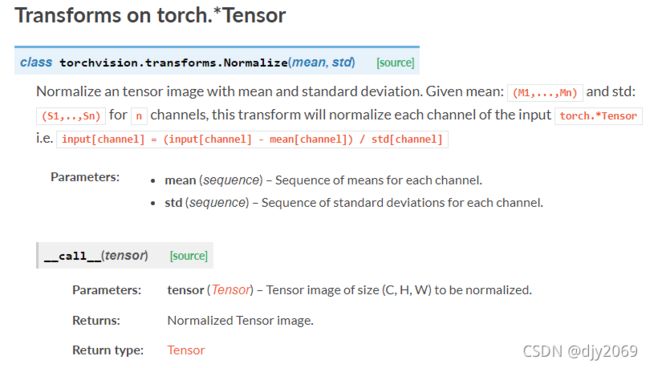
使用均值和标准差对张量图像进行归一化。由于这里的参数需要使用到均值、标准差,故我们需要先根据数据集来获得均值和方差。
这篇文章中提供了一个简单计算数据标准差和均值的接口,方便大家使用。
pytorch学习 | 如何统计数据集的均值和标准差?——qyhyzard
def get_mean_std(dataset, ratio=0.01):
"""Get mean and std by sample ratio
"""
dataloader = torch.utils.data.DataLoader(dataset, batch_size=int(len(dataset) * ratio),
shuffle=True, num_workers=0)
train = iter(dataloader).next()[0] # 一个batch的数据
mean = np.mean(train.numpy(), axis=(0, 2, 3))
std = np.std(train.numpy(), axis=(0, 2, 3))
return mean, std
# cifar10
train_dataset = torchvision.datasets.CIFAR10('./data',
train=True, download=True,
transform=transforms.ToTensor())
test_dataset = torchvision.datasets.CIFAR10('./data',
train=False, download=True,
transform=transforms.ToTensor())
train_mean, train_std = get_mean_std(train_dataset)
test_mean, test_std = get_mean_std(test_dataset)
print(train_mean, train_std)
print(test_mean, test_std)
能够得到:
训练集的均值和方差为:[0.48836562 0.48134598 0.4451678 ]、 [0.24833508 0.24547848 0.26617324]
测试集的均值和方差为:[0.47375134 0.47303376 0.42989072] 、[0.25467148 0.25240466 0.26900575]
得到数据之后我们就可以使用transforms.ToTensor()和transforms.Normalize()来完成转换。
- 其次,需要将数据集加载进来。
Dataset和DataLoader都是用于加载数据的重要工具类。

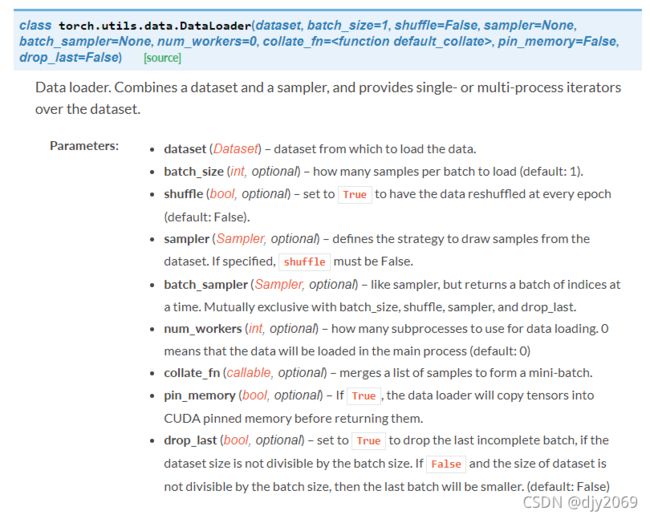
DataLoader:数据加载器。组合数据集和采样器,并在数据集上提供单进程或多进程迭代器。简单来说就是用来帮助我们加载数据的,可以实例化DataLoader来帮助我们做这些工作。
shuffle=True 即打乱样本顺序。
- 最后,定义类别

故第一部分的代码为:
batch_size = 64
transform_train = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.48836562, 0.48134598, 0.4451678), (0.24833508, 0.24547848, 0.26617324))
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.47375134, 0.47303376, 0.42989072), (0.25467148, 0.25240466, 0.26900575))
])
train_dataset = datasets.CIFAR10(root='../dataset/mnist/',
train=True,
download=True,
transform=transform_train)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset = datasets.CIFAR10(root='../dataset/mnist/',
train=False,
download=True,
transform=transform_test)
test_loader = DataLoader(train_dataset,
shuffle=False,
batch_size=batch_size)
classes = ('airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
(二)Design model using Class
在这里我直接使用了我上一个笔记,也就是课程《PyTorch深度学习实践》完结合集_11. 卷积神经网络(高级篇)里的一个模型。

由于这个和MNIST输入通道数不同,只需要把conv1的输入通道改成3,再相应地修改最后的线性层即可。
class ResidualBlock(torch.nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = torch.nn.Conv2d(channels, channels,
kernel_size=3, padding=1)
self.conv2 = torch.nn.Conv2d(channels, channels,
kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x + y)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(3, 16, kernel_size=5)
self.conv2 = torch.nn.Conv2d(16, 32, kernel_size=5)
self.mp = torch.nn.MaxPool2d(2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.fc = torch.nn.Linear(512, 10)
def forward(self, x):
in_size = x.size(0)
x = self.mp(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
model = Net()
(三)Construct loss and optimizer
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.5)
(四)Training cycle and test
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss:%.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
前馈+反馈+更新
列出其中比较重要的函数、操作:

官方文档:https://docs.python.org/zh-cn/3.8/library/functions.html?highlight=enumerate#enumerate
在官网的tutorial中,为了好玩,展示了一些训练图像。
这里重写了imshow()
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()

官方文档:https://matplotlib.org/stable/api/_as_gen/matplotlib.pyplot.imshow.html?highlight=imshow#matplotlib.pyplot.imshow
将数据在 2D 常规栅格上显示为图像。 输入可以是实际的 RGB(A) 数据,也可以是 2D 标量数据,这些数据将被渲染为伪彩色图像。
# get some random training images
dataiter = iter(test_loader)
images, labels = dataiter.next()
# show images
imshow(torchvision.utils.make_grid(images))
# print labels
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(batch_size)))
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
# print predicted
print('predicted:', ' '.join('%5s' % classes[predicted[j]] for j in range(batch_size)))

官方文档:https://docs.python.org/zh-cn/3.8/library/functions.html?highlight=iter#iter
返回一个迭代器对象。
如果没有第二个参数,object 必须是支持迭代协议(iter() 方法)的集合对象,或者它必须支持序列协议(getitem() 方法,整数参数从 0 开始)。如果它不支持这些协议中的任何一个,则会引发 TypeError。如果给出了第二个参数 sentinel,则 object 必须是一个可调用对象。在这种情况下创建的迭代器将在每次调用其 next() 方法时调用不带参数的对象;如果返回的值等于 sentinel,则将引发 StopIteration,否则将返回该值。

官方文档:https://pytorch.org/docs/0.3.0/torchvision/utils.html
制作图像网格
Tensor:形状为(B x C x H x W)的 4D 小批量张量或所有相同大小的图像列表。
' '.join()
是指用空格来连接内容
现在来测试网络在整个数据集上的表现:
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set:%d %%' % (100 * correct / total))

官方文档:https://pytorch.org/docs/0.3.0/torch.html#comparison-ops
返回给定维度 dim 中输入 Tensor 每一行的最大值。第二个返回值是找到的每个最大值的索引位置 (argmax)。
注意:dim (int) – the dimension to reduce,即要减少的维度
例如,dim=0, 则我们按列来查找,找到每列的最大值后,我们得到的是一个(1,4)的Tensor,那么我们减少的维度是行(dim=0)。若dim=1,则我们按行来查找,找到每行的最大值后,我们得到了一个(4,1)的Tensor,那么我们减少的维度就是列(dim=1)。
测试网络在各个数据集上的表现:
correct_pred = {classname: 0 for classname in classes}
total_pred = {classname: 0 for classname in classes}
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predictions = torch.max(outputs, dim=1)
for label, prediction in zip(labels, predictions):
if label == prediction:
correct_pred[classes[label]] += 1
total_pred[classes[label]] += 1
for classname, correct_count in correct_pred.items():
accuracy = 100 * float(correct_count) / total_pred[classname]
print("Accuracy for class {:5s} is: {:.1f}%".format(classname, accuracy))
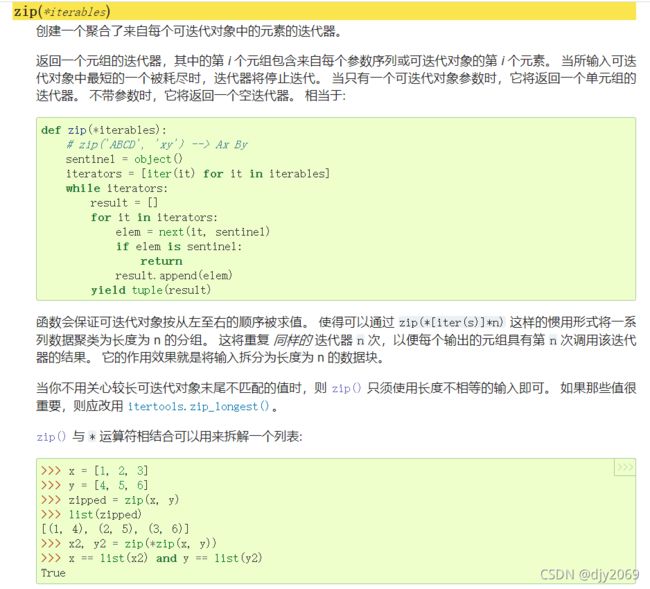
官方文档:https://docs.python.org/zh-cn/3.8/library/functions.html?highlight=enumerate#zip
完整代码
import numpy as np
import torch
import torchvision.utils
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
batch_size = 4
transform_train = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.48836562, 0.48134598, 0.4451678), (0.24833508, 0.24547848, 0.26617324))
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.47375134, 0.47303376, 0.42989072), (0.25467148, 0.25240466, 0.26900575))
])
train_dataset = datasets.CIFAR10(root='./data',
train=True,
download=True,
transform=transform_train)
train_loader = DataLoader(train_dataset,
shuffle=True,
batch_size=batch_size,
num_workers=2)
test_dataset = datasets.CIFAR10(root='./data',
train=False,
download=True,
transform=transform_test)
test_loader = DataLoader(train_dataset,
shuffle=False,
batch_size=batch_size,
num_workers=2)
classes = ('airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
class ResidualBlock(torch.nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.conv1 = torch.nn.Conv2d(channels, channels,
kernel_size=3, padding=1)
self.conv2 = torch.nn.Conv2d(channels, channels,
kernel_size=3, padding=1)
def forward(self, x):
y = F.relu(self.conv1(x))
y = self.conv2(y)
return F.relu(x + y)
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(3, 16, kernel_size=5)
self.conv2 = torch.nn.Conv2d(16, 32, kernel_size=5)
self.mp = torch.nn.MaxPool2d(2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(32)
self.fc = torch.nn.Linear(800, 10)
def forward(self, x):
in_size = x.size(0)
x = self.mp(F.relu(self.conv1(x)))
x = self.rblock1(x)
x = self.mp(F.relu(self.conv2(x)))
x = self.rblock2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
model = Net()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss:%.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
# functions to show an image
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
def test():
# # get some random training images
# dataiter = iter(test_loader)
# images, labels = dataiter.next()
#
# # show images
# imshow(torchvision.utils.make_grid(images))
# # print labels
# print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(batch_size)))
#
# outputs = model(images)
# _, predicted = torch.max(outputs.data, 1)
# # print predicted
# print('predicted:', ' '.join('%5s' % classes[predicted[j]] for j in range(batch_size)))
# 测试网络在每个种类数据集上的表现
correct = 0
total = 0
correct_pred = {classname: 0 for classname in classes}
total_pred = {classname: 0 for classname in classes}
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predictions = torch.max(outputs, dim=1)
total += labels.size(0)
correct += (predictions == labels).sum().item()
for label, prediction in zip(labels, predictions):
if label == prediction:
correct_pred[classes[label]] += 1
total_pred[classes[label]] += 1
for classname, correct_count in correct_pred.items():
accuracy = 100 * float(correct_count) / total_pred[classname]
print("Accuracy for class {:5s} is: {:.1f}%".format(classname, accuracy))
print('Accuracy on test set:%d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(20):
train(epoch)
test()